










记录使用Docker容器跑通2021CVPR小样本目标检测DCNet
DCNet
一、拉取镜像
- 执行
docker pull gouchicao/maskrcnn-benchmark拉取镜像,等待下载完毕 - 执行
docker images可以查看有哪些镜像 - 执行如下进行实例化容器,其中
/media/E_4TB/YL/datasets/voc和/media/E_4TB/YL/FSOD/code/DCNet分别为voc数据目录(该目录下含VOC2007和VOC2012等文件夹)和代码的根目录,-v是目录挂载,-p是将服务器4000端口映射到容器22端口, --shm-size 16G 为允许的内存大小
返回如下docker run --gpus all --shm-size 16G -v /media/E_4TB/YL/datasets/voc:/workspace/data/pascal_voc -v /media/E_4TB/YL/FSOD/code/DCNet:/workspace/code/Meta-FSOD -it -d -p 4000:22 gouchicao/maskrcnn-benchmark bash

- 执行docker exec -it 36c bash,36c为容器id前几位
- 设置密码,安装vim等
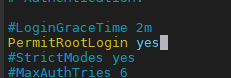
更改sshd_config如下图passwd # 更改密码 apt-get update apt-get install openssh-server # 安装ssh apt-get install openssh-client # 安装ssh apt-get install vim # 安装vim vim /etc/ssh/sshd_config # 将PermitRootLogin去掉注释 并将prohibit-password改为yes,如后面图所示 /etc/init.d/ssh restart # 重新启动ssh systemctl enable ssh 设置自启动
现在就可以通过ssh root@192.168.0.202 -p 4000 访问容器了,其中ip改为服务器ip
二、vscode调试
2.1 配置
-
安装远程控制插件

-
连接
ctrl+shift+p
输入remote-ssh,选Add New SSH Host

-
填写远程服务器用户名及ip地址, 如ssh intleo21@192.168.0.202 -p 4000
-
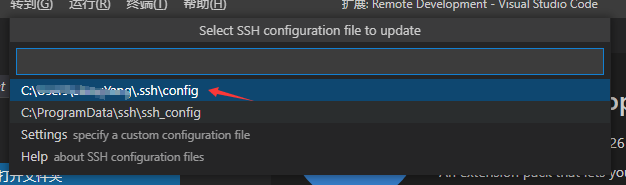
选择配置保存位置,第一个就可以
-
创建连接

-
新弹出一个界面,选择目标主机系统类型

-
等待远程服务器安装完,打开远程文件夹目录
/workspace/code/META-FSOD -
安装python插件

-
选择远程环境

-
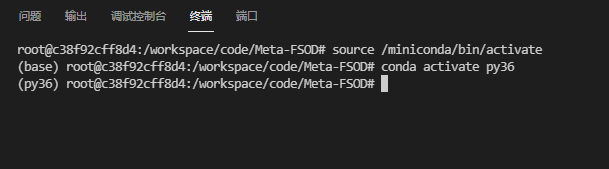
打开终端

下面弹出如下,并自动激活环境
2.2 安装DCN
2.2.1 安装cityscapesScripts
cd /git clone https://github.com/mcordts/cityscapesScripts.gitcd cityscapesScripts/vi setup.py将这一块改成下图,源代码中没有encoding=“utf-8”

- python setup.py build_ext install
2.2.2 安装DCNet
cd /workspace/code/Meta-FSOD- 如有,执行
rm -rf build/删除build文件夹 - 执行
python setup.py build develop安装 - 执行
ln -s /workspace/data/pascal_voc datasets/voc链接存储 - 执行
bash tools/fewshot_exp/datasets/init_fs_dataset_standard.sh
2.2.3 安装其它依赖
pip install scikit-image
2.3 运行
按照README.md进行跑就行了,但官方的运行方案会存在路径问题
可参考以下
cd /workspace/code/Meta-FSODvi experiments/DRDbash base_train.sh
更改为如下
#!/bin/bash
# ROOT=../..
# export PYTHONPATH=$ROOT:$PYTHONPATH
export CUDA_VISIBLE_DEVICES=0,1
export NGPUS=2
SPLIT=(1 2 3)
for split in ${SPLIT[*]}
do
configfile=experiments/DRD/configs/base/e2e_voc_split${split}_base.yaml
python -m torch.distributed.launch --nproc_per_node=$NGPUS --master_port 29512 tools/train_net.py --config-file ${configfile} 2>&1 | tee logs/log_${split}_basetrain.txt
mv model_final.pth model_voc_split${split}_base.pth
mv inference/voc_2007_test_split${split}_base/result.txt fs_exp/result_split${split}_base.txt
rm last_checkpoint
python tools/fewshot_exp/trans_voc_pretrained.py ${split}
done
- 执行
bash experiments/DRD/base_train.sh训练 - 如有警告
uint8已弃用, 将ctrl+shift+r将torch.uint8全局替换为torch.bool
正在运行界面

其它
将容器生成为镜像,下次直接执行生成的镜像,34c为容器id
docker commit 34e dcnet
docker start dcn
docker exec dcnet /etc/init.d/ssh start
然后ssh连接
源码分析记录
更改了GeneralizedRCNN类,即建立总模型的类
- build_backbone函数调用build_resnet_fpn_backbone函数再调了ResNet类,ResNet更改了forward以及调用的stem_module中调用的StemWithFixedBatchNorm调用的BaseStem更改了
训练数据集
调试配置文件为
{
"name": "train base sp1",
"type": "python",
"request": "launch",
"program": "/miniconda/envs/py36/lib/python3.6/site-packages/torch/distributed/launch.py",
"console": "integratedTerminal",
"env": {"CUDA_VISIBLE_DEVICES":"0,1,2,3"},
"args": ["--node_rank=4", "--master_port", "29512", "./tools/train_net.py",
"--config-file", "experiments/DRD/configs/base/e2e_voc_split1_base.yaml"]
}
以e2e_voc_split1_base为例
创建两个data_loader和meta_loader
-
data_loader
dataset_list为 [‘voc_2007_trainval_split1_base’,‘voc_2012_trainval_split1_base’]
datasets类为 maskrcnn_benchmark.data.datasets.voc.PascalVOCDataset
第一个数据集文件为’datasets/voc/VOC2007/ImageSets/Main/trainval_split1_base.txt’ 数量为3888(15个类别)
getitem一次一个 -
meta_loader
dataset_list为[‘voc_meta_trainval_split1_base’]
datasets类为maskrcnn_benchmark.data.datasets.voc_meta.PascalVOCDataset_Meta 参数为 ‘shots’:200; ‘size’:256;
metafile ‘/workspace/code/Meta-FSOD/fs_list/voc_traindict_full.txt’ 里面包含的是20个类别的训练文件,例如飞机是aeroplane /workspace/data/pascal_voc/voclist/aeroplane_train.txt
生成metalines列表,列表长度为15,列表中每个元素都是一个长度为shots(200个)的列表,列表中是图像路径,由metafile内确定,例如飞机的两百个样本由/workspace/data/pascal_voc/voclist/aeroplane_train.txt中随机两百行确定
self.ids 是长度为200的列表,列表中每个元素都是一个长度为15的列表,内容即metalines,相当于15个类,每类一张样本
getitem 一次取ids的一个元素,即15张图像,每张图像会与mask合并,
训练过程是开启了apex混合精度,相关知识查阅该链接,如以后出现apex或amp导包失败,可将以下两块代码注释更改,即可取消使用混合精度
注释模型amp初始化
model, optimizer = amp.initialize(model, optimizer, opt_level='O1')
将
with amp.scale_loss(loss, optimizer) as scaled_loss:
scaled_loss.backward()
改为
loss.backward()















 2044
2044











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









