







线性分类器
-
数据集介绍

-
核心流程图

-
图像类型:二进制图,灰度图,彩色图

二进制图像:图像的每一个像素值都是非0及1,非黑即白
灰度图像:图像的每一像素值都是0-255之间的值
彩色图像:RGB表示 -
图像表示
必要性:

转换方法:
[R1,G1,B1,R2,G2,B2,R3,G3,B3]^T 三元组 -
线性分类器
- 定义

每个类的参数w和b初始值是随意设置的,通过反向传播使得参数w和参数b得到更新。
Wi的函数等于类别数。
- 线性分类器决策

- 线性分类器示例
图像表示成向量
计算当前图像每个类别的分数
按得分高低得出相应结论

参数梳理&CIFAR10举例


线性分类器的权值向量的物理理解
权值向量可以理解为数据的统计信息,一种数据的模板,“平均值”


线性分类器的决策边界

以二维平面为例,权值矩阵相当于y=ax+b的a控制着线的方向,b控制线的偏移,线性分类器尝试将二维平面中的样本簇以线的方式进行划分,由此带来的缺陷—线性不可分区域 注意二维平面到高维平面的映射。二维线,三维面 etc。
-
损失函数
求解分类最优

- 损失函数的定义

作用:(1)度量给定分类器的预测值和真实值的不一致程度(2)作为反馈信号对分类器参数进行调整,降低当前示例对应的损失值。

Eg: 多类支撑向量机损失

若某一样本(比如说样本是猫)对于该样本是猫的得分比该样本是其他类别的得分高出1分,则没有损失。
计算举例:

- 正则项

对于是某一样本的损失均为零的两个权值矩阵

如何进行选择?

R(w)可以控制权值的分布(以L2正则项举例)

超参数

常见的正则项损失:
- 参数优化
定义

说白了就是你的权值矩阵和偏移量不够好,要改!
方法一:直接法
我们考虑一般函数的极值点一定是导数等于0的那些点,所以直接求解。

方法二:
梯度下降算法



学习率*梯度也就是 dx × 斜率
那么 如何计算梯度? 数值法,解析法(高中数学水平)



问题 我们注意梯度计算公式
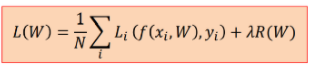
对于每一个训练样本都要算他的梯度,然后进行1/N操作,而我们从初始权值求解最优权值的过程中可能要进行多次迭代,这样每次涉及全部样本的操作耗时!计算量巨大!

解决方法:随机梯度下降算法 统计学思路,当迭代次数足够多的时候,频率接近概率。我们每次只随机选择一个样本计算梯度,并以此梯度,代替样本的平均梯度。虽然有些样本会带来噪声,但是当迭代次数足够多的时候,总会朝着样本的平均趋势前进

折中:小批量随机梯度下降算法

- 数据集划分
传统划分:训练集+测试集。问题:诸如正则项等超参数的引入,超参数是你在测试集之前就应该准备好的,你不能用训练集训练超参数,测试集选取最优超参数-----引入验证集。


解决数据较少时的方法:K折交叉验证


10. 数据预处理
去均值:不让最大和最小数据差距过大,减去平均值。
归一化:每个维度的数据分布一致,打个比方值域都是 [0,1]。保持量纲一致。
去相关:一定的降维,让数据能够独立出来。(白化 神经网络不常用)















 4396
4396











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









