






在深度学习中,注意力机制的目标是从大量的信息中选择出更有用的信息。
在Attention is all you need这篇文章中提出了著名的Transformer模型,Transformer中抛弃了传统的CNN和RNN,整个网络结构完全是由Attention机制组成。更准确地讲,Transformer由且仅由self-Attention和Feed Forward Neural Network组成,这里重点讲一下Transformer中self-Attention的运行机制。
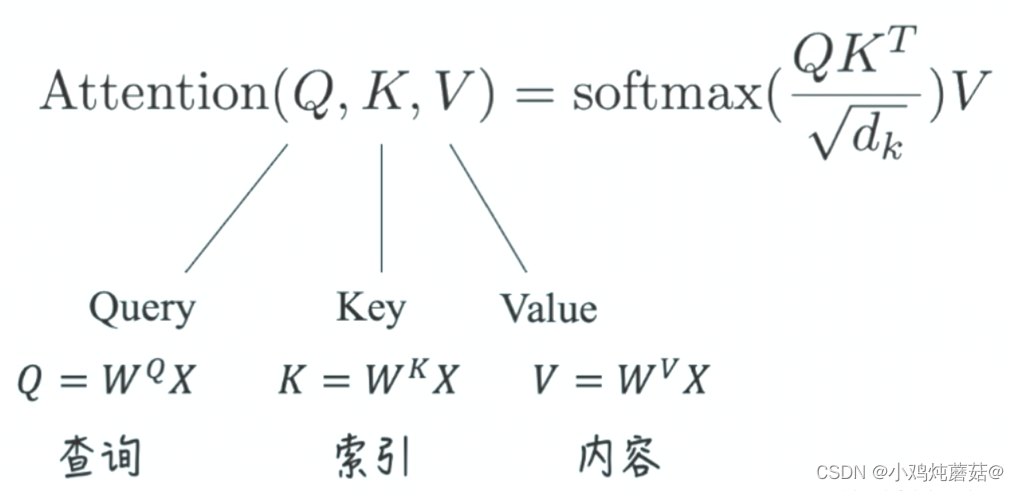
Attention is all you need 这篇文章体现注意力机制的核心就是下面这个公式:
Self-Attention
一、计算框架
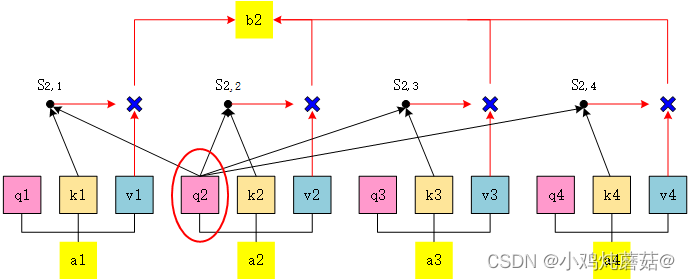
图中,这张图所表示的大致运算过程是:
对于每个token,先产生三个向量query,key,value:
- query向量类比于询问。某个token问:“其余的token都和我有多大程度的相关呀?”
- key向量类比于索引。某个token说:“我把每个询问内容的回答都压缩了下装在我的key里”
- value向量类比于回答。某个token说:“我把我自身涵盖的信息又抽取了一层装在我的value里”
其中以token a2为例,计算过程如下:
- 它产生一个query,每个query都去和别的token的key做“某种方式”的计算,得到的结果我们称为attention score(即为图中的 S )。则一共得到四个attention score。(attention score又可以被称为attention weight)。
- 将这四个score分别乘上每个token的value,我们会得到四个抽取信息完毕的向量。
- 将这四个向量相加,就是最终a2过attention模型后所产生的结果b2。
二、query,key和value的产生过程
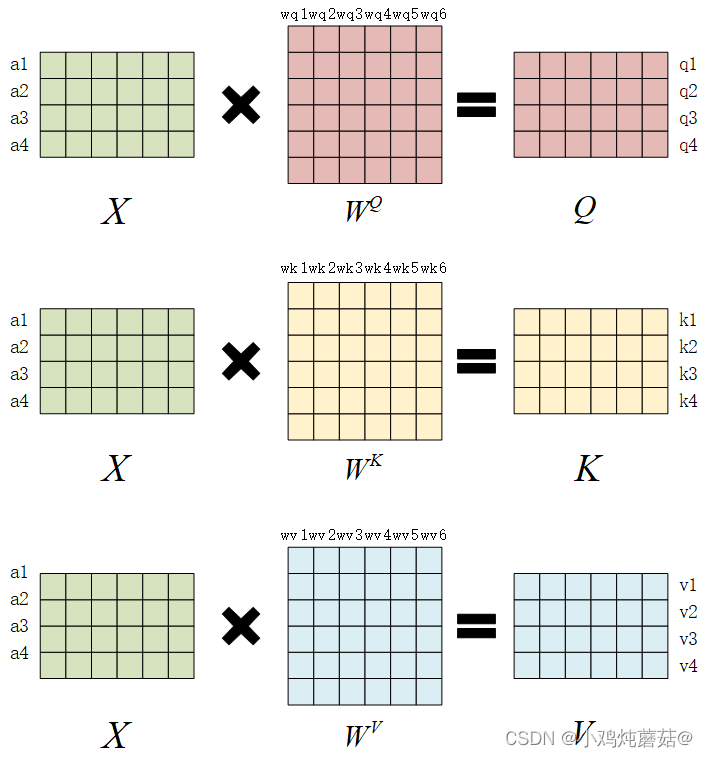
假设batch_size=1,输入序列X的形状为(seq_len = 4, d_model = 6),则对于这串序列,机器在学习过程中产生三个参数矩阵: ,
,
。通过上述的矩阵乘法,我们可以得到最终的结果Q,K,V。
一般来说, WQ 和 WK 都同样使用k_dim, WV 使用v_dim。k_dim和v_dim不一定要相等,但在transformer的原始论文中,采用的策略是,设num_heads为self-attention的头数,则:
k_dim=v_dim=d_model // num_heads
注意,以上图片讲的是注意力头为清的情况。
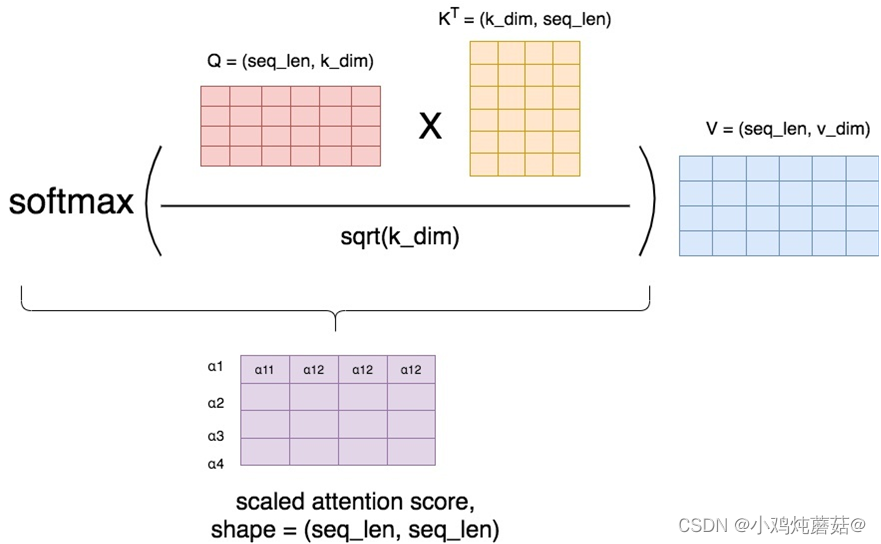
三、计算 attention score
从上面的叙述中我们可以得到Q,K,V的结果,如下:
下面,我们开始计算attention score矩阵,这个矩阵由上面第二幅图中的S组成,最终我们利用V和attention score矩阵计算出注意力层最终的输出结果矩阵,这个矩阵则由上面第二幅图中的b组成。
将最终的输出结果记为Attention(Q, K, V),那么就会得到我们开头提到的那个公式:
其中就是k_dim,
就是attention score矩阵。
常用的计算attention score的方式有两种(两种计算方式的过程展示在下图中),在Attention is all you need这篇论文中,采用的是dot-product(因为不需要额外再去训练一个W矩阵,运算量更小)。
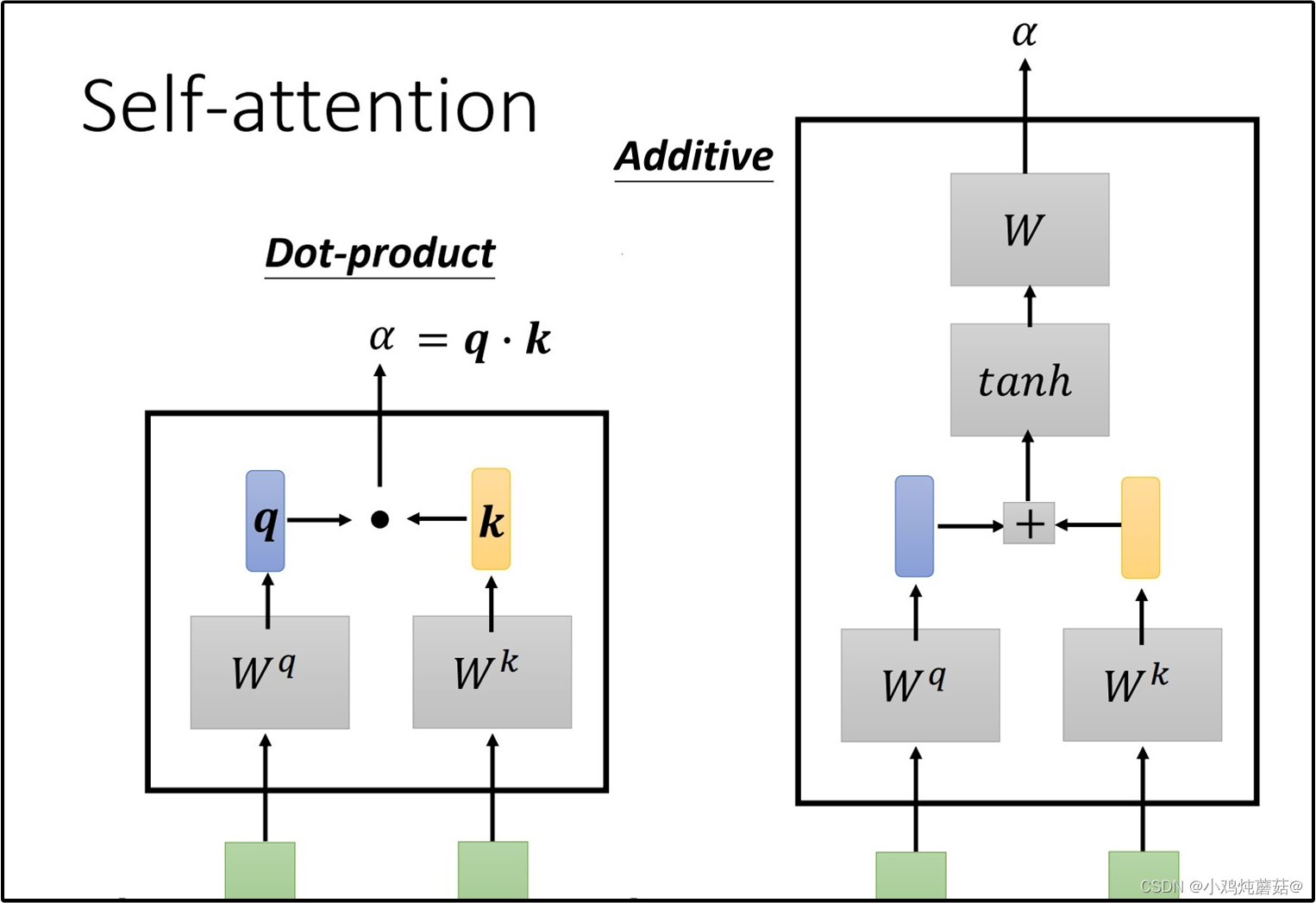
由于乘上了因子,所以论文中准确说的应该是scaled dot-product。在softmax之后,attention score矩阵的每一行表示一个token,每一列表示该token和对应位置token的 α 值,因为进行了softmax,每一行的 权值相加等于1。
公式中乘上因子的原因是为了使得在softmax的过程中,梯度下降得更加稳定,避免因为梯度过小而造成模型参数更新的停滞。
以上就是self-attention的计算过程,下边是两个句子中it与上下文单词的关系热点图,很容易看出来第一个图片中的it与animal关系很强,第二个图it与street关系很强。这个结果说明注意力机制是可以很好地学习到上下文的语言信息。

Masked Attention
在做attention的时候并不是所有情况都希望每个token看到整个序列,在transformer的decoder层我们希望它只能看到左边的序列,所以就需要将右边的序列隐藏(mask)起来。
这样的操作可以防止decoder在解码encoder层输出时“作弊”,提前看到了剩下的答案,因此需要强迫模型根据输入序列左边的结果进行attention。
masked attention的实现过程如下: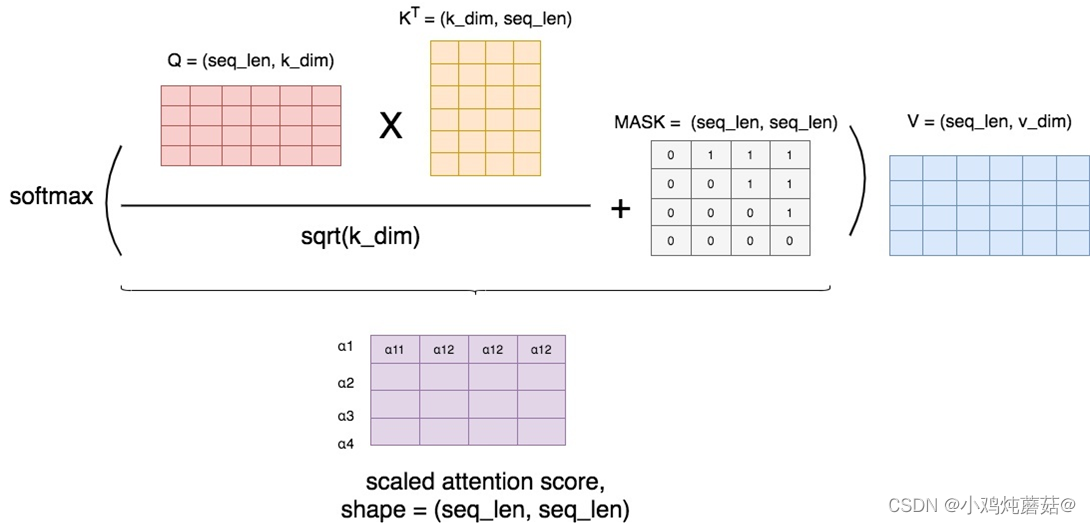
相比于正常计算attention score,这里使用了一个mask矩阵去处理它(这里的+号并不是表示相加,只是表示提供了位置覆盖的信息)。
在mask矩阵标1的地方,也就是需要遮蔽的地方,我们把原来的值替换为一个很小的值(比如-1e09),而在mask矩阵标0的地方,我们保留原始的值。这样,在进softmax的时候,那些被替换的值由于太小,就可以自动忽略不计,从而起到遮蔽的效果。
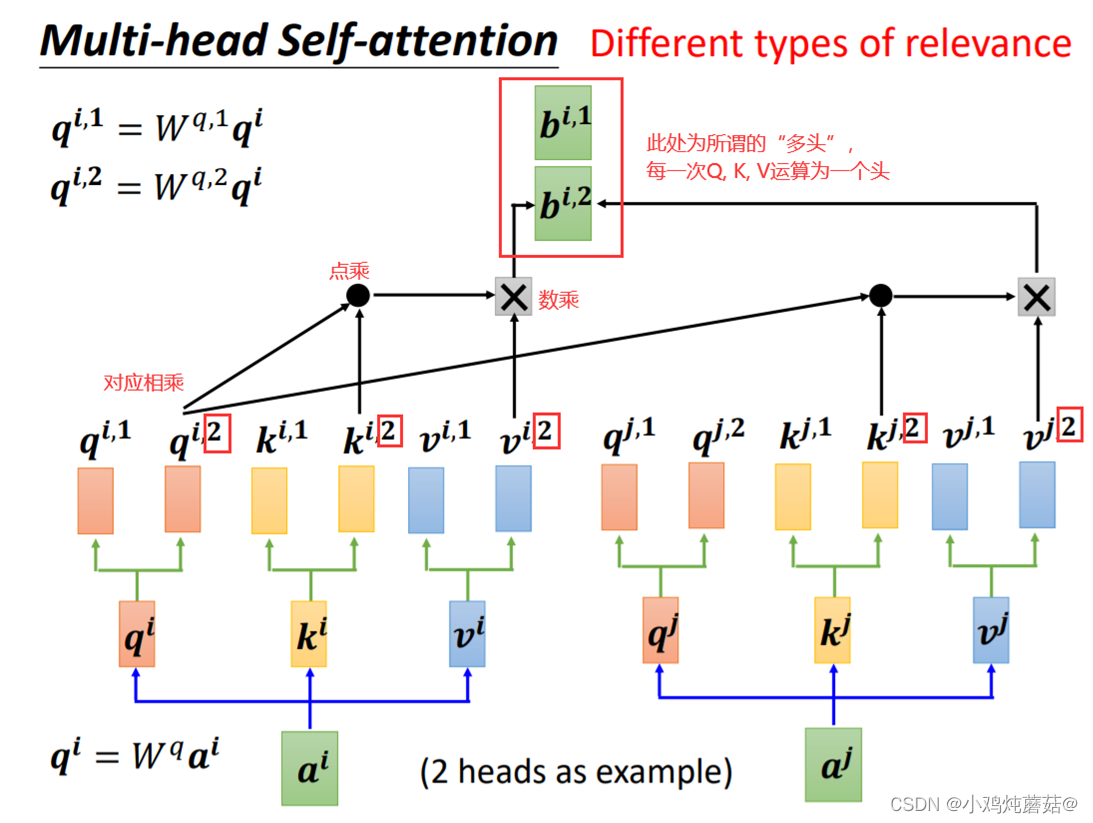
Multihead Attention
图像具有不同的通道,每一个通道可以用来识别一种模式。如果我们对一张图采用attention,比如把这张图的像素格子拉平成一列,那么我们可以对每个像素格子训练不同的head,每个head就类比于一个channel,用于识别不同的模式。
在NLP中,这种模式识别同样重要。比如第一个head用来识别词语间的指代关系,第二个head用于识别词语间的时态关系等等。
下图中展示了Multihead Attention的运行机制,假设头的数量为num_heads,那么本质上,就是训练num_heads个,
,
矩阵,用于生成num_heads个 Q, K, V 结果。每个结果的计算方式和单头的attention的计算方式一致。计算公式如下:
如上述公式,在Multi-head的情况下,输入还是 Q , K , V ,输出是不同head的输出的拼接结果,再投影到 中。其中,对每一个head,可以将 Q , K , V 通过不同的可学习的参数
,
,
投影到一个低维上面,再做注意力函数Attention,最后输出结果。















 1027
1027











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









