







逻辑回归(Logistic Regression)总结
在分类问题中,要预测的变量y是离散的值,便会用到逻辑回归。例如:
·判断邮件是否垃圾邮件
·肿瘤是恶性还是良性
·判断一次金融交易是否欺诈
……


决策边界(decision boundary)
并且参数? 是向量[-3 1 1]。 则当−3 + ?1 + ?2 ≥ 0,即?1 + ?2 ≥ 3时,模型将预测 ? =
1。 我们可以绘制直线?1 + ?2 = 3,这条线便是我们模型的分界线,将预测为 1 的区域和预测为 0 的区域分隔开。
需要用曲线才能分隔 ? = 0 的区域和 ? = 1 的区域,我们需要二次方特征:
ℎ?(?) = ?(?0 + ?1?1 + ?2?2 + ?3(?1)² + ?4(?2)²)是[-1 0 0 1 1],则我们得到的判定边界恰好是圆点在原点且半径为 1 的圆形。

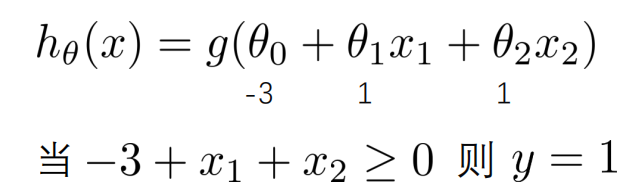


我们可以用非常复杂的模型来适应非常复杂形状的判定边界。
逻辑回归的代价函数
线性回归的代价函数为:
重新定义逻辑回归的代价函数为
使用梯度下降算法来求得能使代价函数最小的参数
将过程用数学公式表达
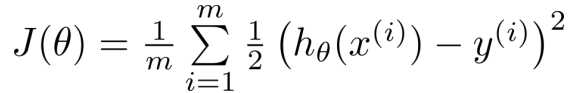
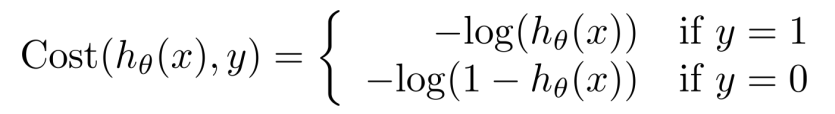




逻辑回归的多类别分类:一对多
举例1:我们希望收到的邮件可以自动归类到不同的文件夹里,或者自动地加上标签,这样一来便需要不同的文件夹或标签来完成这项任务,区分来自工作、朋友、家人、兴趣爱好有关的邮件等,一个分类问题便诞生:类别有4个分别用y=1,y=2,y=3,y=4代表.
举例2:一个病人因为鼻塞来到诊所,他可能并没有生病,y=1代表没有生病,可能是感冒,用y=2代表,也可能是流感,用y=3代表。
举例3:项目要求区分哪些天气是晴天、多云、雨天、下雪天,对上述所有的例子,y就可以取值0,1,2,3……来代表对应不同的天气情况。
二分类和多分类的问题对比:
对于右图的多分类,使用逻辑回归,将数据集一分为二分为正类和父类。利用一对多的思想解决。直接用图说明过程
最后在需要做预测时,将所有分类及都运行一遍,然后对每一个输入变量,都选择最高可能性的输出变量。


逻辑回归的正则化
简单的说,正则化是改善或减少过拟合问题的一项技术。
注:看上去与正则化的线性回归一样,但因为hθ(x)的不同,所以两者还是存在很大差别。
















 885
885











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









