






Attention机制在视觉领域和nlp领域都有应用,首先是在视觉上提出来,但之后在nlp方面取得了广泛的使用。
Attention在nlp的应用(主要是机器翻译)
主要围绕《NEURAL MACHINE TRANSLATION BY JOINTLY LEARNING TO ALIGN AND TRANSLATE》和《Attention Is All You Need》两篇文章讲
1. NEURAL MACHINE TRANSLATION BY JOINTLY LEARNING TO ALIGN AND TRANSLATE
以往的使用神经网络的机器翻译模型通常使用seq to seq模型,当然不一定是LSTM,普通的RNN也可以,具体如下,

简单的说明下这个模型,就是用一个编码器把之前的输入 都编码到C这个向量,然后用解码器对C解码生成需要的输出
这种结构会有一个问题,就是因为C的定长的,所以,他能表示的信息也是有限的,当编码器中输入的信息非常多的时候,那么C使用固定的编码长度就可能会使C记录不到很多关键信息,模型遇到瓶颈,
这篇论文的解决方案,Attention机制,方案如下:
![]()
![]()

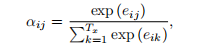
![]()
![]()
可以看到就是把C的表示换了C由很多个 并成的,每个
都是
的线性加权组合,并且这个
是直接与
相关的,那么权重
就代表
与各个
的相关程度,相关程度的度量由
![]() 度量,度量解码器中每个隐藏层和编码器中每个隐藏层的相关关系,这个相关关系用
度量,度量解码器中每个隐藏层和编码器中每个隐藏层的相关关系,这个相关关系用函数度量,当然
函数可以是很多种,不一定是上面这种。以上这种是叫做Attention机制,我认为他做的事就是让C这个编码更加准确,因为RNN的长期依赖问题,可能会导致C这个编码对近期的输入更加敏感,而对更远的输入的信息并没有采集到。所以使用这样的机制来补救,这有点类似于FPN特征提取了。
2. Attention Is All You Need(还是没怎么懂,省略吧)
一个完全使用attention架构实现的模型,模型结构如下:

乍一看会觉得很难看懂这个图,左边是encode,右边是decode,
encoder: encode由一个6层的组成,上图左边之画出了一层,每一层由两个子层组成,一个Multi-Head Attention,一个是全连接Feed Foward,两者后面都加了归一化层。从上图可以看到每个子层还使用了残差连接。注意Multi-Head Attention的输入由3根输入的箭头,Multi-Head Attention架构如下:


上图中的Linear很好理解是一个线性层,而且是多个不同的线性层,叠加。其中的Scaled Dot-product Attention机制也在上图
其中mask是可选的,就是说可以选可以不选,在decode中可以看到就是用mask Multi-Head Attention,计算公式如下

这个可以看成算Q和K的相关程度,然后用这个相关程度乘V采样V,可以把输入信息编码看成K—V键值对,然后Q代表输出的信息编码,计算Q和K间的相关程度,然后归一化,采样V。这和上面介绍的那篇论文有点像,上面那篇的编码隐状态代表K和V, K=V,解码隐状态代表Q。现在采用Q,K,V形式。为什么要多一个K呢。。我也不知道

其中 代表K的维度, 而在Multi-Head Attention中Q=K=V,而Q,K,V由position_encoding生成,Q,K,V等于Q,K,V+position_encoding
position_encoding计算方式如下。pos是位置信息,序列中的位置,当前节点处于序列中的位置,第一个就是1,以此类推

decoder: decode一共也有6层,每层由3个子层,对从图中就可以看到多了个mask Multi-Head Attention这个mask就是让当前提取注意力不使用后面预测的编码,因为![]() ,与后面是无关的。
,与后面是无关的。
总体了解下这个架构,引用一张图,可以看到顶部的encode编码出的memory给每个解码器用。

这个网络我觉得可以看成把RNN的时间那条轴变短了,反而把隐藏层的深度加大了,总体上,有点像从RNN到深度NN的扩展,先使用深的网络对输入进行编码为memory,然后把memory进行很多层的解码然后输出。但是具体的细节很多。有兴趣可以看看原文。
Attention在图像上的应用
参考论文《MULTIPLE OBJECT RECOGNITION WITH VISUAL ATTENTION 》
1. MULTIPLE OBJECT RECOGNITION WITH VISUAL ATTENTION
这篇文章有点像目标检测,但是使用的是另外一种思路,技巧性极强,非常好的一篇文章
文章使用的例子是多个数字的目标识别,使用RNN做的
网络架构如下

主要思路是这样,
先初略的看一下这张图,然后看到第一个数字的位置,接着通过这块位置的图片块再次输入输入网络可以得到该图片块中数字是0-9中的哪个,并且输出下一个数字的位置,那么一直这么识别直到输出的位置标志为没有数字位置为止。思路很简单,我们具体看他怎么实现的,通过4个网络,
glimpse network:输入时图片块和和
作为输入,输出的计算公式是:

![]() 使用图片块
使用图片块作为输入,使用3和卷积层加一个全连接,
![]() 使用一个全连接隐藏层,然后两者相同维度点乘。,
使用一个全连接隐藏层,然后两者相同维度点乘。,
Recurrent network:使用两层的隐藏层,从图中可以更加直观看到,此处使用的LSTM网络,所以每个隐层都是一个LSTM单元

Emission network:这个好理解,使用带一个隐藏层的全连接网络,就是拿做非线性变换,输出下一个数字的位置
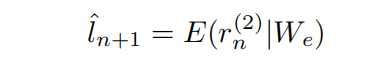
Context network: 提供一个初始状态,预测第一个glimpse,使用一个下采样的原图片输入,通过LSTM得到再经过emission network得到next glimpse的位置,使用3个卷积层,
classifiction network:对于每一个都需要输出一个类别,代表数字是0-9的哪个,使用一个全连接隐层和softmax

以上就是网络的全部了,好,问题来了怎么train一个这样的网络呢,一个直观的感觉就是我们可以用布标检测的方法,把分类error和回归eoor加权相加,作为总的损失来训练,但是这篇文章并不是,使用了很有技巧性的方法
很容易知道网络最终优化的是![]() ,我们有
,我们有![]() 这个式子不难推,就是最大似然函数,要优化这个式子比较的难,文中使用变分下界来优化这个式子,通过把下界最大化,从而让这个似然函数也变大,
这个式子不难推,就是最大似然函数,要优化这个式子比较的难,文中使用变分下界来优化这个式子,通过把下界最大化,从而让这个似然函数也变大,

然后要优化这个下界,对下界求导有

得到梯度,现在唯一的问题是 是固定的,不能随意变化,
![]() 这个概率很难确定,因为网络输出的直接是
这个概率很难确定,因为网络输出的直接是元组里的值,所以,现在假设
服从高斯分布,得到
的概率函数,然后就可以对W就可以求导了,注意采样要在目标内,不然分类的y的标签就有问题了,采样M个然后使用标准反向传播对模型参数的梯度进行估计

然后把![]() 换成了R函数,以此来减少方差,因为采样的位置信息可能已经脱离了目标位置了,预测的y不准,
换成了R函数,以此来减少方差,因为采样的位置信息可能已经脱离了目标位置了,预测的y不准,![]() 似然函数会很大。会导致梯度更新不稳定。这样的更新不太好。所以采用R-b的形式,b也使用神经网络估计。
似然函数会很大。会导致梯度更新不稳定。这样的更新不太好。所以采用R-b的形式,b也使用神经网络估计。

得到最终梯度更新的式子

总的来理解呢,后面这项有点类似强化学习中的策略梯度更新了,使用一个R-b价值来控制变化,让价值高于baselin价值时,我们说这个梯度更新是好的,就给予一个正值让梯度这么更新,当不好的时候,就给与一个负值像相反方向更新,并且更新幅度很稳定,这样会让方差小些。
从这个式子看,可以看到前面这项是分类梯度,后面这项是回归梯度。这也让最后的更新方式显得非常合理。如果是现在的目标检测会把回归任务使用最小二乘,而这里依旧使用最大似然函数,通过假设位置信息服从高斯分布。个人感觉还是回归使用最小二乘做为损失函数效果好一些。














 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









