







一、概述
官网:http://kafka.apache.org/

Kafka是什么?
Apache Kafka是一个分布式的 流数据 平台; 三层含义:
- 消息系统(MQ): 发布和订阅流数据
- 流数据处理(Streaming): 可以基于Kakfa开发流数据处理的应用,用以实时处理流数据
- 流数据存储(Store): 以一种安全分布式、冗余、容错的方式,存放流数据;
Kafka的典型应用场景(Kafka有什么用)?
- 构建实时的流数据管道,用以在应用和系统之间进行可靠的数据传输
- 构建实时的流数据处理应用,用以传输或者处理流数据
- 作为流数据处理框架(Storm、Spark、Flink等)的数据源
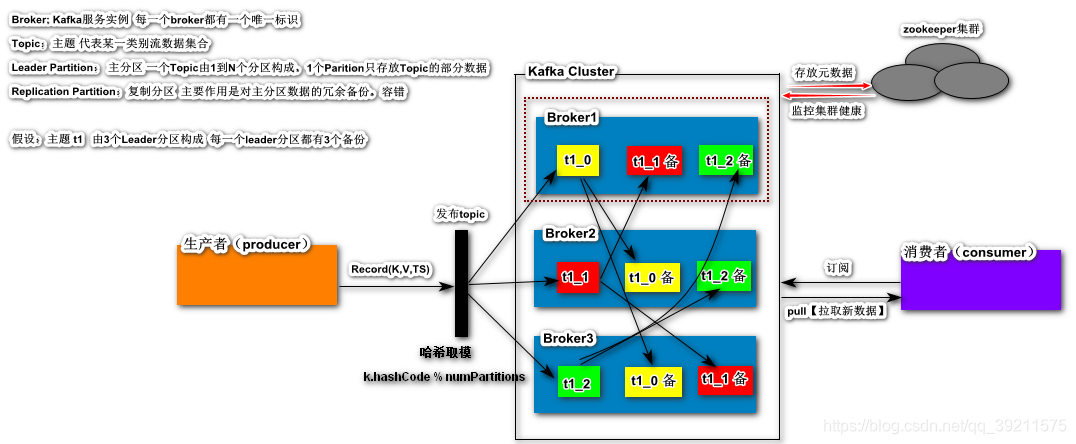
术语介绍:
-
Broker(代理人 中间人)
- Kafka集群包含一个或多个服务器,这种服务器被称为broker
- 是Kafka的一个服务实例,每一个Broker都有一个唯一的标识(Broker_ID)
-
Topic(主题)
- 每条发布到Kafka集群的消息都有一个类别,这个类别被称为Topic。
- 代表每一类别数据的集合 (存储一类数据)
-
Partition(分区)
- Partition是物理上的概念,每个Topic包含一个或多个Partition.
- 主分区:存储Topic的一部分数据,一个Topic有1-N个分区
- 副本分区:和主分区存储内容一致,备份、实现容错
-
Producer(生产者)
- 负责发布消息到Kafka broker
-
Producer(生产者)
- 消息消费者,向Kafka broker读取消息的客户端。
-
Consumer Group(消费组)
- 每个Consumer属于一个特定的Consumer Group 可为每个Consumer指定group name,若不指定group name则属于默认的group
- 同组负载均衡,不同组广播
Kafka的架构
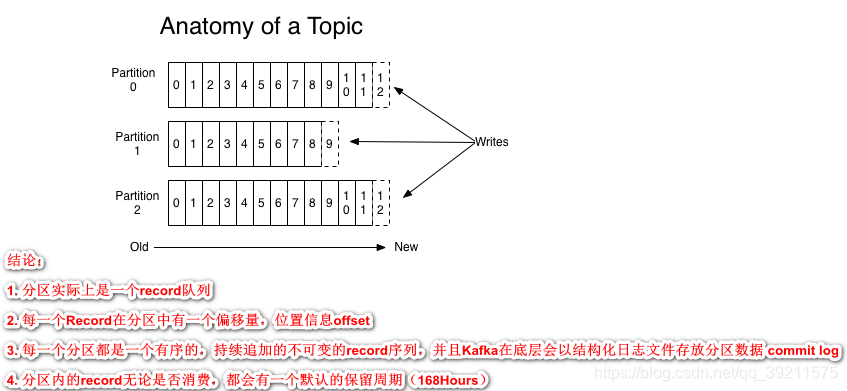
剖析Kafka Topic(主题)
读写消费位置
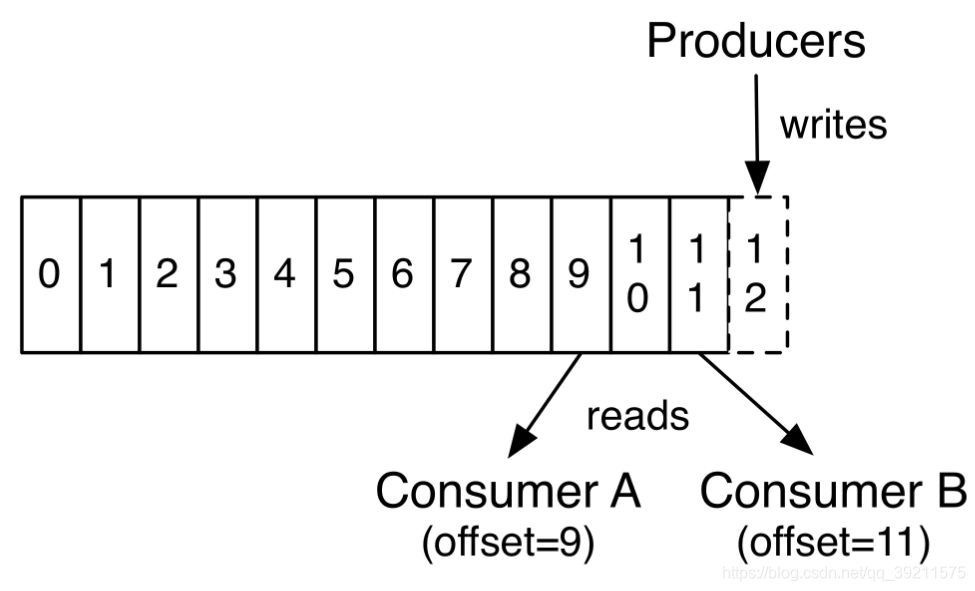
对于每一个消费者,都会维护一个消费位置offset(自己消费的位置信息)
消费组
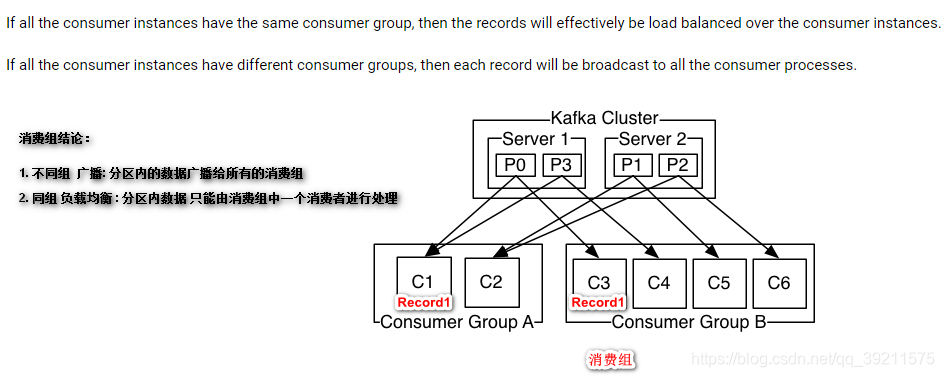
不同组 :广播,分区内的数据广播给所有的消费组
同组 :负载均衡,一个分区只能被消费组中的一个消费实例消费
Kafka集群环境搭建
准备工作
- 有三个节点
- JDK8.0+ 环境
- 同步集群时钟
- ZooKeeper集群服务健康
1.上传安装包
2.解压安装
3.配置:
vi config/server.properties
broker.id=0
# 服务实例ID必须唯一比如下面的配置
# node02:1
# node03: 2
#服务器的地址
listeners=PLAINTEXT://node01:9092
# node02: PLAINTEXT://node02:9092
# node03: PLAINTEXT://node03:9092
#数据存放目录 默认为/tmp(临时文件夹)下不安全
log.dirs=/data/kafka
#服务器列表
zookeeper.connect=node01:2181,node02:2181,node03:2181
4.启动
#-daemon表示以后台/守护进程的方式启动
bin/kafka-server-start.sh -daemon config/server.properties
jps
----------------------------------------------------------
7585 Jps
9346 DFSZKFailoverController
8885 NameNode
9004 DataNode
1500 QuorumPeerMain
7357 Kafka #看到Kafka的进程就启动成功了!
9197 JournalNode
Kafka的命令操作
topic(主题)相关
- 创建主题
bin/kafka-topics.sh
--create
--bootstrap-server
HadoopNode01:9092,HadoopNode02:9092,HadoopNode03:9092
--topic t1
--partitions 3
--replication-factor 3
--------------------------------------------------------------
#创建
#kafka集群列表
#主题名
#分区数
#分区副本数
--------------------------------------------------------------
表示创建t1 topic,
由3个leader 主分区构成,
每一个分区除过本身由两个冗余备份;
- 展示所有(主题)
bin/kafka-topics.sh
--list
--bootstrap-server
HadoopNode01:9092,HadoopNode02:9092,HadoopNode03:9092
--------------------------------------------------------------
t1
--------------------------------------------------------------
#展示所有的主题
#kafka集群列表
- 删除主题
bin/kafka-topics.sh
--delete
--bootstrap-server
HadoopNode01:9092,HadoopNode02:9092,HadoopNode03:9092
--topic t1
--------------------------------------------------------------
#删除主题
#kafka集群列表
#指定主题名
- 修改主题的主分区的数量
bin/kafka-topics.sh
--alter
--bootstrap-server
HadoopNode01:9092,HadoopNode02:9092,HadoopNode03:9092
--topic t1 --partitions 5
--------------------------------------------------------------
#修改
#kafka集群列表
#指定主题名bin/kafka-topics.sh
--alter
--bootstrap-server
HadoopNode01:9092,HadoopNode02:9092,HadoopNode03:9092
--topic t1 --partitions 5
--------------------------------------------------------------
#修改
#kafka集群列表
#指定主题名
- 修改复制因子
bin/kafka-reassign-partitions.sh
--zookeeper
HadoopNode01:2181,HadoopNode02:2181,HadoopNode03:2181
--reassignment-json-file
/usr/kafka_2.11-2.2.0/config/change-replication-factor.json
--execute
------------------------------------------------------------
// json文件内容如下
{
"partitions":
[
{
"topic": "t2",
"partition": 0,
"replicas": [1,2,0]
},
{
"topic": "t2",
"partition": 1,
"replicas": [0,2,1]
},
{
"topic": "t2",
"partition": 2,
"replicas": [0,1,2]
}
],
"version":1
}
- 主题的描述
bin/kafka-topics.sh
--describe
--bootstrap-server
HadoopNode01:9092,HadoopNode02:9092,HadoopNode03:9092
--topic t1
--------------------------------------------------------------
Topic:t1 PartitionCount:5 ReplicationFactor:3 Configs:segment.bytes=1073741824
Topic: t1 Partition: 0 Leader: 0 Replicas: 0,2,1 Isr: 0,2,1
Topic: t1 Partition: 1 Leader: 2 Replicas: 2,1,0 Isr: 2,1,0
Topic: t1 Partition: 2 Leader: 1 Replicas: 1,0,2 Isr: 1,0,2
Topic: t1 Partition: 3 Leader: 0 Replicas: 0,2,1 Isr: 0,2,1
Topic: t1 Partition: 4 Leader: 1 Replicas: 1,0,2 Isr: 1,0,2
--------------------------------------------------------------
#描述
#kafka集群列表
#指定主题名
描述某一个topic 的详细信息
Leader、Replicas、Isr : Broker ID
Partition: 分区序号
注意:
t1 topic 第一个分区 broker id=0(HadoopNode01)组织管理 t1 topic 第二个分区
broker id=2(HadoopNode03)组织管理如: 当broker id = 2 节点服务 杀死, 第二个分区(p1)故障转移【在Broker id = 1 or id = 0
的这两个服务实例中的某一个复制分区升级为主分区】
- 订阅(subscribe)主题
bin/kafka-console-consumer.sh
--topic t1
--bootstrap-server
node01:9092,node02:9092,node03:9092
--property
print.timestamp=true
print.key=true
---------------------------------------------------
CreateTime:1577091996206 Hello Kafka
CreateTime:1577092057070 Hello Hadoop
- 发布(publish)主题
bin/kafka-console-producer.sh
--broker-list
HadoopNode01:9092,HadoopNode02:9092,HadoopNode03:9092
--topic t1
---------------------------------------------------
>Hello Kafka
>
注意:
基于控制台的生产者:recorde key = null
Kafka的JAVA API操作
1.导入依赖
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>2.2.0</version>
</dependency>
生产者API(重点)
// 生产者的配置信息
Properties prop = new Properties();
prop.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "HadoopNode01:9092,HadoopNode02:9092,HadoopNode03:9092");
prop.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
prop.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
// record k v 泛型
KafkaProducer<String, String> producer = new KafkaProducer<String, String>(prop);
// 通过生产者发布消息
ProducerRecord<String, String> record = new ProducerRecord<String, String>("t2", "user002", "xz");
producer.send(record);
producer.flush();
// 释放资源
producer.close();
消费者API(重点)
// 配置对象
Properties prop = new Properties();
prop.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "node01:9092,node02:9092,node03:9092");
prop.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
prop.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
// prop.put(ConsumerConfig.GROUP_ID_CONFIG, "g1"); // 消费组 不同组广播 同组负载均衡
prop.put(ConsumerConfig.GROUP_ID_CONFIG, "g2"); // 消费组 不同组广播 同组负载均衡
// 消费者对象
KafkaConsumer<String, String> consumer = new KafkaConsumer<String, String>(prop);
// 订阅主题
consumer.subscribe(Arrays.asList("t2"));
// 循环拉取t2 topic中新增数据
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofSeconds(5));
records.forEach(record -> {
System.out.println(
record.key()
+ "\t"
+ record.value()
+ "\t"
+ record.timestamp()
+ "\t"
+ record.offset()
+ "\t"
+ record.partition()
+ "\t"
+ record.topic()
);
});
}
Topic(主题)操作 API
Properties prop = new Properties();
prop.put(AdminClientConfig.BOOTSTRAP_SERVERS_CONFIG, "HadoopNode01:9092,HadoopNode02:9092,HadoopNode03:9092");
AdminClient adminClient = KafkaAdminClient.create(prop);
// 创建topic
/*
adminClient.createTopics(Arrays.asList(new NewTopic("t4", 3, (short) 3)));
*/
// 删除topic
/*
adminClient.deleteTopics(Arrays.asList("t4"));
*/
/*
// 展示所有(只展示用户创建的Topic列表)
ListTopicsResult topics = adminClient.listTopics();
KafkaFuture<Set<String>> names = topics.names();
Set<String> tNames = names.get();
tNames.forEach(name -> System.out.println(name));
*/
// 描述一个topic
/*
t2 (name=t2, internal=false, partitions=
(partition=0, leader=HadoopNode02:9092 (id: 1 rack: null), replicas=HadoopNode02:9092 (id: 1 rack: null), HadoopNode03:9092 (id: 2 rack: null), HadoopNode01:9092 (id: 0 rack: null), isr=HadoopNode02:9092 (id: 1 rack: null), HadoopNode03:9092 (id: 2 rack: null), HadoopNode01:9092 (id: 0 rack: null)),
(partition=1, leader=HadoopNode01:9092 (id: 0 rack: null), replicas=HadoopNode01:9092 (id: 0 rack: null), HadoopNode03:9092 (id: 2 rack: null), HadoopNode02:9092 (id: 1 rack: null), isr=HadoopNode01:9092 (id: 0 rack: null), HadoopNode03:9092 (id: 2 rack: null), HadoopNode02:9092 (id: 1 rack: null)),
(partition=2, leader=HadoopNode01:9092 (id: 0 rack: null), replicas=HadoopNode01:9092 (id: 0 rack: null), HadoopNode02:9092 (id: 1 rack: null), HadoopNode03:9092 (id: 2 rack: null), isr=HadoopNode01:9092 (id: 0 rack: null), HadoopNode02:9092 (id: 1 rack: null), HadoopNode03:9092 (id: 2 rack: null)))
*/
DescribeTopicsResult result = adminClient.describeTopics(Arrays.asList("t2"));
Map<String, KafkaFuture<TopicDescription>> map = result.values();
map.forEach((k, v) -> {
try {
System.out.println(k + "\t" + v.get());
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
}
});
adminClient.close();
Kafka的高级特性(面试问的挺多的)
消费组
用来组织管理消费者一个特性,同组负载均衡,不同组广播
生产者记录发布策略
- Record的Key不为空,使用哈希取模的发布策略(key.hashCode % numPartitions)
- Record的Key为空,使用轮询分区的发布策略
- 手动指定Record存储的分区序号
消费者消费方式
Kafka消费者订阅1个或者多个感兴趣Kafka Topic,当这些Topic有新的数据产生,消费者拉取最新的数据,然后进行相应的业务处理
- 只订阅(subscribe): 订阅1到N个Topic的所有分区
- 指定消费分区: 订阅某一个Topic的特定分区
- 手动指定分区消费位置: 每一个消费者维护一个消费信息(元数据,读位置offset)可以手动重置offset;这样做的目的可以重新消费已经处理过的数据或者跳过不感兴趣的数据
首次订阅 offset重置方式
Kafka消费者在第一次(首次)订阅某个Topic时
-
offset默认采用的重置方式为
latest(默认), 还有另外的一个方式earliest; -
latest: 如果当前分区有已提交的offset,从已提交的offset之后消费数据;如果没有提交的offset,则从最后(最新产生的数据)消费数据
-
earliest:如果当前分区有已提交的offset,从已提交的offset之后消费数据;如果没有提交的offset,则从分区的最前(开头)消费数据
-
kafka消费位置基于消费组管理,并且kafka使用一个特殊的Topic:Topic(__consumer_offsets),用以记录消费组对不同topic的消费位置。
-
__consumer_offsets 由50个主分区构成,复制因子1,是一个系统topic
Kafka消费者的offset的提交方式
Kafka消费者的offset有两种提交方法,一种自动提交(默认)和另一种手动提交(非默认)将当前消费组中消费者一个消费位置offset,提交保存到__consumer_offsets
- 自动提交(默认开启,5秒保存一次offset)
- 手动提交(生产环境用 确保Record被业务正确的处理了再提交offset)
生产者的批处理
Kafka生产者生成的记录Record,首先进行缓存,然后定期或者在缓存空间即满时,一次性将多条数据写入到kafka集群;
注意:批处理操作是一种kafka优化写的方法,对于资源的利用率更高,但是有一定数据延迟
开启方法:
//配置文件的形式
batch.size = 4096
linger.ms = 5000
//java API
prop.put(ProducerConfig.BATCH_SIZE_CONFIG,4096); // 4096 = 4kb 设定批处理操作缓存区大小
prop.put(ProducerConfig.LINGER_MS_CONFIG,2000); // 设定批处理操作 每一个批次逗留时间
// 两个条件满足其一即可
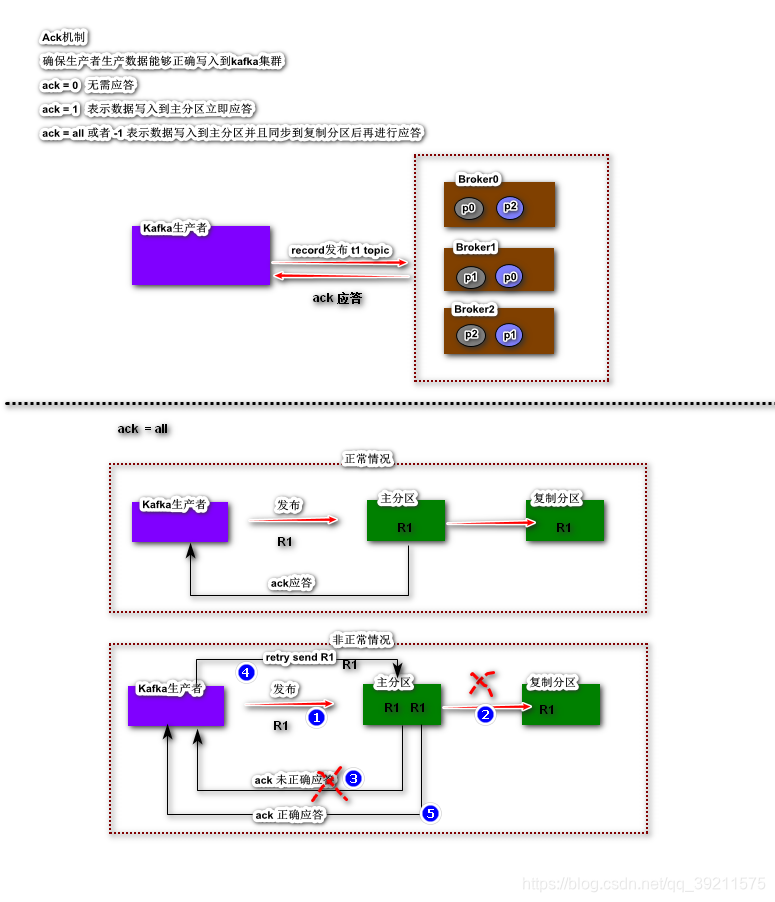
Ack & Retries机制
Kafka为了确保数据能够正确的写入到Kafka集群,提供了应答机制(Ack)
- ack = 0 无需应答
- ack = 1 表示数据写入到主分区立即应答 (默认)
- ack = all 或者 -1 表示数据写入到主分区并且同步到复制分区后再进行应答
因为Kakfa Ack机制存在,当生产者发布的一个数据在写入Kafka集群时
如果长时间未获得ack应答,进行retry重试操作,(默认重试次数是Integer.MAX_VALUE)
注意:
因为Kafka Retry机制存在有可能会导致Kafka集群存放多个相同数据;
如果要确保相同数据只保留一个,则需要开启Kafka幂等写操作
幂等写操作
幂等: 一次操作和多次操作影响的结果是一致的;
实现原理:
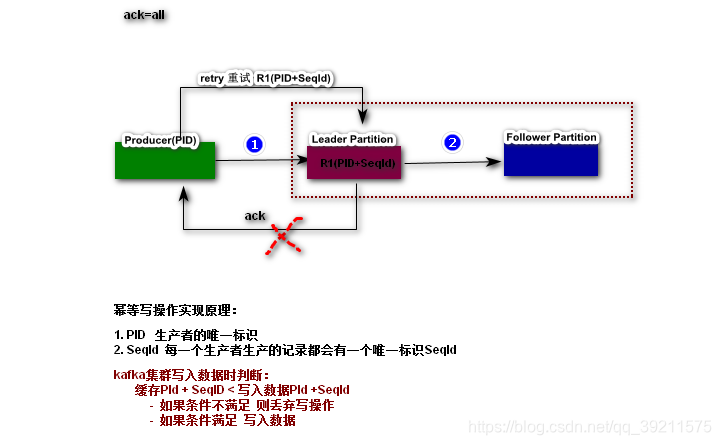
//开启幂等写
prop.put(ProducerConfig.ENABLE_IDEMPOTENCE_CONFIG, true);
SpringBoot集成Kafka
- 创建SpringBoot
- 添加kafka配置
#====================== kafka =========================
spring.kafka.bootstrap-servers=HadoopNode01:9092,HadoopNode02:9092,HadoopNode03:9092
spring.kafka.producer.key-serializer=org.apache.kafka.common.serialization.StringSerializer
spring.kafka.producer.value-serializer=org.apache.kafka.common.serialization.StringSerializer
spring.kafka.producer.acks=all
spring.kafka.producer.retries=10
spring.kafka.producer.batch-size=4096
spring.kafka.consumer.group-id=g1
spring.kafka.consumer.key-deserializer=org.apache.kafka.common.serialization.StringDeserializer
spring.kafka.consumer.value-deserializer=org.apache.kafka.common.serialization.StringDeserializer
生产者DEMO
@SpringBootTest
class KafkaSbApplicationTests {
/**
* 生产者demo
*/
@Autowired
private KafkaTemplate<String, String> kafkaTemplate;
@Test
void test1() {
ListenableFuture<SendResult<String, String>> future = kafkaTemplate.send("t3", "user00210", "xh210");
// 异步处理的结果对象
/*
future.addCallback(
new SuccessCallback<SendResult<String, String>>() {
@Override
public void onSuccess(SendResult<String, String> stringStringSendResult) {
System.out.println("发送成功!");
}
}, new FailureCallback() {
@Override
public void onFailure(Throwable throwable) {
System.out.println("发送失败!");
throwable.printStackTrace();
}
});
*/
// 函数式编程
future.addCallback(
(stringStringSendResult) -> {
System.out.println("发送成功!");
},
(t) -> {
System.out.println("发送失败!");
t.printStackTrace();
}
);
}
}
消费者DEMO
/**
* 消费者DEMO
*/
@KafkaListener(topics = "t3", groupId = "g1")
public void receive(ConsumerRecord<String, String> record) {
System.out.println(
record.key()
+ "\t"
+ record.value()
+ "\t"
+ record.timestamp()
+ "\t"
+ record.offset()
+ "\t"
+ record.partition()
+ "\t"
+ record.topic()
);
}
Kafka事务
事务指的一个原子操作(不可分割整体),要么同时成功,要么同时失败;
Kafka事务类似于DB事务,隔离级别只有两种:
- read_uncommitted (默认) 读未提交 毫无意义
- read_committed 读已提交,解决脏读
所谓的事务不过就是调用下面几个方法而已
// 初始化事务
producer.initTransactions()
// 开启事务
producer.beginTransaction()
// 提交事务
producer.commitTransaction()
// 取消事务
producer.abortTransaction()
// 发送事务偏移量信息
producer.sendOffsetsToTransaction
消费生产并存事务也称为 consume transfer produce
public class ConsumeTransferProduceTransaction {
public static void main(String[] args) {
KafkaProducer<String, String> kafkaProducer = bulidKafkaProducer();
KafkaConsumer<String, String> kafkaConsumer = bulidKafkaConsumer();
kafkaConsumer.subscribe(Arrays.asList("t5"));
kafkaProducer.initTransactions();
while (true) {
kafkaProducer.beginTransaction();
ConsumerRecords<String, String> consumerRecords = kafkaConsumer.poll(Duration.ofSeconds(5));
Map<TopicPartition, OffsetAndMetadata> map = new HashMap<>();
try {
consumerRecords.forEach(record -> {
System.out.println(record.key() + "\t" + record.value() + "\t" + record.offset());
// 模拟业务错误
/*
if ("xz".equals(record.value())) {
int m = 1 / 0;
}
*/
kafkaProducer.send(new ProducerRecord<String, String>("t6", record.key(), record.value() + "?"));
// 注意: 消费生产并存事务中,消费者的消费位置(offset),需要通过生产者sendOffsetsToTransaction方法提交
// 在map中存放消费者消费位置信息
TopicPartition key = new TopicPartition(record.topic(), record.partition());
OffsetAndMetadata value = new OffsetAndMetadata(record.offset() + 1);
map.put(key, value);
});
kafkaProducer.sendOffsetsToTransaction(map, "g1");
kafkaProducer.commitTransaction();
} catch (Exception e) {
kafkaProducer.abortTransaction();
}
}
}
public static KafkaProducer<String, String> bulidKafkaProducer() {
// 生产者的配置信息
Properties prop = new Properties();
prop.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "HadoopNode01:9092,HadoopNode02:9092,HadoopNode03:9092");
prop.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
prop.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
prop.put(ProducerConfig.ENABLE_IDEMPOTENCE_CONFIG, true); // 事务操作 需要开启幂等写操作支持
prop.put(ProducerConfig.TRANSACTIONAL_ID_CONFIG, UUID.randomUUID().toString());
KafkaProducer<String, String> kafkaProducer = new KafkaProducer<>(prop);
return kafkaProducer;
}
public static KafkaConsumer<String, String> bulidKafkaConsumer() {
// 配置对象
Properties prop = new Properties();
prop.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "HadoopNode01:9092,HadoopNode02:9092,HadoopNode03:9092");
prop.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
prop.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
prop.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, false); // 必须使用手动提交消费位置
prop.put(ConsumerConfig.GROUP_ID_CONFIG, "g1");
prop.put(ConsumerConfig.ISOLATION_LEVEL_CONFIG, "read_committed"); // 修改事务隔离界别 读已提交 不会脏读问题
prop.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");
// 消费者对象
KafkaConsumer<String, String> kafkaConsumer = new KafkaConsumer<String, String>(prop);
return kafkaConsumer;
}
}
Flume和Kafka整合
Kafka Source
从kafka中读取数据,作为flume数据采集的数据源
a1.sources.r1.type = org.apache.flume.source.kafka.KafkaSource
a1.sources.r1.batchSize = 5000
a1.sources.r1.batchDurationMillis = 2000
a1.sources.r1.kafka.bootstrap.servers = HadoopNode01:9092,HadoopNode02:9092,HadoopNode03:9092
a1.sources.r1.kafka.topics = t3
a1.sources.r1.kafka.consumer.group.id = g1
Kafka Channel
将flume采集的数据,临时存放在Kafka中
a1.channels.c1.type = org.apache.flume.channel.kafka.KafkaChannel
a1.channels.c1.kafka.bootstrap.servers = HadoopNode01:9092,HadoopNode02:9092,HadoopNode03:9092
a1.channels.c1.kafka.topic = flume_channel
a1.channels.c1.kafka.consumer.group.id = g1
Kakfa Sink【重点】
将flume采集的数据,输出存放在Kafka中
a1.sinks.k1.channel = c1
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k1.kafka.topic = mytopic
a1.sinks.k1.kafka.bootstrap.servers = HadoopNode01:9092,HadoopNode02:9092,HadoopNode03:9092
a1.sinks.k1.kafka.flumeBatchSize = 20
a1.sinks.k1.kafka.producer.acks = 1
a1.sinks.k1.kafka.producer.linger.ms = 1
a1.sinks.k1.kafka.producer.compression.type = snappy
Kafka MQ在企业中的应用
- 异步通信
- 异步解耦
- 流量削峰
- 日志收集
- 写缓存
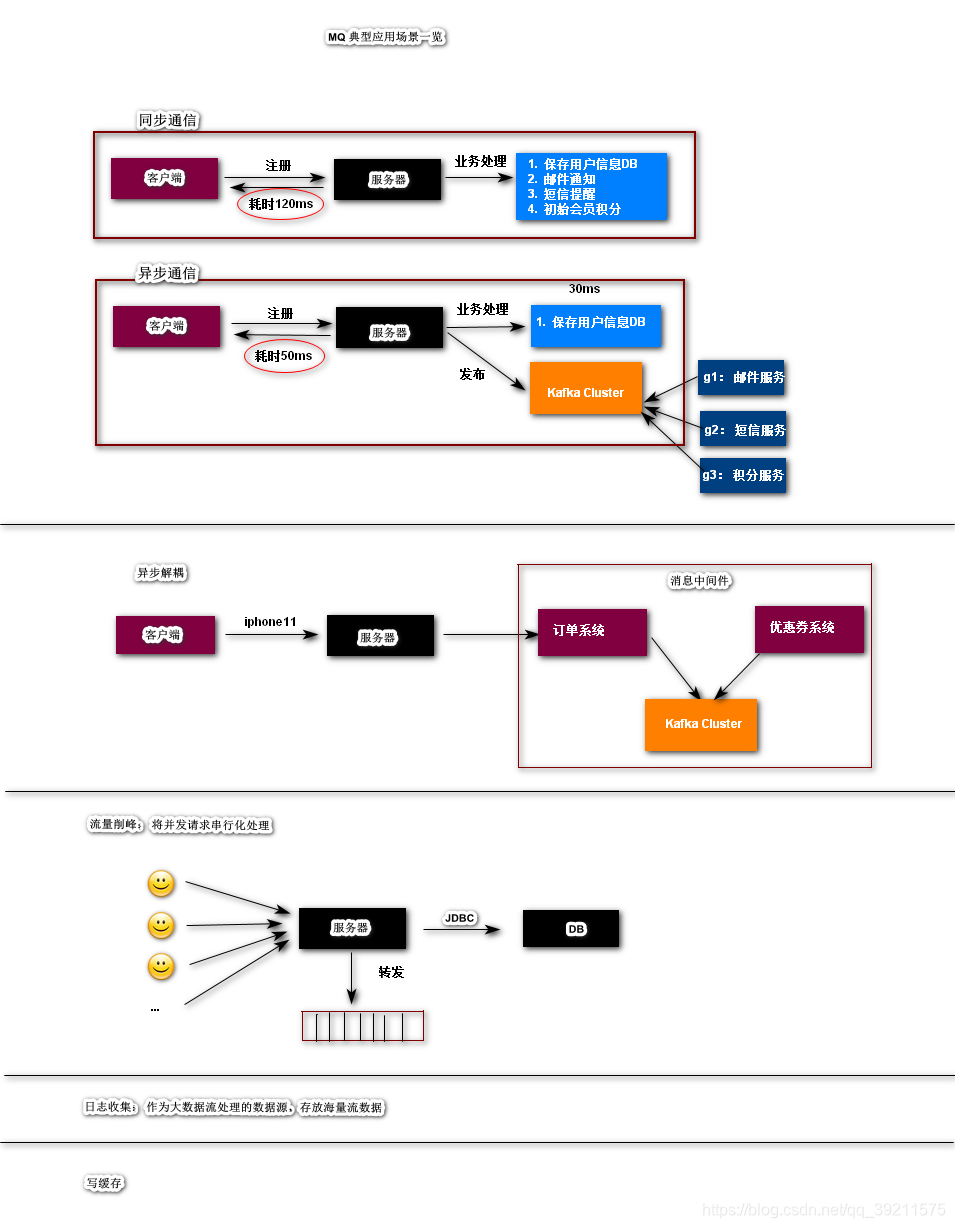
Kafka Streams(流数据处理)
批处理 & 流处理
批处理计算:
- 将大数据按照某种规则(时间,大小,数目等),划分一个个的批次数据,在未来某一个时间对每个批次数据进行统一的计算,这样的数据方式就称为批处理计算;
特征:
- 数据有界:批处理计算的数据,通常有界数据(有起始,有结束)
- 大量: 批处理计算擅长对超大规模的数据处理,如:日志,数据仓库分析,BI
- 持久: 通常情况下批处理计算的数据操作的是一个持久化的数据存储系统,如:HDFS/HBase等
- 高延迟: 批处理计算有比较高的处理延迟
批处理计算的典型应用场景: 日志分析、计费应用程序、数据仓库;
批处理计算技术选项: Hadoop MapReduce(逐渐被淘汰)\ Spark \ Flink等
流处理计算:
- 在流处理中,每一条新数据都会在到达时进行处理。与批处理不同,在下一批处理间隔之前不会等待,数据将作为单独的碎片进行处理,而不是一次处理批量(实时处理)。
不太恰当但是很形象的比喻:(其实就是个流水线一直不停的处理,来一个就开始加工处理让后输出)

特征
- 无界: 流处理计算的数据,通常是无界数据(有起始,但是永远不会有结束)
- 低延迟:流处理计算的计算延迟在毫秒和微秒级别; 比较擅长进行实时计算分析;
- 高吞吐:大多数的流处理框架都支持分布式并行处理流数据
流处理的应用场景:实时监控、风险评估、实时商业智能(如智能汽车)、实时分析等,
开源项目:Apache Kafka、Apache Flink、Apache Storm、Apache Spark、Apache Samza等。
Kafka Stream概述
Kafka Streams是一个用以开发流数据处理应用的客户端库(注意是客户端库而非框架,框架是指让你按着框架的逻辑步骤填代码,库是给你提供工具而怎么实现完全可控,灵活!)(不依赖于外部的运行环境,极为轻量级);数据源和计算结果的输出都是Kafka Topic;支持多种编程语言(Java & Scala);以及Kafka服务器端集群技术的优点**(高可用 & 可靠 & 分布式)**
特点:
- 弹性、高可扩展、容错
- 可以部署在容器、虚拟机、单独、云环境中
- 同样适用于小型、中型和大型用例
- 集成Kafka Security
- 写标准的JAVA和Scala应用
- 精确一次处理语义
- 无需单独的处理群集
- 支持多种开发平台
名词解释
- Topology(拓扑): 代表的一个流数据处理的任务,类似于MapReduce Job;Topology任务一旦启动,持续运行,触发人为或者程序故障中止;
- Processor(处理器): 代表的是Topology任务中的一个计算单元;
- Stream(数据流): 一个持续,不断产生的有序的数据集合; Streams反应的 是Kafka Input Topic中record流
- States(状态): 代表的流数据处理计算产生的中间结果,用于结果累积和容错处理
- Time(时间):
事件时间 Event time : 代表的是数据产生的时间
摄入时间 ingestion time: 代表的是数据写入到kafka时间
处理时间 processing time: 代表的是数据被计算引擎处理的时间
三个时间关系: 事件时间 <= 摄入时间(默认) <= 处理时间
Kafka Streams工作原理
Kafka Streams通过构建Kafka生产者和消费者库并利用Kafka的本机功能来提供数据并行性,分布式协调,容错和操作简便性,从而简化了应用程序开发。
架构图:
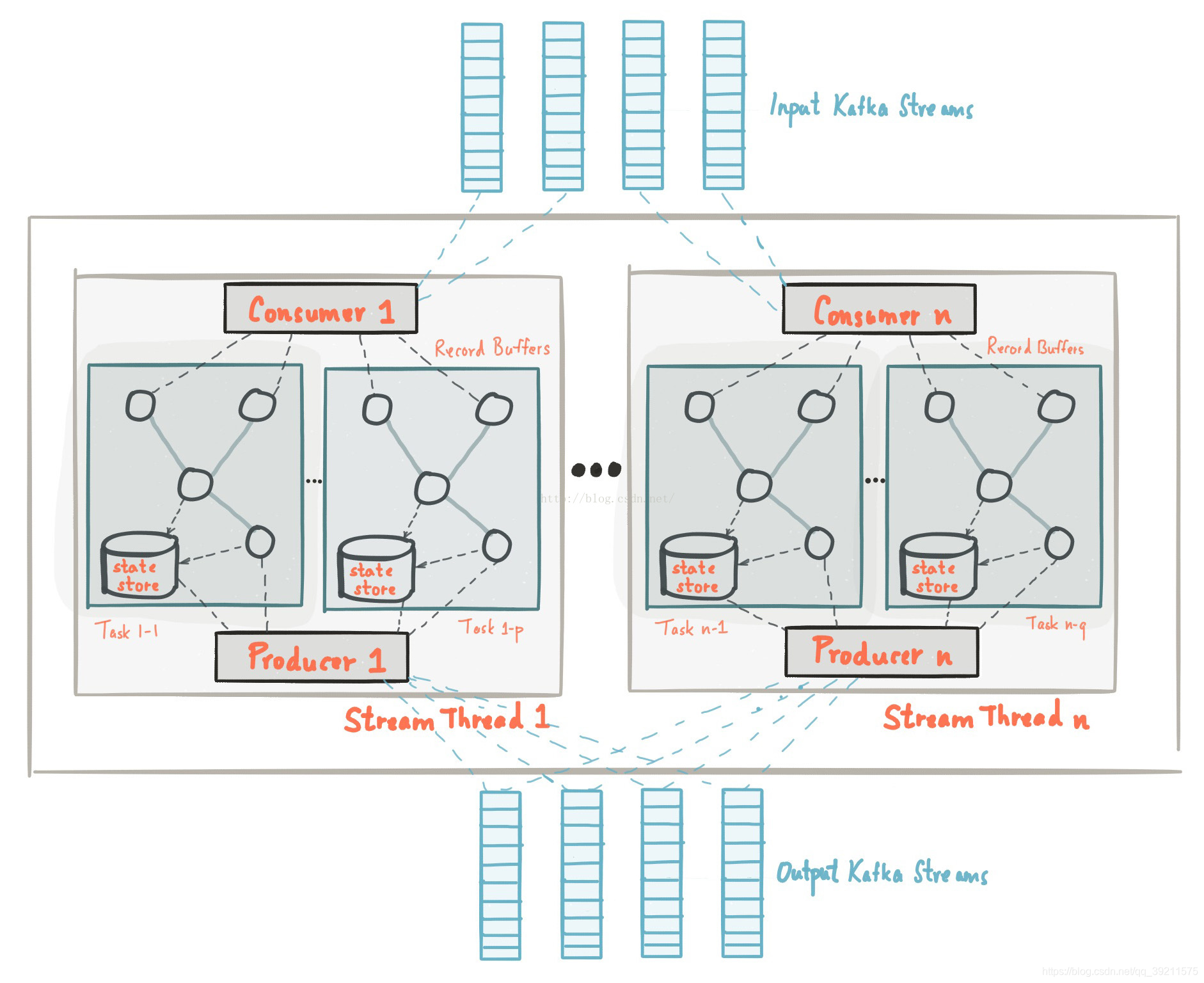
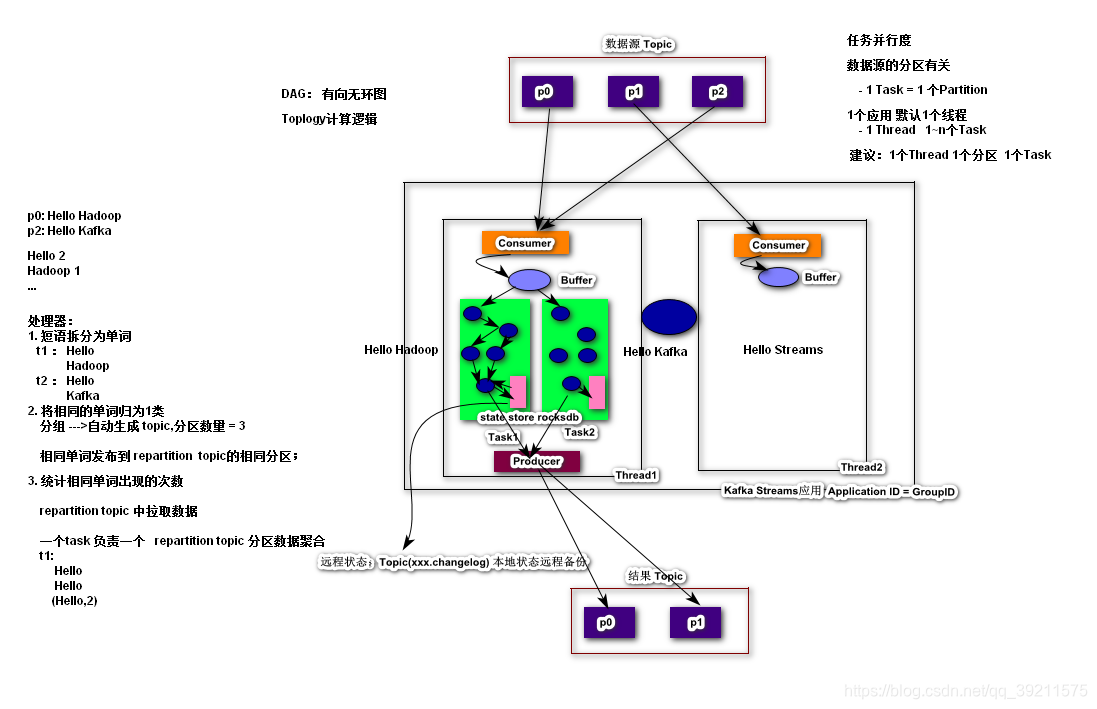
Kafka的消息分区用于存储和传递消息, Kafka Streams对数据进行分区以进行处理。 Kafka Streams使用Partition和Task的概念作为基于Kafka Topic分区的并行模型的逻辑单元。在并行化的背景下,Kafka Streams和Kafka之间有着密切的联系:
- 每个stream分区都是完全有序的数据记录序列,并映射到Kafka Topic分区。
- Stream中的数据记录映射到该Topic的Kafka消息。
- 数据记录的key决定了Kafka和Kafka Streams中数据的分区,即数据如何路由到Topic的特定分区。
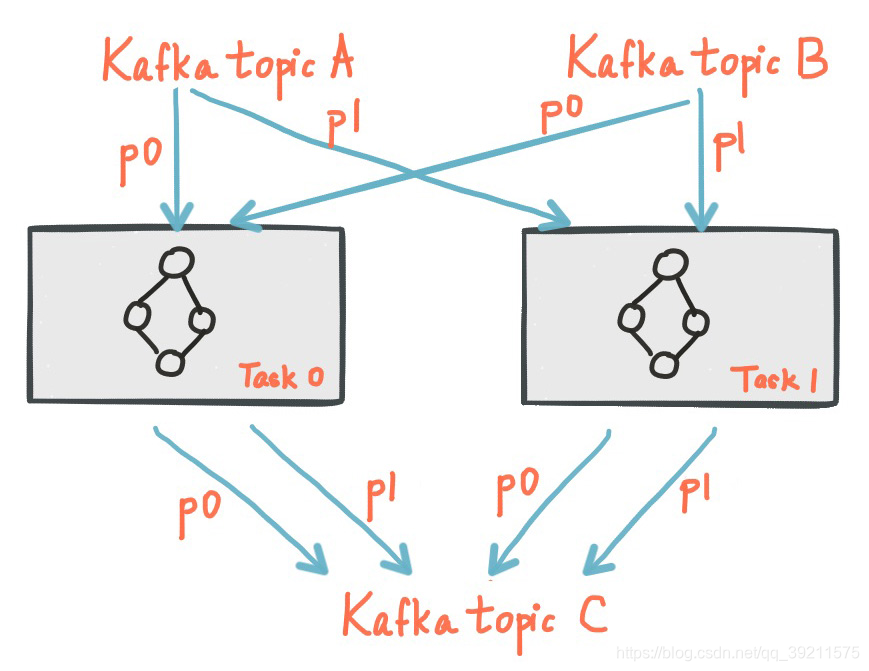
任务的并行度
Kafka Streams基于应用程序的输入流分区创建固定数量的Task,每个任务(Task)分配来自输入流的分区列表(即Kafka主题)。分区到任务的分配永远不会改变,因此每个任务都是应用程序的固定平行单元。然后,任务可以根据分配的分区实例化自己的处理器拓扑; 它们还为每个分配的分区维护一个缓冲区,并从这些记录缓冲区一次一个地处理消息。因此,流任务可以独立并行地处理,无需人工干预。
用户可以启动多个KafkaStream实例,这样等价启动了多个Stream Tread,每个Thread处理1~n个Task。一个Task对应一个分区,因此Kafka Stream流处理的并行度不会超越Topic的分区数。需要值得注意的是Kafka的每个Task都维护这自身的一些状态,线程之间不存在状态共享和通信。因此Kafka在实现流处理的过程中扩展是非常高效的。
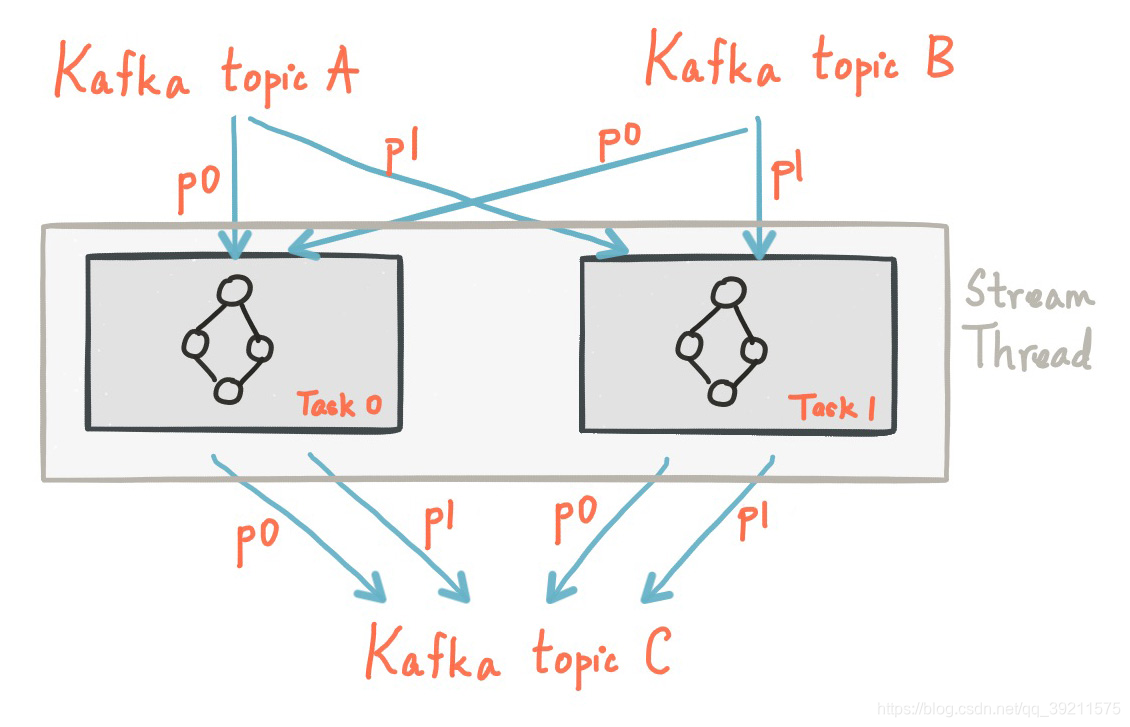
容错
Kafka Streams构建于Kafka本地集成的容错功能之上。 Kafka分区具有高可用性和复制性;因此当流数据持久保存到Kafka时,即使应用程序失败并需要重新处理它也可用。 Kafka Streams中的任务利用Kafka消费者客户端提供的容错功能来处理故障。如果任务运行的计算机故障了,Kafka Streams会自动在其余一个正在运行的应用程序实例中重新启动该任务。
此外,Kafka Streams还确保local state store也很有力处理故障容错。对于每个state store,Kafka Stream维护一个带有副本changelog的Topic,在该Topic中跟踪任何状态更新。这些changelog Topic也是分区的,该分区和Task是一一对应的。如果Task在运行失败并Kafka Stream会在另一台计算机上重新启动该任务,Kafka Streams会保证在重新启动对新启动的任务的处理之前,通过重播相应的更改日志主题,将其关联的状态存储恢复到故障之前的内容。
Kafka流处理Demo
注:创建Kafka Streaming Topology有两种方式
- low-level:低级API(繁琐 灵活)
- high-level:Kafka Streams DSL(DSL:提供了通用的数据操作算子,如:map, filter, join, and aggregations等) 高级API 推荐(简单)
导入依赖
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-streams</artifactId>
<version>2.2.0</version>
</dependency>
低级API
自定义处理器:
// 自定义对象 状态数据存储的
// private HashMap<String, Long> mapStates = new HashMap<String, Long>();
// kafka streams提供状态管理
private KeyValueStore<String, Long> keyValueStore = null;
private ProcessorContext context = null;
/**
* 初始化方法
*
* @param processorContext 处理器的上下文对象 包含了程序运行环境信息 需要context将数据发送到下游的处理器
*/
public void init(ProcessorContext processorContext) {
context = processorContext;
/*
// 定期将处理器的处理结果发送给下游的处理器
processorContext.schedule(
Duration.ofSeconds(1),
PunctuationType.STREAM_TIME,
new Punctuator() {
@Override
public void punctuate(long ts) {
System.out.println("-----------" + ts + "-----------");
mapStates.forEach((k, v) -> {
// 转发
processorContext.forward(k, v);
});
}
}
);
*/
// 通过历史状态数据 恢复还原状态数据
keyValueStore = (KeyValueStore<String, Long>) context.getStateStore("Counts");
processorContext.schedule(
Duration.ofSeconds(1),
PunctuationType.STREAM_TIME,
new Punctuator() {
@Override
public void punctuate(long ts) {
System.out.println("-----------" + ts + "-----------");
KeyValueIterator<String, Long> iterator = keyValueStore.all();
while (iterator.hasNext()){
KeyValue<String, Long> keyValue = iterator.next();
String word = keyValue.key;
Long num = keyValue.value;
context.forward(word,num);
}
}
}
);
}
/**
* 处理方法
*
* @param k
* @param v Hello Kafka | Hello Hadoop
*/
public void process(String k, String v) {
/*
if (v != null && v.length() != 0) {
String[] words = v.split("\\s");
for (String word : words) {
// 获取真实值 或者赋予默认值
Long num = mapStates.getOrDefault(word, 0L);
num++;
mapStates.put(word, num);
}
}
*/
if (v != null && v.length() != 0) {
String[] words = v.split(" ");
for (String word : words) {
// 获取真实值 或者赋予默认值
Long num = keyValueStore.get(word);
if (num == null) {
keyValueStore.put(word, 1L);
} else {
keyValueStore.put(word, num + 1L);
}
}
}
// 确认流数据处理完毕
context.commit();
}
/**
* 关闭方法
*/
public void close() {
}
开发应用
// 1. 配置对象
Properties prop = new Properties();
prop.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "HadoopNode01:9092,HadoopNode02:9092,HadoopNode03:9092");
// Key&Value默认的序列化和反序列化器
prop.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass());
prop.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass());
prop.put(StreamsConfig.APPLICATION_ID_CONFIG, "wordcount"); // 应用名 以后作为消费组的标识
prop.put(StreamsConfig.NUM_STREAM_THREADS_CONFIG, 2);
// 2. 拓扑任务对象
Topology topology = new Topology();
// 添加数据源 name = source别名
topology.addSource("s1", "t9");
// 添加处理器 name = 处理器别名 parentNames = 父组件名 s1 ---> p1
topology.addProcessor("p1", () -> new WordCountProcessor(), "s1");
// 当前处理器的处理结果 需要进行状态管理
StoreBuilder<KeyValueStore<String, Long>> storeBuilder = Stores.keyValueStoreBuilder(
Stores.persistentKeyValueStore("Counts"),
Serdes.String(),
Serdes.Long())
.withLoggingDisabled();// disabled 表示只进行local state store
// enabled 表示使用local state store + remote state store(changelog)
topology.addStateStore(storeBuilder, "p1");
// 保存计算结果 s1 ---> p1 ---> k1
topology.addSink("k1", "t10", new StringSerializer(), new LongSerializer(), "p1");
// 3. 流数据处理的对象
KafkaStreams streams = new KafkaStreams(topology, prop);
// 4. 启动流处理应用
streams.start();
highlevel: DSL API (重点)
Kafka Streams DSL(Domain Specific Language)构建于Streams Processor API之上。它是大多数用户推荐的,特别是初学者。大多数数据处理操作只能用几行DSL代码表示。在 Kafka Streams DSL 中有这么几个概念KTable、KStream和GlobalKTable
KStream是一个数据流,可以认为所有记录都通过Insert only(仅插入)的方式插入进这个数据流里。而KTable代表一个完整的数据集,可以理解为数据库中的表。
由于每条记录都是Key-Value对,这里可以将Key理解为数据库中的Primary Key,而Value可以理解为一行记录。可以认为KTable中的数据都是通过Update only(仅更新)的方式进入的。也就意味着,如果KTable对应的Topic中新进入的数据的Key已经存在,那么从KTable只会取出同一Key对应的最后一条数据,相当于新的数据更新了旧的数据。
以下图为例,假设有一个KStream和KTable,基于同一个Topic创建,并且该Topic中包含如下图所示5条数据。此时遍历KStream将得到与Topic内数据完全一样的所有5条数据,且顺序不变。而此时遍历KTable时,因为这5条记录中有3个不同的Key,所以将得到3条记录,每个Key对应最新的值,并且这三条数据之间的顺序与原来在Topic中的顺序保持一致。这一点与Kafka的日志compact相同。
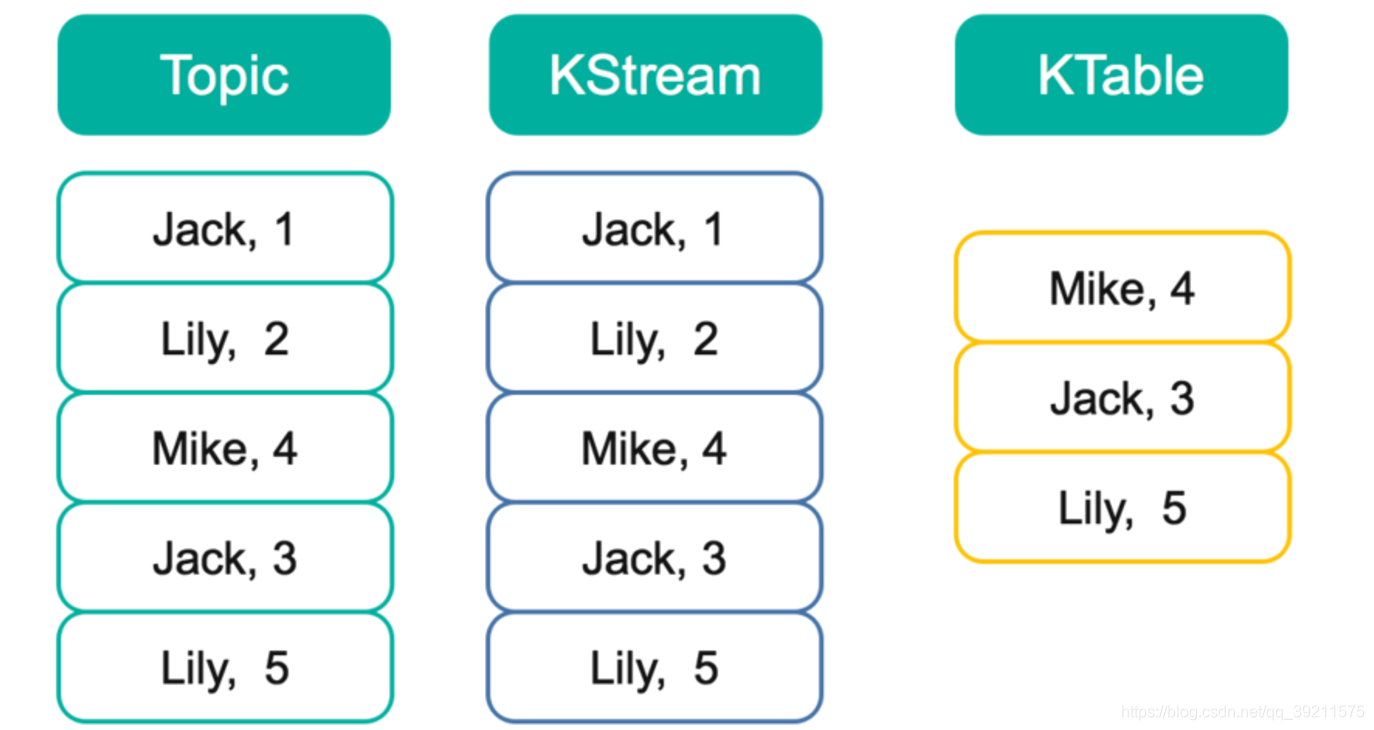
此时如果对该KStream和KTable分别基于key做Group,对Value进行Sum,得到的结果将会不同。对KStream的计算结果是<Jack,4>,<Lily,7>,<Mike,4>。而对Ktable的计算结果是<Mike,4>,<Jack,3>,<Lily,5>。
GlobalKTable:和KTable类似,不同点在于KTable只能表示一个分区的信息,但是GlobalKTable表示的是全局的状态信息。
DSL开发应用
//1. 定义一个流构建器对象 用于Topology构建
StreamsBuilder sb = new StreamsBuilder();
// 此时kStream反应的是t11 topic的记录序列
KStream<String, String> kStream = sb.stream("t11");
KTable<String, Long> kTable = kStream
// 将一个输入展开为多个输出 line
// 输入:Hello World 输出:(Hello,Hello) (World,World)
.flatMap((k, v) -> {
String[] words = v.split("\\s");
ArrayList<KeyValue<String, String>> keyValues = new ArrayList<KeyValue<String, String>>();
for (int i = 0; i < words.length; i++) {
keyValues.add(new KeyValue<String, String>(words[i], words[i]));
}
return keyValues;
})
// 将一个输入 转换为另外的一个输出
// 输入:(Hello,Hello) (World,World) 输出:(Hello,1) (World,1)
.map((String k, String v) -> new KeyValue<String, Long>(k, 1L))
// 根据K 进行分组操作
// 输入:(Hello,1) (World,1) 输出:(Hello,[1,1,1,1]) (World,[1,1])
.groupByKey(Grouped.with(Serdes.String(),Serdes.Long()))
// 统计k相同的value个数
// 输入:(Hello,[1,1,1,1]) (World,[1,1]) 输出:(Hello,4) (World,2)
.count();
// 将结果表 转换为KStream 写出到结果Topic中
kTable.toStream().to("t12", Produced.with(Serdes.String(), Serdes.Long()));
// 2. 构建Kafka Stream的配置对象
Properties prop = new Properties();
prop.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "HadoopNode01:9092,HadoopNode02:9092,HadoopNode03:9092");
// Key&Value默认的序列化和反序列化器
prop.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass());
prop.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass());
prop.put(StreamsConfig.APPLICATION_ID_CONFIG, "wordcount-dsl"); // 应用名 以后作为消费组的标识
prop.put(StreamsConfig.NUM_STREAM_THREADS_CONFIG, 2);
// 3. 构建流处理应用
KafkaStreams kafkaStreams = new KafkaStreams(sb.build(), prop);
// 4. 开始运行
kafkaStreams.start();
创建数据源和结果保存topic
bin/kafka-topics.sh --create --topic t11 --bootstrap-server node01:9092,node02:9092,node03:9092 --partitions 3 --replication-factor 3
bin/kafka-topics.sh --create --topic t12 --bootstrap-server node01:9092,node02:9092,node03:9092 --partitions 3 --replication-factor 3
启动生产者
bin/kafka-console-producer.sh --topic t11 --broker-list node01:9092,node02:9092,node03:9092
启动消费者
bin/kafka-console-consumer.sh --bootstrap-server node01:9092,node02:9092,node03:9092
--topic h2 \
--from-beginning \
--formatter kafka.tools.DefaultMessageFormatter \
--property print.key=true \
--property print.value=true \
--property key.deserializer=org.apache.kafka.common.serialization.StringDeserializer \
--property value.deserializer=org.apache.kafka.common.serialization.LongDeserializer
原理剖析
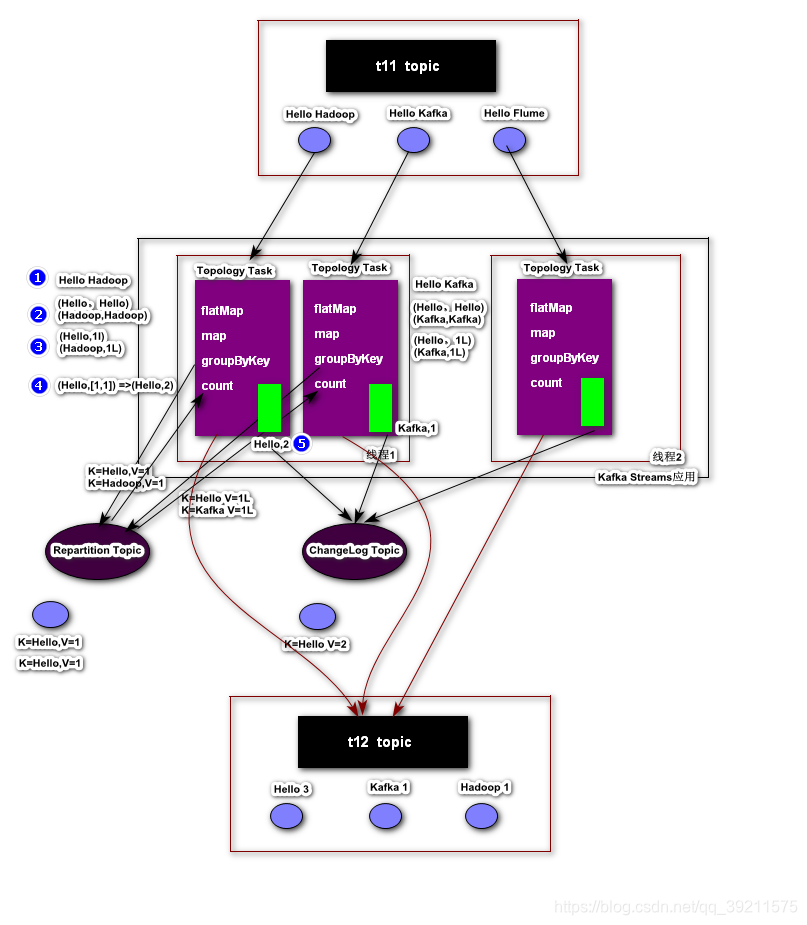
加入日志,通过日志分析执流程
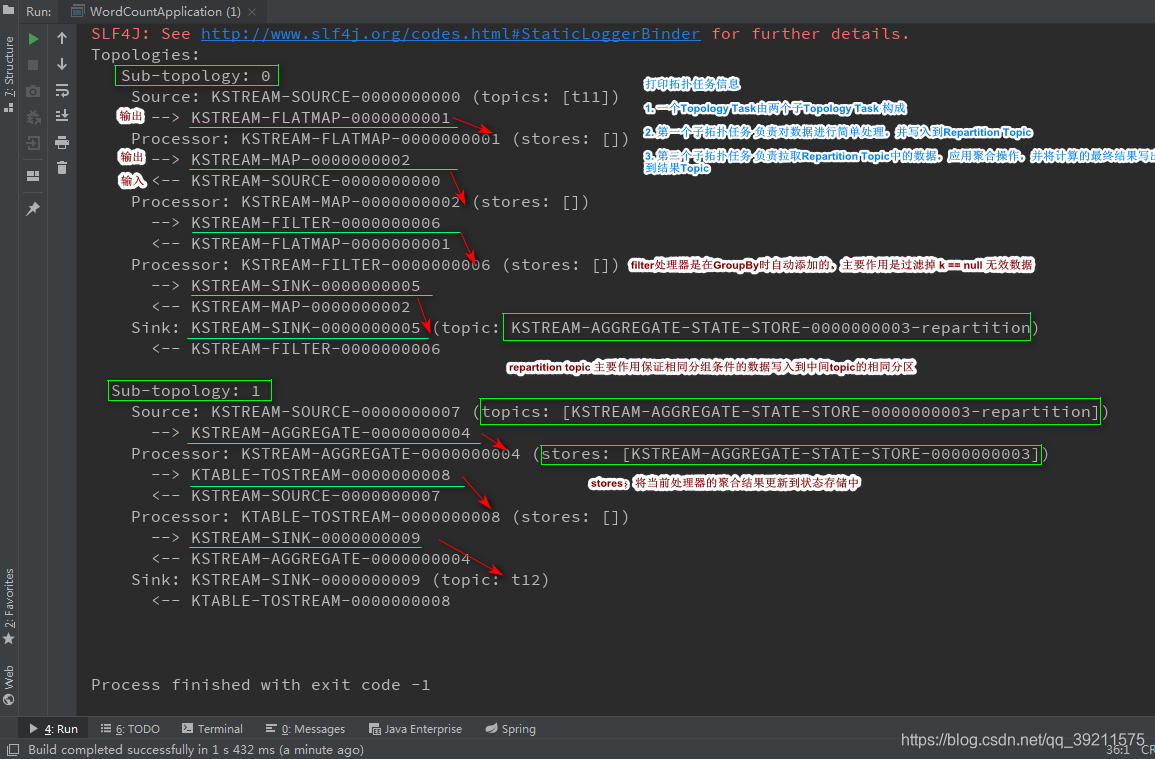
剖析:
- 在kafka streaming拓扑关系图中有两个子拓扑Sub-topology: 0和Sub-topology: 1
- Sub-topology: 0的
KSTREAM-SOURCE-0000000000会将input topic中的record作为数据源,然后经过处理器(Processor)KSTREAM-FLATMAPVALUES-0000000001、KSTREAM-KEY-SELECT-0000000002、KSTREAM-FILTER-0000000006(过滤掉key为空的中间结果),最终将处理完成的结果存放到topicKSTREAM-AGGREGATE-STATE-STORE-0000000003-repartition中。为什么这里需要-repartition的topic呢?主要原因是保证在shuffle结束后key相同的record存放在-repartition相同的分区中,这样就为下一步的统计做好了准备 - Sub-topology: 1的
KSTREAM-SOURCE-0000000007将*-repartitiontopic中的record作为数据源,然后经过ProcessorKSTREAM-AGGREGATE-0000000004进行聚合操作,并且将聚合的状态信息存放大topicKSTREAM-AGGREGATE-STATE-STORE-0000000003中,继续经过ProcessorKTABLE-TOSTREAM-0000000008,最终将处理完成的结果存放到output中
状态存储:
对于Kafka Streams高级API,默认启用状态存储;这个存储的topic:应用名-KSTREAM-AGGREGATE-STATE-STORE-序号-changelog;
Kafka中数据的删除策略:
- Delete: kafka中的数据无论是否消费,会有一个保留周期,默认7天(168H);
- Compact: 紧凑,kafka中的数据只会保留k相同的最新数据; 新值覆盖旧值; 状态数据存储时默认使用;
高阶方法(API)使用:
无状态的转换算子(stateless):不会涉及到状态数据的更新,只是数据转换操作;
- Branch
- 1个流 --> N个流 分流
KStream<String, String>[] branch = kStream
// 分流
.branch(
(String k, String v) -> v.length() == 4,
(k, v) -> v.startsWith("AA"),
(k, v) -> true
);
branch[0].foreach((k, v) -> System.out.println(k + "\t" + v));
- Filter | filterNot
- Filter: 保留符合条件的结果
- filterNot:保留不符合条件的结果
kStream
// 过滤:保存符合条件的结果
// .filter((k,v) -> v.equals("Hello"))
// 过滤:保存不符合条件的结果
.filterNot((k,v) -> v.equals("Hello"))
.foreach((k, v) -> System.out.println(k + "\t" + v));
- FlatMap
- 将一个数据展开为多个数据,如:Line —> Words
kStream
// 将一个输入展开为多个输出 line
// 输入:Hello World 输出:(Hello,Hello) (World,World)
.flatMap((k, v) -> {
String[] words = v.split("\\s");
ArrayList<KeyValue<String, String>> keyValues = new ArrayList<KeyValue<String, String>>();
for (int i = 0; i < words.length; i++) {
keyValues.add(new KeyValue<String, String>(words[i], words[i]));
}
return keyValues;
})
- FlatMapValues
- 将一个数据展开为多个数据,特点:k 不表, v展开为多个, (k,v) ---->(k,v1),(k,v2)
kStream
// 输入:k=null v=Hello Hadoop 输出 (null,Hello) (null,Hadoop)
.flatMapValues((String line) -> {
String[] words = line.split("\\s");
return Arrays.asList(words);
})
.foreach((k, v) -> System.out.println(k
- Map | MapValues
- 映射,将一个数据格式映射为另外的一个数据格式;
- map (Hello,Hello) -->(Hello,1L)
- mapValues (V=Hello) --> (V=1L) k不变
kStream
// 输入:k=null v=Hello Hadoop 输出 (null,Hello) (null,Hadoop)
.flatMapValues((String line) -> {
String[] words = line.split("\\s");
return Arrays.asList(words);
})
// (Hello,1l) (Hadoop,1l)
.map((k, v) -> new KeyValue<String, Long>(v, 1L))
// (Hello,10l) (Hadoop,10l)
.mapValues(v -> v * 10)
.foreach((k, v) -> System.out.println(k + "\t" + v));
- Foreach
- 迭代处理KStream或者KTable中数据内容
//迭代处理KStream或者KTable中数据内容
//根据key分组或者根据自定义的信息分组操作
kStream
// line: Hello Hadoop
.flatMapValues(line -> Arrays.asList(line.split("\\s")))
// (Hello,Hello) (Hadoop,Hadoop)
.map((k, v) -> new KeyValue<>(v, v))
// 根据KeyValue对象的value进行分组
.groupBy((String k, String v) -> v, Grouped.with(Serdes.String(), Serdes.String()))
.count()
.toStream()
.foreach((k, v) -> System.out.println(k + "\t" + v));
- Merge
- 将多个KStream 合流为1个
KStream<String, String>[] branch = kStream
.branch(
(k, v) -> v.length() == 4,
(k, v) -> v.startsWith("AA"),
(k, v) -> true
);
// 流和流merge 注意两个流的泛型必须一致
KStream<String, String> newKStream = branch[0].merge(branch[1]);
newKStream.foreach((k,v) -> System.out.println(k +"\t"+v));
- Peek
- 程序探针,通常用于调试,不会对数据本身造成任何影响
kStream
// 不会改变数据的输入和输出 只用于调试
// line
.peek((k, v) -> System.out.println(k + "\t" + v))
.flatMapValues((k, v) -> Arrays.asList(v.split("\\s")))
// (null,word)
.foreach((k, v) -> System.out.println(k + "\t ----" + v));
- 输出,将KStream内容输出打印或者输出到文件(无法使用)中
kStream
// 不会改变数据的输入和输出 只用于调试
// line
.peek((k, v) -> System.out.println(k + "\t" + v))
.flatMapValues((k, v) -> Arrays.asList(v.split("\\s")))
// (null,word)
.print(Printed.toSysOut());
//.print(Printed.toFile("d:\\abc"));
- SelectKey
- 将一个key转换为另外一种key,value不变
.selectKey((k, v) -> v + "?")
有状态的转换算子(stateful)使用时,涉及到状态数据的更新
有状态转换值得是每一次的处理都需要操作关联StateStore实现有状态更新。例如,在aggregating 操作中,window state store用于收集每个window的最新聚合结果。在join操作中,窗口状态存储用于收集到目前为止在定义的window边界内接收的所有记录。状态存储是容错的。如果发生故障,Kafka Streams保证在恢复处理之前完全恢复所有状态存储。
DSL中可用的有状态转换包括:
- Aggregating
- Joining
- Windowing
- Applying custom pr
下图显示了它们之间的关系:

API:
Aggregating:用于进行聚合操作的,有状态的转换算子
- Count
- 滚动聚合 按分组键计算记录数
kStream
// 将一个输入展开为多个输出 line
// 输入:Hello World 输出:(Hello,Hello) (World,World)
.flatMap((k, v) -> {
String[] words = v.split("\\s");
ArrayList<KeyValue<String, String>> keyValues = new ArrayList<KeyValue<String, String>>();
for (int i = 0; i < words.length; i++) {
keyValues.add(new KeyValue<String, String>(words[i], words[i]));
}
return keyValues;
})
// 将一个输入 转换为另外的一个输出
// 输入:(Hello,Hello) (World,World) 输出:(Hello,1) (World,1)
.map((String k, String v) -> new KeyValue<String, Long>(k, 1L))
// 根据K 进行分组操作
// 输入:(Hello,1) (World,1) 输出:(Hello,[1,1,1,1]) (World,[1,1])
.groupByKey(Grouped.with(Serdes.String(), Serdes.Long()))
// 统计k相同的value个数
// 输入:(Hello,[1,1,1,1]) (World,[1,1]) 输出:(Hello,4) (World,2)
.count();
- Aggregate
- 滚动聚合 按分组键聚合(非窗口化)记录的值
kStream
.flatMapValues(line -> Arrays.asList(line.split("\\s")))
.map((k, v) -> new KeyValue<>(v, 1L))
.groupByKey(Grouped.with(Serdes.String(), Serdes.Long()))
// 参数1:初始化器,提供一个初始值 参数2:聚合器,用以进行聚合操作 参数3:因为涉及到状态数据的更新,读写操作changelog的topic,指定KV序列化和反序列化器的类型
.aggregate(
() -> 0L,
(k, v, aggValue) -> v + aggValue,
Materialized.with(Serdes.String(), Serdes.Long())
)
.toStream()
.foreach((k, v) -> {
System.out.println(k + "\t" + v);
});
- Reduce
- 滚动聚合 通过分组键组合(非窗口)记录的值
kStream
.flatMapValues(line -> Arrays.asList(line.split("\\s")))
.map((k, v) -> new KeyValue<>(v, 1L))
.peek((k,v) -> System.out.println(k+"\t"+v))
.groupByKey(Grouped.with(Serdes.String(), Serdes.Long()))
// 参数1:计算器 参数2:因为涉及到状态数据的更新,读写操作changelog的topic,指定KV序列化和反序列化器的类型
.reduce((v1, v2) -> v1 - v2,Materialized.with(Serdes.String(), Serdes.Long()))
.toStream()
.foreach((k, v) -> {
//System.out.println(k + "\t" + v);
});
Window窗口计算
所谓的窗口计算,指的是在流数据的基础之上,按照时间划分的微批(micro batch),对每一个窗口内的数据应用计算规则,得到窗口的计算结果;如:每隔1分钟统计一次车流量的违章信息或者京东商品热卖榜(每隔10分钟更新一次)
- Tumbling(翻滚)
- 窗口长度大小固定 窗口和窗口之间的数据无重叠 ; 数据区间 前闭后开
- 翻滚窗口将流元素按照固定的时间间隔,拆分成指定的窗口,窗口间元素之间没有重叠。
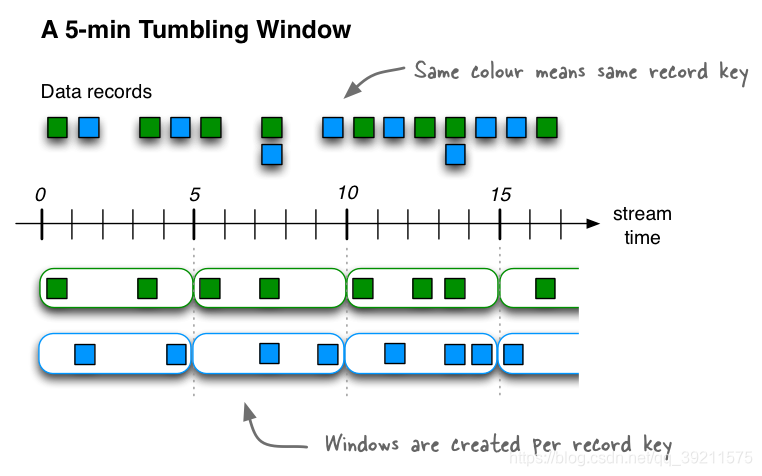

kStream
.flatMapValues(line -> Arrays.asList(line.split("\\s")))
.map((k, v) -> new KeyValue<>(v, 1L))
.groupByKey(Grouped.with(Serdes.String(), Serdes.Long()))
.windowedBy(TimeWindows.of(Duration.ofSeconds(10)))
// 参数1:计算器 参数2:因为涉及到状态数据的更新,读写操作changelog的topic,指定KV序列化和反序列化器的类型
.reduce((v1, v2) -> v1 + v2, Materialized.with(Serdes.String(), Serdes.Long()))
.toStream()
.foreach((k, v) -> {
String key = k.key();
Window window = k.window();
long startTS = window.start();
long endTS = window.end();
SimpleDateFormat sdf = new SimpleDateFormat("HH:mm:ss");
String start = sdf.format(new Date(startTS));
String end = sdf.format(new Date(endTS));
System.out.println(key + "\t" + start + "<---->" + end + "\t" + v);
});
- Hopping (跳跃)
- 窗口长度大小固定 窗口和窗口之间的数据有重叠 数据范围依然是 前闭后开
Hopping time windows是基于时间间隔的窗口。他们模拟固定大小的(可能)重叠窗口。
跳跃窗口由两个属性定义:窗口大小和跳跃步长(又名“hop”)。

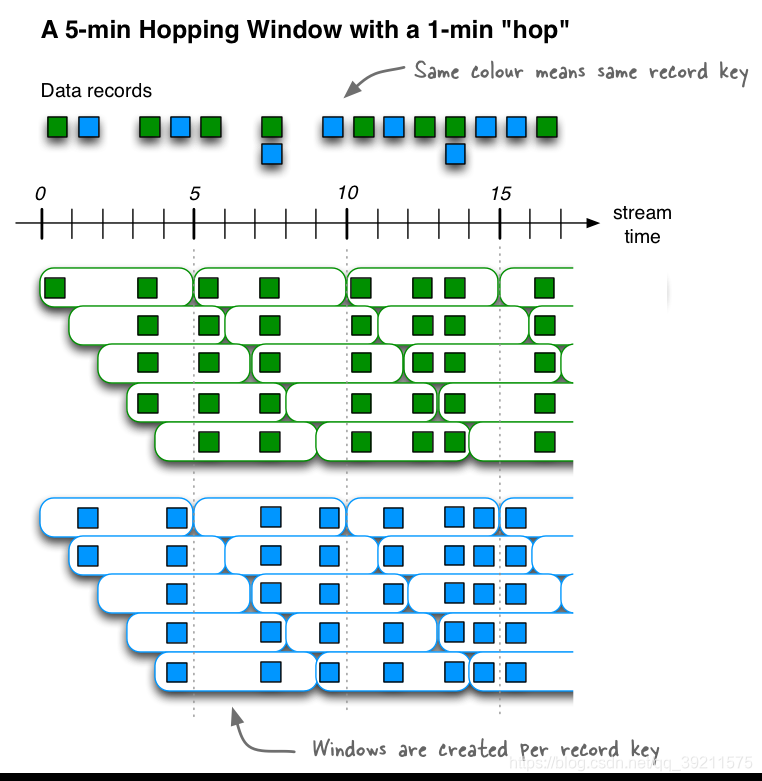

kStream
.flatMapValues(line -> Arrays.asList(line.split("\\s")))
.map((k, v) -> new KeyValue<>(v, 1L))
.groupByKey(Grouped.with(Serdes.String(), Serdes.Long()))
// 翻滚窗口
// .windowedBy(TimeWindows.of(Duration.ofSeconds(10)))
// 跳跃窗口 窗口大小10s 跳跃步长3s
// w1: 0s~10s w2: 3~13s w3:6s~16
.windowedBy(TimeWindows.of(Duration.ofSeconds(10)).advanceBy(Duration.ofSeconds(3)))
// 参数1:计算器 参数2:因为涉及到状态数据的更新,读写操作changelog的topic,指定KV序列化和反序列化器的类型
.reduce((v1, v2) -> v1 + v2, Materialized.with(Serdes.String(), Serdes.Long()))
.toStream()
.foreach((k, v) -> {
String key = k.key();
Window window = k.window();
long startTS = window.start();
long endTS = window.end();
SimpleDateFormat sdf = new SimpleDateFormat("HH:mm:ss");
String start = sdf.format(new Date(startTS));
String end = sdf.format(new Date(endTS));
System.out.println(key + "\t" + start + "<---->" + end + "\t" + v);
});
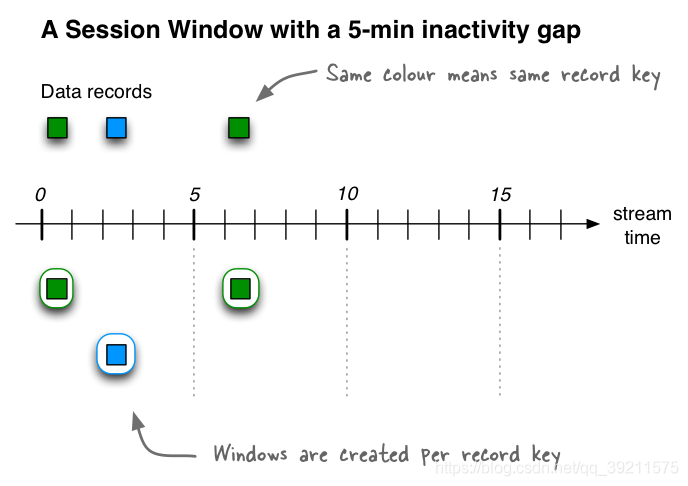
- Session(会话)
- 窗口大小不固定(取决会话窗口活跃间隙),窗口之间的数据无重叠, 前闭后开
Session Window该窗口用于对Key做Group后的聚合操作中。它需要对Key做分组,然后对组内的数据根据业务需求定义一个窗口的起始点和结束点。一个典型的案例是,希望通过Session Window计算某个用户访问网站的时间。对于一个特定的用户(用Key表示)而言,当发生登录操作时,该用户(Key)的窗口即开始,当发生退出操作或者超时时,该用户(Key)的窗口即结束。窗口结束时,可计算该用户的访问时间或者点击次数等。
Session Windows用于将基于key的事件聚合到所谓的会话中,其过程称为session化。会话表示由定义的不活动间隔(或“空闲”)分隔的活动时段。处理的任何事件都处于任何现有会话的不活动间隙内,并合并到现有会话中。如果事件超出会话间隙,则将创建新会话。
会话窗口的主要应用领域是用户行为分析。基于会话的分析可以包括简单的指标.
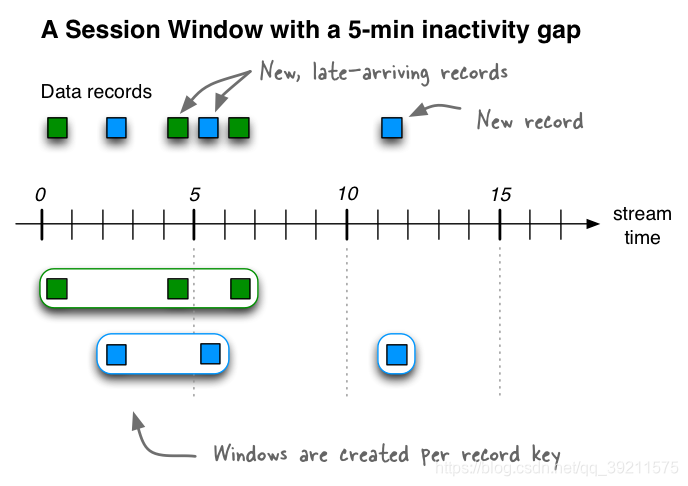
如果我们接收到另外三条记录(包括两条迟到的记录),那么绿色记录key的两个现有会话将合并为一个会话,从时间0开始到结束时间6,包括共有三条记录。蓝色记录key的现有会话将延长到时间5结束,共包含两个记录。最后,将在11时开始和结束蓝键的新会话。
kStream
.flatMapValues(line -> Arrays.asList(line.split("\\s")))
.map((k, v) -> new KeyValue<>(v, 1L))
.groupByKey(Grouped.with(Serdes.String(), Serdes.Long()))
// 会话窗口 会话的活跃间隙是10s
.windowedBy(SessionWindows.with(Duration.ofSeconds(10)))
// 参数1:计算器 参数2:因为涉及到状态数据的更新,读写操作changelog的topic,指定KV序列化和反序列化器的类型
.reduce((v1, v2) -> v1 + v2, Materialized.with(Serdes.String(), Serdes.Long()))
.toStream()
.foreach((k, v) -> {
String key = k.key();
Window window = k.window();
long startTS = window.start();
long endTS = window.end();
SimpleDateFormat sdf = new SimpleDateFormat("HH:mm:ss");
String start = sdf.format(new Date(startTS));
String end = sdf.format(new Date(endTS));
System.out.println(key + "\t" + start + "<---->" + end + "\t" + v);
});















 4521
4521











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









