







目标检测


对于单目标检测来说,总体上的思路将损失函数分为两部分,一部分损失用来识别目标是什么,另一部分用来识别目标的位置是什么。所以你的样本得表示目标是什么以及目标的位置在哪里。
那多目标检测怎么办??图片里的目标个数都不一样,你这个网络根本不知道输出什么维度。

对于多目标检测来说,一种可行的手段是利用CNN判断该窗口里的图案具体是什么。

一个显著的问题,什么区域,哪些区域,多少个区域?

R-CNN
一种方法,区域建议,我建议给你多少个区域

思想:基于颜色、纹理、大小和形状计算区域相似度,并形成分层分组。
详细解释:https://blog.csdn.net/weixin_41665360/article/details/97957039

SS之后用卷积进行特征提取,然后用SVM进行分类。
Bbox Reg边界盒回归,SS提取的区域是红色框框部分,真实的是蓝色部分,回归。

参考:https://blog.csdn.net/zijin0802034/article/details/77685438

慢速R-CNN是怎么操作的,我先选择了感兴趣的区域,然后在在这个区域上进行卷积操作,你这个区域进行特征提取很可能就给我重复计算特征了!

Fast R-CNN 对整张图做一次全卷积,然后在特征响应图上进行感兴趣区域提取。不用重复计算特征了!
回顾目标检测的任务:检测出目标&把这个物体用框框框起来。
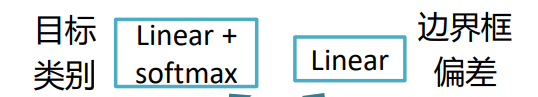
所以这里会有两个偏差。

区域裁剪,将候选区域投影到特征图上,这里将区域顶点规整到网格交点上,所以会存在轻微对不齐的情况。
双线性差值


四个点的贡献全部计算一下。汇聚到Fxy。
都经过2×2最大池化,不管你区域选择的区域有多大,最后都是2×2,向量一样长大家都可以接同一个全连接神经网络了

问题:候选区域实在是太耗时间了

对一张图片进行128次卷积核的卷积得到了一个特征响应图(feature map),然后在每一个像素点,弄若干个anchor。怎么判断anchor框住的区域是不是有效的区域呢?用LOU!然后在这么多anchor中选择前几百个丢尽FC里分类




参考:https://zhuanlan.zhihu.com/p/27988828
这种两阶段的目标检测耗时所在是区域建议局域的选择,那我自己选择区域好不好?

YOLO就是把一张图分成7*7个区域,每个区域辅以anchor然后我对这些区域进行目标检测&边界框回归。

使得回归函数看到某一个特征以后就知道图像哪里偏了,应该做什么变换。

一个目标由好多个框框怎么办?
NMS(Non-maximum suppression),即非极大值抑制,在目标检测中的出镜率也很高呀。在目标检测中,不论是最初的region proposal,还是后来的anchor box,不可避免的一个问题就是对于同一个物体,会预测出多个bounding box,如下左图所示。而NMS所做的就是去除掉多余的bounding box,只保留和ground truth重叠度最高的bounding box,如下右图所示。
























 540
540











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









