







逻辑回归(LR)解决的不是回归,而是分类问题。
核心思想:线性回归中出现的值通过sigmoid= 11+e-z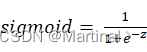 转化到(0,1)之间,通过判断输出与0.5(z=0)的关系来做二分类。(时间复杂度O(nd),d为特征维数)
转化到(0,1)之间,通过判断输出与0.5(z=0)的关系来做二分类。(时间复杂度O(nd),d为特征维数)
(线性回归:y=wTx+b =>![]() 线性回归:logistic= 11+e-wTx+b
线性回归:logistic= 11+e-wTx+b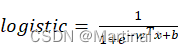 <即带入y值至sigmoid函数即可>)
<即带入y值至sigmoid函数即可>)
- sigmoid函数可以减少线性回归中极端点(偏差过大点)的影响
- sigmoid函数的取值为(0,1),因此贴合概率模型
- sigmoid是神经网络的重要基础之一
- 逻辑回归函数求导即为g'z= gz*(1-g(z))
 用于梯度下降法求解。
用于梯度下降法求解。
代码:
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
import numpy as np
import pandas as pd
if __name__ == '__main__':
df_data = pd.read_csv('./merge_data.csv',header=None)
df =df_data
df.columns = ['id', 'expiration_id', 'src_ip',
'src_mac', 'src_oui', 'src_port',
'dst_ip', 'dst_mac', 'dst_oui',
'dst_port', 'protocol', 'ip_version',
'vlan_id', 'tunnel_id', 'bidirectional_first_seen_ms',
'bidirectional_last_seen_ms', 'bidirectional_duration_ms', 'bidirectional_packets',
'bidirectional_bytes', 'src2dst_first_seen_ms', 'src2dst_last_seen_ms',
'src2dst_duration_ms', 'src2dst_packets', 'src2dst_bytes',
'dst2src_first_seen_ms', 'dst2src_last_seen_ms', 'dst2src_duration_ms',
'dst2src_packets', 'dst2src_bytes', 'bidirectional_min_ps',
'bidirectional_mean_ps', 'bidirectional_stddev_ps', 'bidirectional_max_ps',
'src2dst_min_ps', 'src2dst_mean_ps', 'src2dst_stddev_ps',
'src2dst_max_ps', 'dst2src_min_ps', 'dst2src_mean_ps',
'dst2src_stddev_ps', 'dst2src_max_ps', 'bidirectional_min_piat_ms',
'bidirectional_mean_piat_ms', 'bidirectional_stddev_piat_ms',
'bidirectional_max_piat_ms',
'src2dst_min_piat_ms', 'src2dst_mean_piat_ms', 'src2dst_stddev_piat_ms',
'src2dst_max_piat_ms', 'dst2src_min_piat_ms', 'dst2src_mean_piat_ms',
'dst2src_stddev_piat_ms', 'dst2src_max_piat_ms', 'bidirectional_syn_packets',
'bidirectional_cwr_packets', 'bidirectional_ece_packets', 'bidirectional_urg_packets',
'bidirectional_ack_packets', 'bidirectional_psh_packets', 'bidirectional_rst_packets',
'bidirectional_fin_packets', 'src2dst_syn_packets', 'src2dst_cwr_packets',
'src2dst_ece_packets', 'src2dst_urg_packets', 'src2dst_ack_packets',
'src2dst_psh_packets', 'src2dst_rst_packets', 'src2dst_fin_packets',
'dst2src_syn_packets', 'dst2src_cwr_packets', 'dst2src_ece_packets',
'dst2src_urg_packets', 'dst2src_ack_packets', 'dst2src_psh_packets',
'dst2src_rst_packets', 'dst2src_fin_packets', 'application_name',
'application_category_name', 'application_is_guessed', 'application_confidence',
'requested_server_name', 'client_fingerprint', 'server_fingerprint', 'user_agent',
'content_type', 'label']
df = df.drop(['id', 'expiration_id', 'src_ip',
'src_mac', 'src_oui', 'src_port',
'dst_ip', 'dst_mac', 'dst_oui',
'dst_port', 'protocol', 'ip_version',
'vlan_id', 'tunnel_id', 'bidirectional_first_seen_ms',
'bidirectional_last_seen_ms', 'src2dst_first_seen_ms', 'src2dst_last_seen_ms',
'dst2src_first_seen_ms', 'dst2src_last_seen_ms', 'bidirectional_min_piat_ms',
'bidirectional_mean_piat_ms',
'bidirectional_max_piat_ms',
'src2dst_min_piat_ms', 'src2dst_mean_piat_ms',
'src2dst_max_piat_ms', 'dst2src_min_piat_ms', 'dst2src_mean_piat_ms',
'dst2src_max_piat_ms', 'application_name',
'application_category_name', 'application_is_guessed', 'application_confidence',
'requested_server_name', 'client_fingerprint', 'server_fingerprint', 'user_agent',
'content_type'], axis=1)
labels = np.array(df['label'][1:])
labels = labels.astype('int')
df = df.drop(['label'],axis=1)
df = df[1:]
df = np.array(df)
train_sample,test_sample,train_label,test_label =train_test_split(df,labels,test_size=0.3,random_state=11)
"""注意正则化影响损失函数优化算法:L1正则化的损失函数不是连续可导的,而{‘newton-cg’, ‘lbfgs’,‘sag’}
这三种优化算法时都需要损失函数的一阶或者二阶连续导数。而‘liblinear’并没有这个依赖。"""
model1 = LogisticRegression(penalty='l1',C=0.5,max_iter=100,solver="liblinear")
model2 = LogisticRegression(penalty='l2',C=0.5,max_iter=100,solver="liblinear")
model1.fit(train_sample,train_label)
model2.fit(train_sample, train_label)
true = test_label.tolist()
predict1 = model1.predict(test_sample)
predict2 = model2.predict(test_sample)
print(classification_report(y_true=true,y_pred=predict1))
print(classification_report(y_true=true, y_pred=predict2))逻辑回归的损失函数:损失函数一般定义为预测值和真实值的差(预测值拟合真实分布的好坏),而逻辑回归中的损失函数等同于最大似然函数(交叉熵)。
交叉熵:可以从两个角度理解

(y代表真实值,y拔代表预测值)
(1)从对数似然函数理解
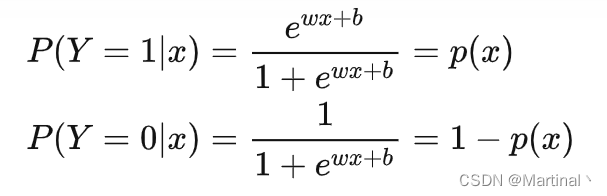
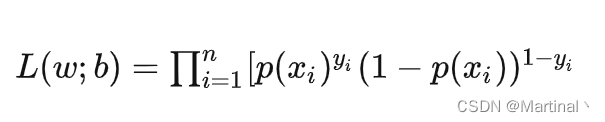
上述式子是所有事件的总概率,由sigmoid推导得来,取ln即可得到对数似然函数。通过最大化似然函数来求解参数w和b。
(2)从信息论的角度理解
KL散度用于衡量两个分布之间的差异:
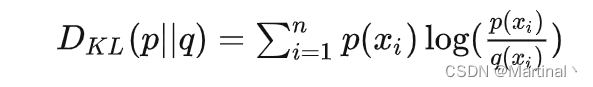
展开KL散度得:

q为预测分布,则可得KL散度=交叉熵-真实分布的信息熵,又真实分布的信息熵是常数,故交叉熵越小即可。
交叉熵的优点是比均方误差学习速度快,有利于梯度下降迭代,尤其是模型效果差的时候;模型效果好时会变慢。
缺点:标准的交叉熵损失确实一直都只利用了每个样本正确类别的信息,错误类别的信息并未充分利用。采用了类间竞争机制,比较擅长于学习类间的信息,但是只关心对于正确标签预测概率的准确性,而忽略了其他非正确标签的差异,从而导致学习到的特征比较散。
梯度下降法:求解损失函数的极小值,也就是通过损失函数导函数值找到函数下降的方向直到找到最低点(极值点)。
逻辑回归的优化办法:
1. 解决过拟合:
(1)减少特征
(2)正则化:L1(数据稀疏)、L2(其他)
2. 损失函数:
选择随机梯度下降、批梯度下降等
逻辑回归的优点:
(1)计算量只与特征有关,高效
(2)可解释性强,从特征的w权重可看到不同特征对结果的影响
(3)二分类效果好
(4)内存占用小,只需要存储特征值
逻辑回归的缺点:
(1)由于是基于线性回归的,不能解决非线性问题(决策面是线性的)
(2)不同类别数据如果多重共线性,模型较为敏感
(3)很难处理不平衡数据(模型优化目标是最小化模型在训练集上的平均损失。具体而言,逻辑回归采用的最大后验概率的策略,他的目标是使得训练集总体的后验概率最大,因此这种算法天然地会将关注点更多地放在多数类的拟合情况下。)
(4)准确率不高,线性模型难以拟合真实分布(欠拟合)
(5)无法筛选特征(可使用GBDT筛选)
(6)不适用于多分类
(7)特征维数过多时不好,不能学习特征间的非线性关系
-----------------------------------------------------------
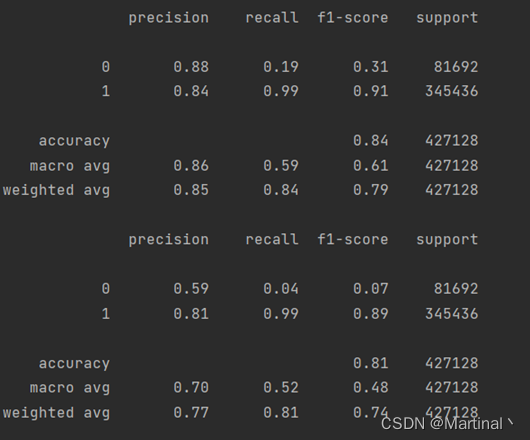
跑的速度还行:43维特征,100多万条数据
大概20多秒,结果分别是L1和L2正则化的,另外L2正则化结果和非正则一致。















 540
540











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









