







1. 论文研究的主要问题
一个典型的视频行人重识别系统通常包括三个部分:特征提取器,时域建模方法和损失函数。其中特征提取器用来采集图片级别的特征,时域建模方法用来融合时间特征。
基于视频的行人重识别方法和基于图片的行人重识别方法最大的区别在于时域信息,视频具有图片所没有的时域信息。目前有很多文章提出了时域建模的方法,那么什么样的时域建模方法是最有效的呢?这就是论文研究的主要问题。
下面给出文章及其代码实现的链接:
论文链接:https://arxiv.org/abs/1805.02104
代码链接:https://github.com/jiyanggao/Video-Person-ReID
作者对论文的解读:https://zhuanlan.zhihu.com/p/36395908
2. 主要工作
文章的主要贡献如下:
- 回顾并比较用于视频行人重识别的时间建模方法。
- 提出了一个采用时间卷积提取帧间信息的注意力生成网络
- 提出的网络在 MARS 数据集上达到了 state-of-the-art 。
2.1 回顾时间建模方法
文章针对常用的时域建模方法 temporal pooling, temporal attention, RNN 和 3D convnets 进行了研究。由于特征提取器和损失函数对于基于视频的行人重识别模型性能影响很大,为了公平地比对各种时域建模方法的有效性,作者采用了固定的特征提取器和损失函数进行实验。
由于 3D convnets 可以提取到 3D 特征(空间特征+时域特征),因此不使用固定的特征提取器。剩余三种方法 temporal pooling, temporal attention, RNN 均采用 ResNet-50 作为特征提取器。上述所有四种方法均采用 triplet + softmax cross entropy 作为损失函数。

2.2 提出新的 attention generation network
文章提出了一个采用时间卷积提取帧间信息的注意力生成网络,即 方法 “spatial + temporal conv"。
将提取到的图片特征序列输入注意力生成网络:首先经过一个维度为 {w,h,2048,dt} 的卷积层, 然后序列的每一帧特征维度都是 dt ;然后经过一个维度为 {3,dt,1} 时间卷积层,最后获得了帧间特征的时间注意力。
attention generation 模块如下图所示:

2.3 损失函数
一个视频行人重识别系统包括三个部分:从视频片段中提取视觉表示的视频编码器,用于优化视频编码器的损失函数以及匹配查询视频与图库视频的方法。
文章提出的方法采用 2D 特征提取器提取图片特征,使用上文提出的 attention generation network 建模时间信息,构成提取视频特征的视频编码器。
提出了 triplet loss function 和 Softmax cross-entropy loss function 结合的损失函数。
triplet loss function:为了形成一个批次,我们随机抽取 P 个行人并为每个行人随机抽取 K 个视频片段(每个视频片段包含 T 帧); 一共有一批PK剪辑。 对于batch中的每个样本a,在形成 triplet 时选择 batch 中最难的正样本和最难的负样本来计算损失Ltriplet

Softmax 交叉熵损失函数使网络将 PK 个视频片段分类为正确的身份
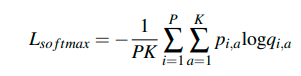
最后,总的损失为:
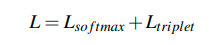
2.4 测试中的相似度计算
在测试过程中,提取视频中的每个片段的特征表示,所有片段特征表示的平均值就是视频特征表示。 最后用 L2 距离衡量视频之间的相似度。
3. 实验
所有的实验都在 MARS 数据集上进行。
实验一:3D convnets
实验采用 ResNet3D-50 测试 3D convnets 模型的性能,序列长度 T 为 4,模型表现更好。

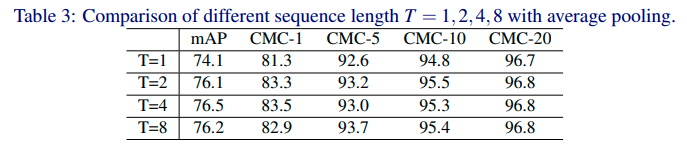
实验二:Temporal pooling
实验采用 average pooling 和 max pooling 测试 Temporal pooling 方法,
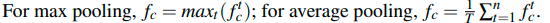
实验证明 average pooling 比 max pooling 性能更好。

当序列长度 T 为 4,average pooling 模型性能达到最好。
实验三:Temporal attention
在 Temporal attention 模型中,对图像特征序列应用注意力加权平均。其中,f 指图片的特征,a 指权重 attention scores 。
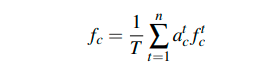
图片特征构成的序列通过 attention generation network 可以得到一个标量,经过一个函数计算就可以获得 attention scores 。
有两种函数可以用来计算 attention scores 。Softmax function:
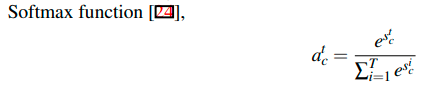
Sigmoid function + L1 normalization:
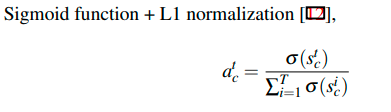
实验设计了两种注意力网络(attention networks)来测试 Temporal attention 模型的性能:
- spatial conv + FC
“spatial conv + FC ": we apply a spatial conv layer (kernel width =
w, kernel height = h, input channle number =2048, output channel number = dt
, short for{w,h,2048,dt}) and a Fully-Connected (FC) (input channel = dt, output channel = 1) layer on
the aforementioned output tensor; the output of the conv layer is a scalar vector stc,t ∈ [1,T],
which is used as the score for the frame t of clip c.
- spatial + temporal conv
“spatial + temporal conv": first a conv layer with shape {w,h,2048,dt} is applied, then we get a dt-dimensional feature for each frame of the clip,
we apply a temporal conv layer {3,dt,1} on these frame-level features to generate temporal attentions stc.
将 spatial conv + FC 作为注意力生成网络,对比 Softmax function 和 Sigmoid function,实验结果表明二者性能差不多。

使用 softmax 作为计算 attention scores 的函数,实验结果表明 spatial + temporal conv 是性能更好的注意力生成模型。
证明了 temporal convolution 的有效性。

实验四:RNN
RNN 单元在一个时间步长 t 对序列中的一个图像特征进行编码,并将隐藏状态 ht 传递到下一个时间步长。
文章考虑两种序列特征融合的方法:
- 方法1:直接取最后一个时间步的隐藏状态 hT
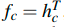
-方法2:计算 RNN 输出的平均值
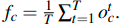
实验测试了两种 RNN cell: Long Short-Term Memory (LSTM) and Gated Recurrent Unit (GRU)
将 LSTM 作为基础 RNN cell 时,取 final hidden state 作为序列特征融合输出,在不同的 hidden state size (512,1024,2048) 进行测试,Dh = 512 模型效果最好。
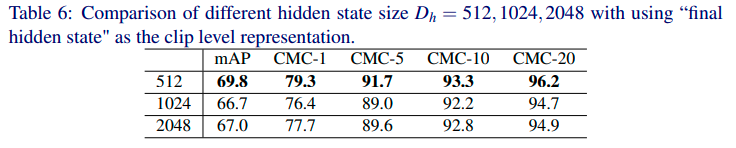
取 cell 输出的平均池化作为序列特征融合输出,在不同的 hidden state size (512,1024,2048) 进行测试,Dh = 512 模型效果最好。
显然,“cell outputs average" 的效果比 “final hidden state“ 要好。因此,使用 “cell outputs average" 作为序列特征融合方法,对比 RNN cells 类型 LSTM 和 GRU,LSTM 达到了更好的效果。

序列长度 T 为 4 时,RNN 模型效果最好。
实验五:SOTA 时域建模方法对比
- 对于 temporal pooling, 使用 mean pooling 并设置序列长度 T = 4;
- 对于 temporal attention, 使用 “Softmax" + “spatial conv + temporal conv" 并设置序列长度 T = 4;
- 对于 RNN, 设置 hidden state 尺寸 Dh = 512,序列长度 T = 4 并使用 “cell outputs average"
实验结果如下表所示。实验发现:
- 使用 RNN 进行时间聚合不太有效
- 时间注意力比平均池化效果更好
- 时间建模方法可以有效提高模型性能(与 baseline 相比)

4. 讨论
文章对比了其他文章提出的时间建模方法效果,讨论了一些时间建模模型无效的原因。
下文引自作者知乎文章:
说说实验结果和结论吧。要说明的是,虽然这些方法提炼自之前的文章,但是我的结果和结论 仅能代表在我这种实验条件下的表现,不能说明之前文章方法的好或不好。
temporal modeling 是有用的 ,在mAP和CMC-1上能带来2-3个点的提升。
RNN表现比较差,甚至不如 single image。之前的工作里RNN之所以能work,我猜测是他们的 image feature extractor大都是 shallow的,自身的结构还不是optimal的,加上一层RNN相当于加深了网络深度,也许feature 也就更representative了。
temporal pooling的表现很强的,和attention 持平。
attention之所以没有比pooling更好,我个人猜测是,一个clip其实很短,不过1/4 到1/2秒,图片间的质量差距没多大(也看不出什么变化),不需要attention做一个weighted average;反倒是clip和clip之间差距可能很大,毕竟一个video可以很长,也许这里才用得到attention。















 401
401











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









