







目录
一、mysql优化思路
二、观察服务器周期性变化
虚拟机搭建本地站点 /www/wwwroot/192.168.6.133/index.php
<?
/*
模拟随机选取3万条热数据
取出后存储在memcached
生命周期为5分钟
同时,调整ab参数,尽量在1分钟内完成缓存创建
*/
$id = 13300000 + mt_rand(0,30000);
$sql = 'select log_id,create_uid,room_type,create_time from gold_room_log where log_id =' . $id;
$mem = new memcache();
// $mem->pconnect('localhost');
$mem->connect('localhost', 11211) or die ("Could not connect"); //连接Memcached服务器
if( ($com = $mem->get($sql)) === false) {
$conn = mysqli_connect('127.0.0.1','root','123456');
mysqli_query($conn,'use test');
mysqli_query($conn,'set names utf8');
$rs = mysqli_query($conn,$sql);
$com = mysqli_fetch_assoc($rs);
$mem->add($sql,$com,false,50);
}
print_r($com);

创建脚本统计服务器每秒状态,并执行
[root@localhost 192.168.6.133]# cat tjstatus.sh
#!bash/bin
while true
do
mysqladmin -uroot -p123456 ext|awk '/Queries/{q=$4}/Threads_connected/{c=$4}/Threads_running/{r=$4}END{printf("%d %d %d\n",q,c,r)}' >> status.txt
sleep 1
done
[root@localhost 192.168.6.133]# sh tjstatus.sh
ab测试工具测试网站
[root@localhost 192.168.6.133]# ab -n 400000 -c 50 http://192.168.6.133/index.php
This is ApacheBench, Version 2.3 <$Revision: 1430300 $>
Copyright 1996 Adam Twiss, Zeus Technology Ltd, http://www.zeustech.net/
Licensed to The Apache Software Foundation, http://www.apache.org/
Benchmarking 192.168.6.133 (be patient)
Completed 40000 requests
Completed 80000 requests
Completed 120000 requests
Completed 160000 requests
Completed 200000 requests
Completed 240000 requests
Completed 280000 requests
Completed 320000 requests
Completed 360000 requests
Completed 400000 requests
Finished 400000 requests
Server Software: nginx
Server Hostname: 192.168.6.133
Server Port: 80
Document Path: /index.php
Document Length: 118 bytes
Concurrency Level: 50
Time taken for tests: 216.758 seconds
Complete requests: 400000
Failed requests: 71757
(Connect: 0, Receive: 0, Length: 71757, Exceptions: 0)
Write errors: 0
Total transferred: 108328243 bytes
HTML transferred: 47128243 bytes
Requests per second: 1845.38 [#/sec] (mean)
Time per request: 27.095 [ms] (mean)
Time per request: 0.542 [ms] (mean, across all concurrent requests)
Transfer rate: 488.05 [Kbytes/sec] received
Connection Times (ms)
min mean[+/-sd] median max
Connect: 0 1 1.1 0 39
Processing: 0 26 22.0 23 278
Waiting: 0 26 21.9 22 278
Total: 1 27 22.0 23 286
Percentage of the requests served within a certain time (ms)
50% 23
66% 34
75% 40
80% 44
90% 57
95% 69
98% 83
99% 94
100% 286 (longest request)
查看测试的数据
[root@localhost 192.168.6.133]# awk '{q=$1-last;last=$1}{printf("%d %d %d\n",q,$2,$3)}' status.txt
7813 6 2
20639 12 3
16657 4 1
...
复制数据到excel制成图表

说明
1.查看MySQL运行状态
show status或mysqladmin ext
mysql> show status;
+-----------------------------------------------+-------------+
| Variable_name | Value |
+-----------------------------------------------+-------------+
| Queries | 4827230 | 服务器执行的请求个数,包含存储过程中的请求。
| Threads_connected | 12 | 当前打开的连接的数量。
| Threads_running | 1 | 激活的(非睡眠状态)线程数。
···
[root@iZbp18geqyp8xpk4mvn1v3Z ~]# mysqladmin -uroot -p123456 ext|awk '/Queries/{printf("%d ",$4)}/Threads_connected/{printf("%d ",$4)}/Threads_running/{printf("%s\n",$4)}'
4831608 12 1
[root@iZbp18geqyp8xpk4mvn1v3Z ~]# mysqladmin -uroot -p123456 ext|awk '/Queries/{q=$4}/Threads_connected/{c=$4}/Threads_running/{r=$4}END{printf("%d %d %d\n",q,c,r)}'
190 3 1
AWK一种处理文本文件的语言,文本分析工具。
2.Memcached
一个自由开源的,高性能,分布式内存对象缓存系统
Redhat/Fedora/Centos下安装
yum install libevent libevent-devel 自动下载安装libevent库
yum install memcached 自动安装memcached
查看安装路径
[root@iZbp18geqyp8xpk4mvn1v3Z ~]# whereis memcached
memcached: /usr/bin/memcached /usr/share/man/man1/memcached.1.gz
命令帮助
[root@iZbp18geqyp8xpk4mvn1v3Z ~]# /usr/bin/memcached -h
memcached 1.4.15
作为后台服务程序运行
/usr/local/memcached/bin/memcached -p 11211 -m 64m -d
启动选项:
-d是启动一个守护进程;
-m是分配给Memcache使用的内存数量,单位是MB;
-u是运行Memcache的用户;
-l是监听的服务器IP地址,可以有多个地址;
-p是设置Memcache监听的端口,,最好是1024以上的端口;
-c是最大运行的并发连接数,默认是1024;
-P是设置保存Memcache的pid文件。
启动memcached
[root@iZbp18geqyp8xpk4mvn1v3Z ~]# /usr/bin/memcached -u nobody -m 512 -d
[root@iZbp18geqyp8xpk4mvn1v3Z ~]# ps aux|grep mem
nobody 4563 0.0 0.0 325564 916 ? Ssl 16:02 0:00 /usr/bin/memcached -u nobody -m 512 -d
root 4572 0.0 0.0 112664 968 pts/3 S+ 16:03 0:00 grep --color=auto mem
3.ab测试工具
yum install apr-util 安装依赖包apr-util
yum install yum-utils 安装yumdownload命令
新建一个目录,下载解压
cd /usr/local
mkdir abtmp
cd abtmp
yum install yum-utils.noarch
yumdownloader httpd-tools*
rpm2cpio httpd-tools*.rpm | cpio -idmv
将./user/bin/ab复制到系统bin下
cp /usr/local/abtmp/usr/bin/ab /usr/bin
安装完成
ab –help
参数说明
-n 即requests,用于指定压力测试总共的执行次数。
-c 即concurrency,用于指定 的并发数。
测试本地appach服务器,100个用户同时访问服务器1000次
ab -n 1000 -c 100 localhost/index.php
三、观察mysql进程状态
使用show processlist 和 show profiles 观察mysql状态
show processlist
创建脚本统计mysql状态,并执行
[root@localhost 192.168.6.133]# cat tjproce.sh
while true
do
mysql -uroot -p123456 -e 'show processlist \G'|grep State|uniq|sort -rn >> proce.txt
usleep 100000
done
[root@localhost 192.168.6.133]# sh tjproce.sh
使用sysbench准备数据,执行测试
[root@localhost 192.168.6.133]# sysbench --test=/usr/share/sysbench/tests/include/oltp_legacy/oltp.lua --mysql-table-engine=innodb --mysql-user=root --mysql-password=123456 --db-driver=mysql --mysql-db=test --oltp-table-size=3000 --mysql-sock=/tmp/mysql.sock prepare
WARNING: the --test option is deprecated. You can pass a script name or path on the command line without any options.
sysbench 1.0.20 (using bundled LuaJIT 2.1.0-beta2)
Creating table 'sbtest1'...
Inserting 3000 records into 'sbtest1'
Creating secondary indexes on 'sbtest1'...
[root@localhost 192.168.6.133]# sysbench --test=/usr/share/sysbench/tests/include/oltp_legacy/oltp.lua --mysql-table-engine=innodb --mysql-user=root --mysql-password=123456 --db-driver=mysql --mysql-db=test --oltp-table-size=3000 --mysql-sock=/tmp/mysql.sock run
WARNING: the --test option is deprecated. You can pass a script name or path on the command line without any options.
sysbench 1.0.20 (using bundled LuaJIT 2.1.0-beta2)
Running the test with following options:
Number of threads: 1
Initializing random number generator from current time
Initializing worker threads...
Threads started!
SQL statistics:
queries performed:
read: 56238
write: 16068
other: 8034
total: 80340
transactions: 4017 (401.63 per sec.)
queries: 80340 (8032.68 per sec.)
ignored errors: 0 (0.00 per sec.)
reconnects: 0 (0.00 per sec.)
General statistics:
total time: 10.0005s
total number of events: 4017
Latency (ms):
min: 1.95
avg: 2.49
max: 14.07
95th percentile: 3.13
sum: 9993.39
Threads fairness:
events (avg/stddev): 4017.0000/0.00
execution time (avg/stddev): 9.9934/0.00
获取mysql状态数据
[root@localhost 192.168.6.133]# more proce.txt |sort| uniq -c|sort -rn
1215 State: init
1215 State:
153 State: Sending data
7 State: statistics
5 State: Creating sort index
2 State: System lock
2 State: Opening tables
1 State: Writing to net
1 State: NULL
1 State: Creating tmp table
1 State: closing tables
show profiles
mysql> show variables like '%size%';
+--------------------------------------------------------+----------------------+
| Variable_name | Value |
+--------------------------------------------------------+----------------------+
| tmp_table_size | 134217728 |
...
+--------------------------------------------------------+----------------------+
mysql> set tmp_table_size=1024;
mysql> show variables like '%size%';
+--------------------------------------------------------+----------------------+
| Variable_name | Value |
+--------------------------------------------------------+----------------------+
| tmp_table_size | 1024 |
...
+--------------------------------------------------------+----------------------+
mysql> show variables like '%profiling%';
+------------------------+-------+
| Variable_name | Value |
+------------------------+-------+
| have_profiling | YES |
| profiling | OFF |
| profiling_history_size | 15 |
+------------------------+-------+
mysql> set profiling=1;
mysql> select * from gold_room_log group by log_id%20 order by log_id;
mysql> show profiles;
+----------+-------------+----------------------------------------------------------------+
| Query_ID | Duration | Query |
+----------+-------------+----------------------------------------------------------------+
| 1 | 13.68400425 | select * from gold_room_log group by log_id%20 order by log_id |
+----------+-------------+----------------------------------------------------------------+
mysql> show profile for query 1;
+----------------------+-----------+
| Status | Duration |
+----------------------+-----------+
| starting | 0.000078 |
| checking permissions | 0.000030 |
| Opening tables | 0.000015 |
| init | 0.000018 |
| System lock | 0.000008 |
| optimizing | 0.000006 |
| statistics | 0.000016 |
| preparing | 0.000009 |
| Creating tmp table | 0.000018 |
| Sorting result | 0.000005 |
| executing | 0.000005 |
| Sending data | 13.683629 |
| Creating sort index | 0.000056 |
| end | 0.000009 |
| removing tmp table | 0.000008 |
| end | 0.000006 |
| query end | 0.000007 |
| closing tables | 0.000010 |
| freeing items | 0.000015 |
| logging slow query | 0.000042 |
| cleaning up | 0.000016 |
+----------------------+-----------+
可以观察到mysql执行时间花在Sending data步骤
说明
1.sysbench
- 简介
sysbench (System performance benchmark)是一款开源的多线程性能测试工具,可以执行CPU/内存/线程/IO/数据库等方面的性能测试。
数据库目前支持MySQL/Oracle/PostgreSQL。
- 安装
Github地址:https://github.com/akopytov/sysbench
CentOS安装
curl -s https://packagecloud.io/install/repositories/akopytov/sysbench/script.rpm.sh | sudo bash
sudo yum -y install sysbench
检查安装
[root@localhost ~]# sysbench --version
sysbench 1.0.17
- 使用
常用测试模型
Sysbench通过脚本定义了若干常用的压测模型,以下简单介绍几个常用模型:
| 压测模型 | 描述 |
|---|---|
| bulk_insert.lua | 批量插入数据 |
| insert.lua | 单值插入数据 |
| delete.lua | 删除数据 |
| oltp.lua | 混合读写测试,读写比例14:4 |
| select.lua | 简单的主键查询 |
表结构
测试表的建表语句如下:
CREATE TABLE `sbtest1` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`k` int(11) NOT NULL DEFAULT '0',
`c` char(120) NOT NULL DEFAULT '',
`pad` char(60) NOT NULL DEFAULT '',
PRIMARY KEY (`id`),
KEY `k_1` (`k`)
) ENGINE=InnoDB CHARSET=utf8mb4;
该表会在准备数据阶段自动生成,无需手动创建。
测试命令及参数
使用Sysbench进行压测,通常分为三个步骤:
prepare:准备数据;
run:运行测试模型;
cleanup:清理测试数据。
通常仅需准备一次数据,在此数据基础上测试各种模型即可。
常用参数
Sysbench中常用的参数如下:
--oltp-tables-count=1:表数量。
--oltp-table-size=10000000:每个表产生的记录行数。
--oltp-read-only=off:是否生成只读SQL,默认off,如果设置为on,则oltp模型不会生成update, delete,insert的SQL语句。
--oltp-skip-trx=[on|off]:省略BEGIN/COMMIT语句。默认是off。
--rand-init=on:是否随机初始化数据,如果不随机化那么初始好的数据每行内容除了主键不同外其他完全相同。
--num-threads=12: 并发线程数,可以理解为模拟的客户端并发连接数。
--report-interval=10:表示每10s输出一次性能数据。
--max-requests=0:压力测试产生请求的总数,如果以下面的max-time来记,这个值设为0即可。
--max-time=120:测试的持续时间。
--oltp_auto_inc=off:ID是否为自增列。
--oltp_secondary=on:将ID设置为非主键防止主键冲突。
--oltp_range_size=5: 连续取值5个,必定走到5个分片。
--mysql_table_options='dbpartition by hash(id) tbpartition by hash(id) tbpartitions 2':PolarDB-X 1.0支持拆分表,在建表的时候需要指定拆分方式。
示例命令
准备数据:
sysbench --test=/usr/share/sysbench/tests/include/oltp_legacy/oltp.lua --mysql-table-engine=innodb --mysql-user=root --mysql-password=123456 --db-driver=mysql --mysql-db=test --oltp-table-size=3000 --mysql-sock=/tmp/mysql.sock prepare
执行测试:
sysbench --test=/usr/share/sysbench/tests/include/oltp_legacy/oltp.lua --mysql-table-engine=innodb --mysql-user=root --mysql-password=123456 --db-driver=mysql --mysql-db=test --oltp-table-size=3000 --mysql-sock=/tmp/mysql.sock run
清理环境:
sysbench --test='/usr/local/share/sysbench/oltp.lua' --oltp_tables_count=1 --report-interval=10 --oltp-table-size=10000000 --mysql-user=*** --mysql-password=*** --mysql-table-engine=innodb --rand-init=on --mysql-host=**** --mysql-port=*** --mysql-db=*** --max-time=300 --max-requests=0 --oltp_skip_trx=on --oltp_auto_inc=off --oltp_secondary --oltp_range_size=5 --mysql_table_options='dbpartition by hash(`id`) tbpartition by hash(`id`) tbpartitions 2' --num-threads=200 cleanup
2. show processlist
MySQL 进程列 table 指示服务器内部正在执行的一组线程当前正在执行的操作。SHOW PROCESSLIST 语句是过程信息的一种来源。
show processlist 参数如下,具体参考 MySQL 8.0 参考手册:SHOW PROCESSLIST 语句
id #ID标识
use #当前连接用户
host #显示这个连接从哪个ip的哪个端口上发出
db #数据库名
command #连接状态,一般是休眠(sleep),查询(query),连接(connect)
time #连接持续时间,单位是秒
state #显示当前sql语句的状态
info #显示这个sql语句
关于state参数,具体参考 MySQL 8.0 参考手册: General Thread States
| 状态 | 描述 |
|---|---|
| converting HEAP to ondisk | 该线程正在将内部临时表从 MEMORY 表转换为磁盘表。 |
| Creating tmp table | 正在创建临时表以存放部分查询结果。 |
| Copying to tmp table on disk | 由于临时结果集大于tmp_table_size,正在将临时表从内存存储转为磁盘存储以此节省内存。 |
| Locked | 被其他查询锁住了。 |
| logging slow query | 该线程正在向慢查询日志写入一条语句。 |
| init | 这发生在初始化ALTER TABLE,DELETE,INSERT,SELECT或UPDATE语句之前。服务器在此状态下采取的操作包括刷新二进制日志,InnoDB日志和一些查询缓存清除操作。 |
| Checking table | 正在检查数据表(这是自动的)。 |
| Closing tables | 正在将表中修改的数据刷新到磁盘中,同时正在关闭已经用完的表。这是一个很快的操作,如果不是这样的话,就应该确认磁盘空间是否已经满了或者磁盘是否正处于重负中。 |
| Connect Out | 复制从服务器正在连接主服务器。 |
| deleting from main table | 服务器正在执行多表删除中的第一部分,刚删除第一个表。 |
| deleting from reference tables | 服务器正在执行多表删除中的第二部分,正在删除其他表的记录。 |
| Flushing tables | 正在执行FLUSH TABLES,等待其他线程关闭数据表。 |
| Killed | 发送了一个kill请求给某线程,那么这个线程将会检查kill标志位,同时会放弃下一个kill请求。MySQL会在每次的主循环中检查kill标志位,不过有些情况下该线程可能会过一小段才能死掉。如果该线程程被其他线程锁住了,那么kill请求会在锁释放时马上生效。 |
| Sending data | 正在处理SELECT查询的记录,同时正在把结果发送给客户端。 |
| Sorting for group | 正在为GROUP BY做排序。 |
| Sorting for order | 正在为ORDER BY做排序。 |
| Opening tables | 这个过程应该会很快,除非受到其他因素的干扰。例如,在执ALTER TABLE或LOCK TABLE语句行完以前,数据表无法被其他线程打开。正尝试打开一个表。 |
| Removing duplicates | 正在执行一个SELECT DISTINCT方式的查询,但是MySQL无法在前一个阶段优化掉那些重复的记录。因此,MySQL需要再次去掉重复的记录,然后再把结果发送给客户端。 |
| Reopen table | 获得了对一个表的锁,但是必须在表结构修改之后才能获得这个锁。已经释放锁,关闭数据表,正尝试重新打开数据表。 |
| Repair by sorting | 修复指令正在排序以创建索引。 |
| Repair with keycache | 修复指令正在利用索引缓存一个一个地创建新索引。它会比Repair by sorting慢些。 |
| Searching rows for update | 正在讲符合条件的记录找出来以备更新。它必须在UPDATE要修改相关的记录之前就完成了。 |
| Sleeping | 正在等待客户端发送新请求. |
| System lock | 正在等待取得一个外部的系统锁。如果当前没有运行多个mysqld服务器同时请求同一个表,那么可以通过增加–skip-external-locking参数来禁止外部系统锁。 |
| Upgrading lock | INSERT DELAYED正在尝试取得一个锁表以插入新记录。 |
| Updating | 正在搜索匹配的记录,并且修改它们。 |
| User Lock | 正在等待GET_LOCK()。 |
| Waiting for tables | 该线程得到通知,数据表结构已经被修改了,需要重新打开数据表以取得新的结构。然后,为了能的重新打开数据表,必须等到所有其他线程关闭这个表。以下几种情况下会产生这个通知:FLUSH TABLES tbl_name, ALTER TABLE, RENAME TABLE, REPAIR TABLE, ANALYZE TABLE,或OPTIMIZE TABLE。 |
| waiting for handler insert | INSERT DELAYED已经处理完了所有待处理的插入操作,正在等待新的请求。 |
3. show profiles
具体参考 MySQL 8.0 参考手册:SHOW PROFILE Statement
查看profiling状态 show variables like '%profiling%'
mysql> show variables like '%profiling%';
+------------------------+-------+
| Variable_name | Value |
+------------------------+-------+
| have_profiling | YES |
| profiling | OFF |
| profiling_history_size | 15 |
+------------------------+-------+
3 rows in set (0.00 sec)
开启profiling set profiling=1|ON
mysql> set profiling=ON;
Query OK, 0 rows affected, 1 warning (0.00 sec)
mysql> set profiling=1;
Query OK, 0 rows affected, 1 warning (0.00 sec)
查看mysql 执行情况 show profiles
mysql> show profiles;
+----------+-------------+----------------------------------------------------------------+
| Query_ID | Duration | Query |
+----------+-------------+----------------------------------------------------------------+
| 1 | 13.68400425 | select * from gold_room_log group by log_id%20 order by log_id |
| 2 | 0.00006625 | show profiles for query 1 |
| 3 | 0.00731550 | select * from gold_room_log limit 10000 |
| 4 | 1.36444225 | select * from gold_room_log limit 1000000 |
+----------+-------------+----------------------------------------------------------------+
4 rows in set, 1 warning (0.00 sec)
查看指定mysql语句执行情况 show profile for query Query_ID
mysql> show profile for query 4;
+----------------------+----------+
| Status | Duration |
+----------------------+----------+
| starting | 0.000052 |
| checking permissions | 0.000012 |
| Opening tables | 0.000015 |
| init | 0.000014 |
| System lock | 0.000009 |
| optimizing | 0.000006 |
| statistics | 0.000012 |
| preparing | 0.000009 |
| executing | 0.000005 |
| Sending data | 1.364235 |
| end | 0.000031 |
| query end | 0.000010 |
| closing tables | 0.000011 |
| freeing items | 0.000009 |
| cleaning up | 0.000014 |
+----------------------+----------+
15 rows in set, 1 warning (0.00 sec)
查看CPU开销
mysql> show profile cpu for query 4;
+----------------------+----------+----------+------------+
| Status | Duration | CPU_user | CPU_system |
+----------------------+----------+----------+------------+
| starting | 0.000052 | 0.000040 | 0.000000 |
| checking permissions | 0.000012 | 0.000009 | 0.000000 |
| Opening tables | 0.000015 | 0.000015 | 0.000000 |
| init | 0.000014 | 0.000013 | 0.000000 |
| System lock | 0.000009 | 0.000009 | 0.000000 |
| optimizing | 0.000006 | 0.000007 | 0.000000 |
| statistics | 0.000012 | 0.000012 | 0.000000 |
| preparing | 0.000009 | 0.000009 | 0.000000 |
| executing | 0.000005 | 0.000004 | 0.000000 |
| Sending data | 1.364235 | 0.598206 | 0.000000 |
| end | 0.000031 | 0.000015 | 0.000000 |
| query end | 0.000010 | 0.000008 | 0.000000 |
| closing tables | 0.000011 | 0.000011 | 0.000000 |
| freeing items | 0.000009 | 0.000009 | 0.000000 |
| cleaning up | 0.000014 | 0.000014 | 0.000000 |
+----------------------+----------+----------+------------+
15 rows in set, 1 warning (0.00 sec)
四、列选取原则
表的优化与列选取原则
列选取原则
1.字段类型优先级:整形 > date,time > enum,char,varchar > blob
原因:
整形,time运算速度快,节省空间
char,varchar 要考虑字符集的转换与排序时的校对集,速度慢
blob 无法使用内存临时表
2.字段长度尽量简短使用
原因:大的字段浪费内存,影响速度
如varchar(100),varchar(300)存储的内容相同,但在表联查时varchar(300)要花更多内存
3.尽量避免使用null
原因:null不利于索引,要用特殊字节来标注,在磁盘上占用的空间其实更大
实验:
可以建两张相同的表,一个允许null,一个不允许null,各加入1万条数据,查看索引文件大小,可以发现为null的文件要大些
mysql> use test
Database changed
mysql> create table t1 (
-> name char(1) not null default '',
-> key(name)
-> )engine innodb charset utf8;
Query OK, 0 rows affected (0.08 sec)
mysql> create table t2(
-> name char(1),
-> key(name)
-> )engine innodb charset utf8;
Query OK, 0 rows affected (0.02 sec)
mysql> insert into t1 values('a'),('');
Query OK, 2 rows affected (0.01 sec)
Records: 2 Duplicates: 0 Warnings: 0
mysql> insert into t2 values('a'),(null);
Query OK, 2 rows affected (0.00 sec)
Records: 2 Duplicates: 0 Warnings: 0
mysql> explain select * from t1 where name='a';
+----+-------------+-------+------+---------------+------+---------+-------+------+--------------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+------+---------------+------+---------+-------+------+--------------------------+
| 1 | SIMPLE | t1 | ref | name | name | 3 | const | 1 | Using where; Using index |
+----+-------------+-------+------+---------------+------+---------+-------+------+--------------------------+
1 row in set (0.00 sec)
mysql> explain select * from t2 where name='a';
+----+-------------+-------+------+---------------+------+---------+-------+------+--------------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+------+---------------+------+---------+-------+------+--------------------------+
| 1 | SIMPLE | t2 | ref | name | name | 4 | const | 1 | Using where; Using index |
+----+-------------+-------+------+---------------+------+---------+-------+------+--------------------------+
1 row in set (0.00 sec)
可以看到使用null的字段多了一个长度,因为要多用一个字节来存储null
enum列的说明
1.enum列在内部使用整形来存储的
2.enum列与enum列关联速度最快
3.enum列与(var)char比较:
弱势,与char关联时要花时间转化
优势,当char非常长时,enum依然是整形固定长度,查询数据量越大,优势越明显
4.enum列与var(char)关联,因为要转化,速度比 enum->enum,char->char 慢
但有时也这样用,在数据量特别大是可以节省 IO.
| 列<->列 | 时间 |
|---|---|
| enum<->enum | 10.53 |
| char<->char | 24.65 |
| varchar<->varchar | 24.04 |
| enum<->char | 18.22 |
可以看到enum和enum类型关联速度比较快
五、多列索引生效规则
索引优化策略
-
索引类型
1.1 B-tree索引
注:名叫btree索引,大的方面看,都用平衡树,但具体实现上,各引擎稍有不同。
比如严格的说,NDB引擎使用的是T-tree,myisam,innodb使用的是B-tree索引。
B-tree系统可以理解为“排好序的快速查找结构”1.2 hash索引
在memory表里,默认是hash索引,hash索引理论查询时间复杂度为O(1)
疑问:既然hash查找如此高效,为什么不都用hash索引?
答:
1.hash函数计算后的结果是随机的,如果在磁盘上放置数据,
比如主键是id为例,随着id的增长,id对应的行,在磁盘上随机放置
2.无法对范围查询进行优化
3.无法利用前缀索引。比如在btree中,field列的值“helloworld”,并加索引查询xx=helloworld,自然可以利用索引,xx=hello,也可以利用索引(左前缀索引)。因为hash(‘helloworld’),hash(‘hello’),两者的关系仍为随机
4.无法优化排序
5.必须回行。就是说,通过索引拿到数据位置,必须回到表中取数据 -
btree索引的常见误区
2.1 在where条件常用的列上都加上索引
例:where id = 1 and price = 2 ,对id和peice都建立索引,只能使用一个2.2 在多列上建立索引后,查询哪个列,索引都将发挥作用
误:多列索引上,索引发挥作用,需要满足左前缀要求以 index(a,b,c) 为例
语句 索引是否有效 where a=1 是 where a=1 and b= 2 是 where a=1 and b= 2 and c= 3 是 where b=2 或 where c= 3 否 where a=1 and c= 2 a是,c否 where a=1 and b>2 and c= 3 a,b是,c否 where a=1 and b like ‘%2%’ and c =3 a,b是,c否 2.3 示例
mysql> SHOW CREATE TABLE t5 \G; *************************** 1. row *************************** Table: t5 Create Table: CREATE TABLE `t5` ( `id` int(11) unsigned NOT NULL AUTO_INCREMENT, `c1` tinyint(1) NOT NULL DEFAULT '0', `c2` tinyint(1) NOT NULL DEFAULT '0', `c3` tinyint(1) NOT NULL DEFAULT '0', `c4` tinyint(1) NOT NULL DEFAULT '0', `c5` tinyint(1) NOT NULL DEFAULT '0', `str` varchar(255) NOT NULL, PRIMARY KEY (`id`), KEY `c1234` (`c1`,`c2`,`c3`,`c4`) USING BTREE, KEY `str` (`str`) ) ENGINE=InnoDB AUTO_INCREMENT=4 DEFAULT CHARSET=utf8假设某表有一个联合索引(c1,c2,c3,c4),写出生效的索引
A.where c1 = x and c2 = x and c4 > x and c3 = x (c1,c2,c3,c4)
mysql> explain select * from t5 where c1 = 1 and c2 = 1 and c4 > 1 and c3 = 1; +----+-------------+-------+-------+---------------+-------+---------+------+------+-----------------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+-------+-------+---------------+-------+---------+------+------+-----------------------+ | 1 | SIMPLE | t5 | range | c1234 | c1234 | 4 | NULL | 1 | Using index condition | +----+-------------+-------+-------+---------------+-------+---------+------+------+-----------------------+B.where c1 = x and c2 = x and c4 = x order by c3(c1,c2,c3)
mysql> explain select * from t5 where c1 = 1 and c2 = 1 and c4 = 1 order by c3; +----+-------------+-------+------+---------------+-------+---------+-------------+------+------------------------------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+-------+------+---------------+-------+---------+-------------+------+------------------------------------+ | 1 | SIMPLE | t5 | ref | c1234 | c1234 | 2 | const,const | 1 | Using index condition; Using where | +----+-------------+-------+------+---------------+-------+---------+-------------+------+------------------------------------+c1,c2使用索引,而c3使用索引排序
mysql> explain select * from t5 where c1 = 1 and c2 = 1 and c4 = 1 order by c5; +----+-------------+-------+------+---------------+-------+---------+-------------+------+----------------------------------------------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+-------+------+---------------+-------+---------+-------------+------+----------------------------------------------------+ | 1 | SIMPLE | t5 | ref | c1234 | c1234 | 2 | const,const | 1 | Using index condition; Using where; Using filesort | +----+-------------+-------+------+---------------+-------+---------+-------------+------+----------------------------------------------------+排序的字段换成非索引c5,可以看到extra参数多出了Using filesort ,意思为查询的结果还需要排序
C.where c1 = x and c4 = x group by c2,c3(c1,c2,c3)
mysql> explain select * from t5 where c1 = 1 and c4 =1 group by c2,c3; +----+-------------+-------+------+---------------+-------+---------+-------+------+------------------------------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+-------+------+---------------+-------+---------+-------+------+------------------------------------+ | 1 | SIMPLE | t5 | ref | c1234 | c1234 | 1 | const | 1 | Using index condition; Using where | +----+-------------+-------+------+---------------+-------+---------+-------+------+------------------------------------+c1使用了索引,c2,c3使用了索引排序
mysql> explain select * from t5 where c1 = 1 and c4 =1 group by str; +----+-------------+-------+------+---------------+-------+---------+-------+------+---------------------------------------------------------------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+-------+------+---------------+-------+---------+-------+------+---------------------------------------------------------------------+ | 1 | SIMPLE | t5 | ref | c1234,str | c1234 | 1 | const | 1 | Using index condition; Using where; Using temporary; Using filesort | +----+-------------+-------+------+---------------+-------+---------+-------+------+---------------------------------------------------------------------+一般而言,分组统计要使用临时表按分组字段有序排列。 Using temporary; Using filesort
D.where c1 = ? and c5 = ? order by c2,c3(c1,c2,c3)
mysql> explain select * from t5 where c1 = 1 and c5 = 1 order by c2,c3; +----+-------------+-------+------+---------------+-------+---------+-------+------+-------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+-------+------+---------------+-------+---------+-------+------+-------------+ | 1 | SIMPLE | t5 | ref | c1234 | c1234 | 1 | const | 1 | Using where | +----+-------------+-------+------+---------------+-------+---------+-------+------+-------------+c1使用了索引,c2,c3使用了索引排序
mysql> explain select * from t5 where c1 = 1 and c5 = 1 order by c3,c2; +----+-------------+-------+------+---------------+-------+---------+-------+------+-----------------------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+-------+------+---------------+-------+---------+-------+------+-----------------------------+ | 1 | SIMPLE | t5 | ref | c1234 | c1234 | 1 | const | 1 | Using where; Using filesort | +----+-------------+-------+------+---------------+-------+---------+-------+------+-----------------------------+排序的字段顺序换成c3,c2,因为没有遵循左前缀原则,所以索引无效,出现Using filesort
E.where c1 = ? and c2 = ? and c5 = ? order by c2,c3(c1,c2,c3)
mysql> explain select * from t5 where c1 = 1 and c2 =1 and c5 = 1 order by c2,c3; +----+-------------+-------+------+---------------+-------+---------+-------------+------+-------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+-------+------+---------------+-------+---------+-------------+------+-------------+ | 1 | SIMPLE | t5 | ref | c1234 | c1234 | 2 | const,const | 1 | Using where | +----+-------------+-------+------+---------------+-------+---------+-------------+------+-------------+mysql> explain select * from t5 where c1 = 1 and c2 =1 and c5 = 1 order by c3,c2; +----+-------------+-------+------+---------------+-------+---------+-------------+------+-------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+-------+------+---------------+-------+---------+-------------+------+-------------+ | 1 | SIMPLE | t5 | ref | c1234 | c1234 | 2 | const,const | 1 | Using where | +----+-------------+-------+------+---------------+-------+---------+-------------+------+-------------+ 1 row in set (0.00 sec)c1,c2使用索引,c3使用索引排序。排序字段c2可以看做一个常量,c2,c3的顺序对索引无影响
索引失效的条件
- 在索引列上做计算、使用函数、类型转换等操作
- 范围条件右边的列(非左前缀原则)
- 使用不等于,is null,is not null 等
- 通配符like查询(可使用覆盖索引的方式解决)
- 字符串索引不加引号
六、聚簇索引,索引覆盖
-
聚簇索引概念
innodb的主索引文件上,直接存放该行数据,称为聚簇索引,次索引指向对主键的引用
myisam中,主索引和次索引都指向物理行对innodb来说,
1.主索引文件,既存储索引值,又在叶子中存储行的数据
2.如果没有主键,则会unique key做主键
3.如果没有unique,则系统生成一个内部的rowid做主键
4.像innodb中,主键的索引文件,既存储了主键值,又存储了行数据,这种结构称为“聚簇索引”

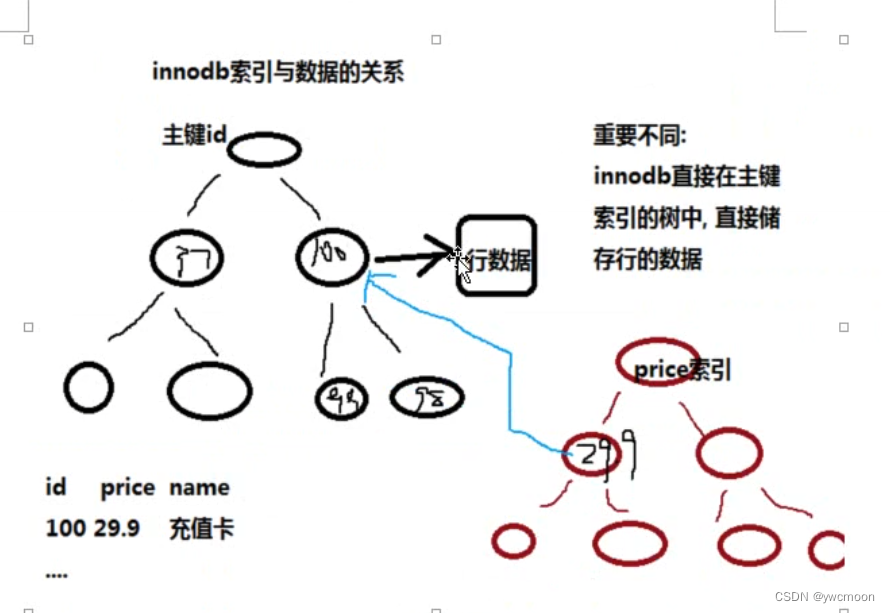
-
聚簇索引随机主键值的效率
对innodb而言,因为节点下有数据文件,因此节点的分裂将会比较慢
对于innodb的主键,尽量用递增的整型
如果是无规律的数据,将会产生叶的分裂,影响速度
测试
规律的插入数据
[root@localhost 192.168.6.133]# cat /www/wwwroot/192.168.6.133/innodb/grow.php
<?php
/*
CREATE TABLE `split` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(200) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
*/
set_time_limit(0);
$conn = mysqli_connect('127.0.0.1','root','123456');
mysqli_query($conn,'use test');
mysqli_query($conn,'set names utf8');
$str = 'abcdefghijklmnopqrstuvwxyz0123456789';
$str = str_shuffle($str).str_shuffle($str).str_shuffle($str);
$str = $str.$str;
$arr = range(1,1000001,1000);
shuffle($arr);
$start = microtime_float();
foreach($arr as $i){
$sql = sprintf("insert into split1 values(%d,'%s','%s','%s','%s','%s','%s','%s','%s','%s','%s')",$i,$str,$str,$str,$str,$str,$str,$str,$str,$str,$str);
// echo $sql."<br/>";
if(!mysqli_query($conn,$sql)){
echo $i."failure<br/>";
}
}
$end = microtime_float();
echo "随机插入1K行的时间为",$end - $start,"秒\n";
mysqli_close($conn);
function microtime_float(){
list($usec,$sec) = explode(" ",microtime());
return ((float) $usec + (float) $sec);
}
[root@localhost 192.168.6.133]# /usr/bin/php /www/wwwroot/192.168.6.133/innodb/grow.php
随机插入1K行的时间为28.376071929932秒
无规律的插入数据
[root@localhost 192.168.6.133]# cat /www/wwwroot/192.168.6.133/innodb/rand.php
<?php
/*
CREATE TABLE `split` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(200) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
*/
set_time_limit(0);
$conn = mysqli_connect('127.0.0.1','root','123456');
mysqli_query($conn,'use test');
mysqli_query($conn,'set names utf8');
$str = 'abcdefghijklmnopqrstuvwxyz0123456789';
$str = str_shuffle($str).str_shuffle($str).str_shuffle($str);
$str = $str.$str;
$start = microtime_float();
for($i = 1;$i<=1000;$i++){
$sql = sprintf("insert into split2 values(%d,'%s','%s','%s','%s','%s','%s','%s','%s','%s','%s')",$i,$str,$str,$str,$str,$str,$str,$str,$str,$str,$str);
// echo $sql."<br/>";
if(!mysqli_query($conn,$sql)){
echo $i."failure<br/>";
}
}
$end = microtime_float();
echo "随机插入1K行的时间为",$end - $start,"秒\n";
mysqli_close($conn);
function microtime_float(){
list($usec,$sec) = explode(" ",microtime());
return ((float) $usec + (float) $sec);
}
[root@localhost 192.168.6.133]# /usr/bin/php /www/wwwroot/192.168.6.133/innodb/rand.php
随机插入1K行的时间为42.948094129562秒
可以看到乱序插入数据时间更长
- 索引覆盖
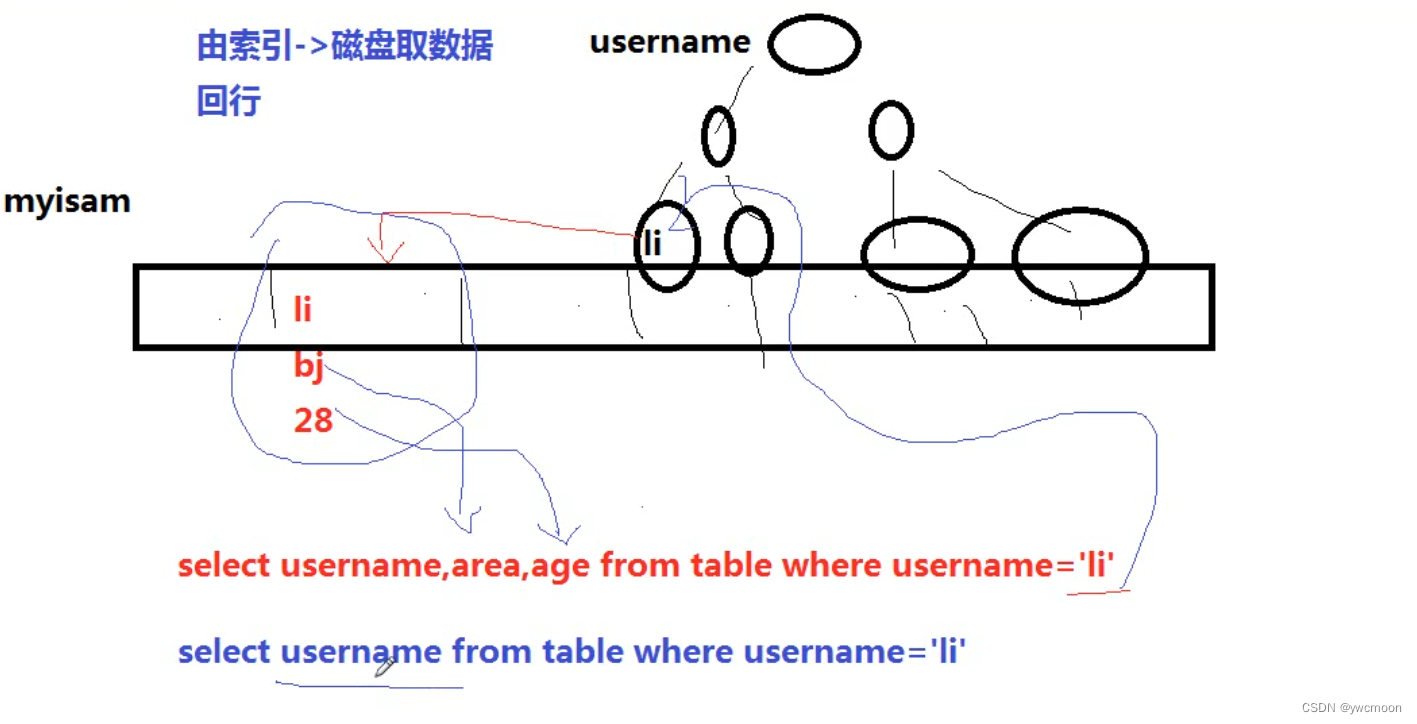
索引覆盖是指,如果查询的列恰好是索引的一部分,那么查询只需要在文件上进行,不需要回行到磁盘上找数据
这种查询速度非常快,称为覆盖索引
测试
mysql> set profiling=1;
mysql> explain select c1 from t5 ;
+----+-------------+-------+-------+---------------+-------+---------+------+------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+-------+---------------+-------+---------+------+------+-------------+
| 1 | SIMPLE | t5 | index | NULL | c1234 | 4 | NULL | 3 | Using index |
+----+-------------+-------+-------+---------------+-------+---------+------+------+-------------+
mysql> explain select c5 from t5 ;
+----+-------------+-------+------+---------------+------+---------+------+------+-------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+------+---------------+------+---------+------+------+-------+
| 1 | SIMPLE | t5 | ALL | NULL | NULL | NULL | NULL | 3 | NULL |
+----+-------------+-------+------+---------------+------+---------+------+------+-------+
mysql> show profiles;
+----------+------------+---------------------------+
| Query_ID | Duration | Query |
+----------+------------+---------------------------+
| 1 | 0.00016650 | explain select c5 from t5 |
| 2 | 0.00011200 | explain select c1 from t5 |
+----------+------------+---------------------------+
Extra出现Using index,说明使用了覆盖索引,可以看到使用覆盖索引的查询速度更快
七、聚簇索引慢案例分析
问题:
create table A(
id varchar(64) primary key,
ver int,
…
)
在id和ver上有联合索引,10000条数据,表里有几个很长的字段varbinary(3000)
为什么 select id from A order by id 特别慢?而 select id from A order by id,ver 非常快
答:
1.是innodb引擎的聚簇索引,导致沿id排序时,要跨好多小文件块
2.有多个比较长的列,导致块比较多
原因分析:
id是主键索引,innodb的聚簇索引每个叶子下都有数据,当数据长度过大,查询时会在索引文件上跨很多块,所以查询慢.
而复合索引idver不是主键索引,索引文件指向的是主键索引的id,内容比较小。同时取的字段只有id,不需要回行去主键索引的数据块中取数据,只要按照复合索引的文件走就可以了,所以比较快
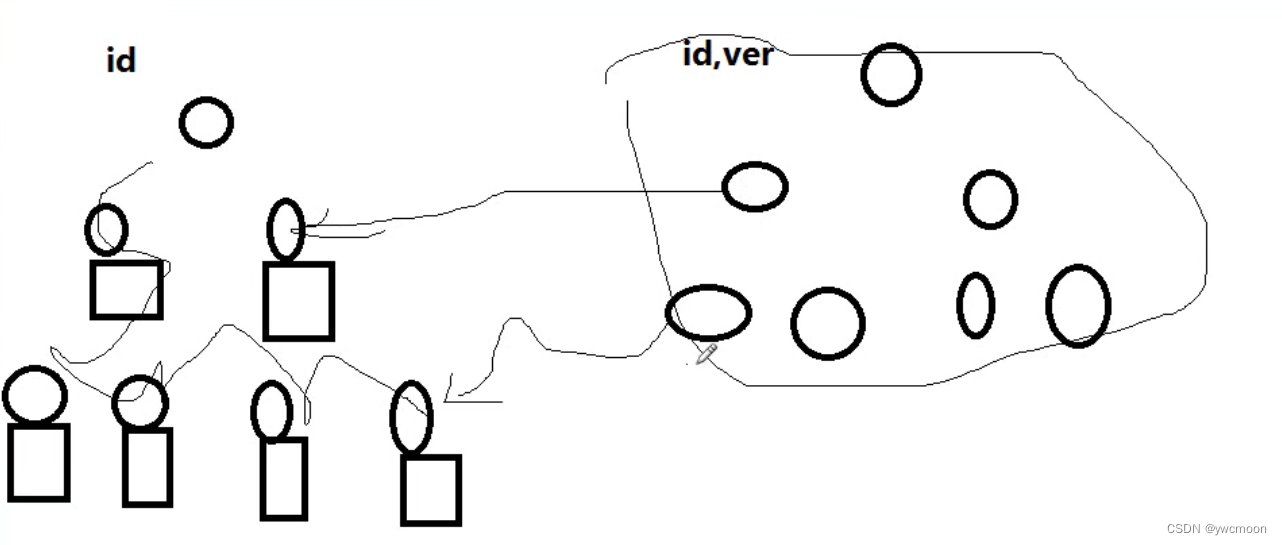
推断1:如果是myisam将不存在这个问题
推断2:如果没有几个过长的char字段,差别也不会这么大
-
测试推断1:如果是myisam将不存在这个问题
创建myisam引擎的表,插入1w条数据,测试查询时间
[root@localhost test]# cat /www/wwwroot/192.168.6.133/test/myisam.php <?php $con = mysqli_connect('127.0.0.1','root','123456'); mysqli_query($con,'use test'); mysqli_query($con,'set name utf8'); $str = str_repeat('a',3000); for($i=1;$i<=10000;$i++){ $id = dechex($i); $sql = sprintf("insert into t7 values('%s',%d,'%s','%s','%s')",$i,$i,$str,$str,$str); //echo $sql,"\n"; mysqli_query($con,$sql); } echo 'ok'; [root@localhost test]# /usr/bin/php /www/wwwroot/192.168.6.133/test/myisam.php okmysql> show create table t7 \G; *************************** 1. row *************************** Table: t7 Create Table: CREATE TABLE `t7` ( `id` char(64) NOT NULL, `ver` int(11) NOT NULL DEFAULT '0', `str1` varchar(3000) DEFAULT NULL, `str2` varchar(3000) DEFAULT NULL, `str3` varchar(3000) DEFAULT NULL, PRIMARY KEY (`id`), KEY `idver` (`id`,`ver`) ) ENGINE=MyISAM DEFAULT CHARSET=utf8 mysql> set profiling=1; mysql> select id from t7 order by id; mysql> select id from t7 order by id,ver; mysql> show profiles; +----------+------------+-----------------------------------+ | Query_ID | Duration | Query | +----------+------------+-----------------------------------+ | 1 | 0.00247800 | select id from t7 order by id | | 2 | 0.00264875 | select id from t7 order by id,ver | +----------+------------+-----------------------------------+可以看到myisam引擎的sql查询时间,相差不大
换innodb引擎的表,一样的测试
[root@localhost test]# cat /www/wwwroot/192.168.6.133/test/innodb.php <?php $con = mysqli_connect('127.0.0.1','root','123456'); mysqli_query($con,'use test'); mysqli_query($con,'set name utf8'); $str = str_repeat('a',3000); for($i=1;$i<=10000;$i++){ $id = dechex($i); $sql = sprintf("insert into t6 values('%s',%d,'%s','%s','%s')",$i,$i,$str,$str,$str); //echo $sql,"\n"; mysqli_query($con,$sql); } echo 'ok'; [root@localhost test]# /usr/bin/php /www/wwwroot/192.168.6.133/test/myisam.php okmysql> show create table t6 \G; *************************** 1. row *************************** Table: t6 Create Table: CREATE TABLE `t6` ( `id` char(64) NOT NULL, `ver` int(11) NOT NULL DEFAULT '0', `str1` varchar(3000) DEFAULT NULL, `str2` varchar(3000) DEFAULT NULL, `str3` varchar(3000) DEFAULT NULL, PRIMARY KEY (`id`), KEY `idver` (`id`,`ver`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8 mysql> set profiling=1; mysql> select id from t6 order by id; mysql> select id from t6 order by id,ver; mysql> show profiles; +----------+------------+-----------------------------------+ | Query_ID | Duration | Query | +----------+------------+-----------------------------------+ | 1 | 0.00610125 | select id from t6 order by id | | 2 | 0.00273175 | select id from t6 order by id,ver | +----------+------------+-----------------------------------+可以看到Innodb引擎的sql查询时间,有了量级的差别
-
测试推断2:如果没有几个过长的char字段,差别也不会这么大
测试去除长字段的查询时间
mysql> alter table t6 drop column str1; mysql> alter table t6 drop column str2; mysql> alter table t6 drop column str3; mysql> desc t6; +-------+----------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +-------+----------+------+-----+---------+-------+ | id | char(64) | NO | PRI | NULL | | | ver | int(11) | NO | | 0 | | +-------+----------+------+-----+---------+-------+ mysql> select id from t6 order by id; mysql> select id from t6 order by id,ver; mysql> show profiles; +----------+------------+-----------------------------------+ | 1| 0.00287300 | select id from t6 order by id | | 2| 0.00261775 | select id from t6 order by id,ver | +----------+------------+-----------------------------------+可以看到,两者的查询相差不大
-
把id改为递增整型,再测试
mysql> alter table t6 modify id int(11) auto_increment; mysql> desc t6; +-------+---------+------+-----+---------+----------------+ | Field | Type | Null | Key | Default | Extra | +-------+---------+------+-----+---------+----------------+ | id | int(11) | NO | PRI | NULL | auto_increment | | ver | int(11) | NO | | 0 | | +-------+---------+------+-----+---------+----------------+ mysql> select id from t6 order by id; mysql> select id from t6 order by id,ver; mysql> show profiles; +----------+------------+-----------------------------------+ | Query_ID | Duration | Query | +----------+------------+-----------------------------------+ | 1 | 0.00252575 | select id from t6 order by id | | 2 | 0.00227500 | select id from t6 order by id,ver | +----------+------------+-----------------------------------+可以看到查询时间更短
八、索引长度与区分度
理想的索引
1.查询频繁
2.区分度高
3.长度小
4.尽量能覆盖常用查询字段
-
索引长度直接影响索引文件的大小,影响增删改的速度,并间接影响查询速度(占用内存多)
针对列中的值,从左往右截取部分来建索引
1.截的越短,重复度越高,区分度越小,索引效果不好
2.截的越长,重复度越低,区分度越高,索引效果越好,但带来的影响也越大-增删改变慢,并间接影响查询速度所以,要在 区分度+长度 两者上取得一个平衡
惯用手法:截取不同长度,并测试其区分度
mysql> select uid,name,length(name) from user order by length(name) desc limit 1; +---------+-------------------------------------------------------------------+--------------+ | uid | name | length(name) | +---------+-------------------------------------------------------------------+--------------+ | 1733863 | 贵州运满来物流有限公司,蔡回筠,电话13608541671 | 65 | +---------+-------------------------------------------------------------------+--------------+ mysql> select count(distinct left(name,1)) from user; +------------------------------+ | count(distinct left(name,1)) | +------------------------------+ | 5638 | +------------------------------+ mysql> select count(*) from user; +----------+ | count(*) | +----------+ | 305188 | +----------+ mysql> select count(distinct left(name,1))/count(*) from user; +---------------------------------------+ | count(distinct left(name,1))/count(*) | +---------------------------------------+ | 0.0185 | +---------------------------------------+ mysql> select count(distinct left(name,2))/count(*) from user; +---------------------------------------+ | count(distinct left(name,2))/count(*) | +---------------------------------------+ | 0.2153 | +---------------------------------------+ mysql> select count(distinct left(name,3))/count(*) from user; +---------------------------------------+ | count(distinct left(name,3))/count(*) | +---------------------------------------+ | 0.3611 | +---------------------------------------+ ... mysql> select count(distinct left(name,65))/count(*) from user; +---------------------------------------+ | count(distinct left(name,3))/count(*) | +---------------------------------------+ | 1 | +---------------------------------------+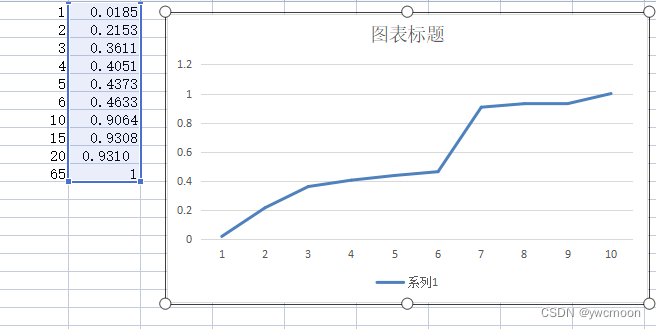
对于一般系统应用,区别度能达到1,索引性能就可以接受mysql> alter table user add index name(name(10)); mysql> show create table user \G; *************************** 1. row *************************** Table: user Create Table: CREATE TABLE `user` ( `uid` int(11) NOT NULL AUTO_INCREMENT COMMENT '用户id', `name` varchar(32) DEFAULT NULL COMMENT '姓名', ... PRIMARY KEY (`uid`) USING BTREE, KEY `name` (`name`(10)) ) ENGINE=InnoDB AUTO_INCREMENT=1850120 DEFAULT CHARSET=utf8 COMMENT='用户表' mysql> explain select * from user where name='中' \G; *************************** 1. row *************************** id: 1 select_type: SIMPLE table: user type: ref possible_keys: name key: name key_len: 33 ref: const rows: 3 Extra: Using where -
对于左前缀不易区分的列,建立索引的技巧
如url列,
http://www.google.com
http://www.github.com
列的前11个字符都是一样的,不易区分,可以用两个方法解决1.把列内容倒过来存储,并建立索引
moc.elgoog.www//:ptth
moc.buhtig.www//:ptth
这样左前缀区分大2.伪hash索引效果
同时存 url_hash 列mysql> create table t9( -> id int primary key auto_increment, -> url varchar(30) not null default '', -> crcurl int not null default 0 )engine myisam charset utf8; mysql> alter table t9 add index url(url(16)); mysql> alter table t9 add index crcurl(crcurl); mysql> show create table t9 \G; *************************** 1. row *************************** Table: t9 Create Table: CREATE TABLE `t9` ( `id` int(11) NOT NULL AUTO_INCREMENT, `url` varchar(30) NOT NULL DEFAULT '', `crcurl` int(11) NOT NULL DEFAULT '0', PRIMARY KEY (`id`), KEY `url` (`url`(16)), KEY `crcurl` (`crcurl`) ) ENGINE=MyISAM DEFAULT CHARSET=utf8 mysql> insert into t9(url) values('http://www.google.com'),('http://www.github.com'); mysql> update t9 set crcurl=crc32(url); mysql> select * from t9; +----+-----------------------+------------+ | id | url | crcurl | +----+-----------------------+------------+ | 1 | http://www.google.com | 1587574693 | | 2 | http://www.github.com | 1826282744 | +----+-----------------------+------------+ mysql> explain select * from t9 where url='http://www.google.com'; +----+-------------+-------+------+---------------+------+---------+-------+------+-------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+-------+------+---------------+------+---------+-------+------+-------------+ | 1 | SIMPLE | t9 | ref | url | url | 50 | const | 1 | Using where | +----+-------------+-------+------+---------------+------+---------+-------+------+-------------+ mysql> explain select * from t9 where crcurl=(select crc32('http://www.google.com')); +----+-------------+-------+------+---------------+--------+---------+-------+------+-------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+-------+------+---------------+--------+---------+-------+------+-------+ | 1 | SIMPLE | t9 | ref | crcurl | crcurl | 4 | const | 1 | NULL | +----+-------------+-------+------+---------------+--------+---------+-------+------+-------+用crc函数来构造伪哈希列,把字符串的列转成整型,来降低索引长度
九、大数据量分页优化
select field from table limit offset,rows
-
1.从业务上优化
不允许翻过100页
在offset比较大时,limte offset 的效率很低,因为它的要先查询再跳过.
查询1kw为例,要把1kw取出来,再跳过这1kw行mysql> select log_id,create_uid from gold_room_log limit 0,10; +--------+------------+ | log_id | create_uid | +--------+------------+ | 1 | 1542090 | | 2 | 1542090 | | 3 | 1542090 | | 4 | 1542089 | | 5 | 1542089 | | 6 | 1542089 | | 7 | 1542089 | | 8 | 1542089 | | 9 | 1542089 | | 10 | 1542094 | +--------+------------+ 10 rows in set (0.00 sec) mysql> select log_id,create_uid from gold_room_log limit 100000,10; +---------+------------+ | log_id | create_uid | +---------+------------+ | 1000001 | 1555441 | | 1000002 | 1552879 | | 1000003 | 1553922 | | 1000004 | 1556527 | | 1000005 | 1556772 | | 1000006 | 1554096 | | 1000007 | 1553254 | | 1000008 | 1555427 | | 1000009 | 1564131 | | 1000010 | 1547377 | +---------+------------+ 10 rows in set (0.01 sec) mysql> select log_id,create_uid from gold_room_log limit 10000000,10; +----------+------------+ | log_id | create_uid | +----------+------------+ | 10194814 | 1656483 | | 10194815 | 1644228 | | 10194816 | 1681150 | | 10194817 | 1645149 | | 10194818 | 1658664 | | 10194819 | 1658611 | | 10194820 | 1585559 | | 10194821 | 1570038 | | 10194822 | 1654489 | | 10194823 | 1556482 | +----------+------------+ 10 rows in set (1.37 sec) mysql> show profiles; +----------+------------+---------------------------------------------------------------+ | Query_ID | Duration | Query | +----------+------------+---------------------------------------------------------------+ | 1 | 1.36947275 | select log_id,create_uid from gold_room_log limit 10000000,10 | | 2 | 0.01329775 | select log_id,create_uid from gold_room_log limit 100000,10 | | 3 | 0.00016700 | select log_id,create_uid from gold_room_log limit 0,10 | +----------+------------+---------------------------------------------------------------+ 3 rows in set, 1 warning (0.01 sec) mysql> show profile for query 1; +----------------------+----------+ | Status | Duration | +----------------------+----------+ | starting | 0.000039 | | checking permissions | 0.000004 | | Opening tables | 0.000014 | | init | 0.000010 | | System lock | 0.000005 | | optimizing | 0.000004 | | statistics | 0.000009 | | preparing | 0.000007 | | executing | 0.000002 | | Sending data | 1.369337 | | end | 0.000012 | | query end | 0.000005 | | closing tables | 0.000008 | | freeing items | 0.000012 | | cleaning up | 0.000007 | +----------------------+----------+ 15 rows in set, 1 warning (0.00 sec)查询时间1.37s 都花在 Sending data
-
2.把offset换成主键索引条件查询,减少查询时间
这种方式要求:
数据没有被删除过,否者查询的数据不准确
或者不物理删除,只逻辑删除(is_del=1),在页面显示数据时做处理mysql> select log_id,create_uid from gold_room_log where log_id>10000000 limit 10; +----------+------------+ | log_id | create_uid | +----------+------------+ | 10000001 | 1653829 | | 10000002 | 1680856 | | 10000003 | 1671385 | | 10000004 | 1543762 | | 10000005 | 1649077 | | 10000006 | 1658246 | | 10000007 | 1630592 | | 10000008 | 1665355 | | 10000009 | 1637759 | | 10000010 | 1587961 | +----------+------------+ 10 rows in set (0.02 sec) -
3.非要物理删除,还用offset精确查找,还不限制用户
优化思路:不查,少查,查索引,少取.
如果必须要查,则只查索引不查数据,得到id.
再用id去查具体条目,这种技巧就是延迟索引mysql> select a.log_id,create_uid from gold_room_log as a inner join(select log_id from gold_room_log limit 10000000,10) as b on b.log_id=a.log_id; +----------+------------+ | log_id | create_uid | +----------+------------+ | 10194814 | 1656483 | | 10194815 | 1644228 | | 10194816 | 1681150 | | 10194817 | 1645149 | | 10194818 | 1658664 | | 10194819 | 1658611 | | 10194820 | 1585559 | | 10194821 | 1570038 | | 10194822 | 1654489 | | 10194823 | 1556482 | +----------+------------+ 10 rows in set (1.08 sec)其原理就是按索引id查找1kw中的10条数据,再用id查找其它字段
避免了没有索引的字段,回行取数据的时间
十、索引与排序
-
索引与排序
排序可能发生2种情况
1.对于覆盖索引,直接在索引上查询时就是有序的,using index
2.先取出数据,形成临时表filesort(文件排序,但文件可能在磁盘上,也可能在内存中)我们争取的目标–取出的数据本身就是有序的,利用索引来排序
比如:gold_log表,(uid,num)组成联合索引
mysql> show create table gold_log \G; *************************** 1. row *************************** Table: gold_log Create Table: CREATE TABLE `gold_log` ( `id` int(10) NOT NULL AUTO_INCREMENT, `uid` int(10) DEFAULT '0' COMMENT '用户id', `change_type` tinyint(4) DEFAULT '0' COMMENT '来源类型', `num` int(10) DEFAULT '0' COMMENT '数量', `left_num` int(10) DEFAULT '0' COMMENT '剩余数量', `type` int(10) DEFAULT '0' COMMENT '行为类型', `create_time` int(10) DEFAULT '0' COMMENT '创建时间', `game_type` int(10) DEFAULT '0' COMMENT '游戏分类', `sub_type` int(10) DEFAULT '0' COMMENT '游戏id', `order_id` varchar(32) DEFAULT '0' COMMENT '订单id', `lvl` int(11) NOT NULL DEFAULT '0', `relief_status` tinyint(1) NOT NULL DEFAULT '0' COMMENT '需要救济状态', PRIMARY KEY (`id`) USING BTREE, KEY `ctime_type_left_num` (`create_time`,`type`,`left_num`) USING BTREE, KEY `uid_num` (`uid`,`num`) ) ENGINE=InnoDB AUTO_INCREMENT=205329440 DEFAULT CHARSET=utf8 COMMENT='金币日志表'using where,按照 uid_num 索引取出的结果,本身就是有序的
mysql> explain select id,uid,num,create_time from gold_log where uid =1520002 order by num; +----+-------------+----------+------+------------------------+---------+---------+-------+------+-------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+----------+------+------------------------+---------+---------+-------+------+-------------+ | 1 | SIMPLE | gold_log | ref | uid_ctime_type,uid_num | uid_num | 5 | const | 24 | Using where | +----+-------------+----------+------+------------------------+---------+---------+-------+------+-------------+using filesort,使用文件排序,即取出的结果再次排序
mysql> explain select id,uid,num,create_time from gold_log where uid =1520002 order by create_time; +----+-------------+----------+------+---------------+---------+---------+-------+------+-----------------------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+----------+------+---------------+---------+---------+-------+------+-----------------------------+ | 1 | SIMPLE | gold_log | ref | uid_num | uid_num | 5 | const | 24 | Using where; Using filesort | +----+-------------+----------+------+---------------+---------+---------+-------+------+-----------------------------+去掉联合索引时,查询使用 using filesort 文件排序
mysql> alter table gold_log drop index uid_num; mysql> explain select id,uid,num,create_time from gold_log where uid =1520002 order by num; +----+-------------+----------+------+---------------+------+---------+------+-------+-----------------------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+----------+------+---------------+------+---------+------+-------+-----------------------------+ | 1 | SIMPLE | gold_log | ALL | NULL | NULL | NULL | NULL | 63118 | Using where; Using filesort | +----+-------------+----------+------+---------------+------+---------+------+-------+-----------------------------+ -
重复索引与冗余索引
重复索引是指,在同一个列(如a),或者顺序相同的几个列(a,b),建立了多个索引,称为重复索引.
重复索引没有任何帮助,只会增大索引文件,拖慢更新速度,去掉mysql> alter table gold_log add index num(num); mysql> alter table gold_log add index num2(num); mysql> show create table gold_log \G; *************************** 1. row *************************** Table: gold_log Create Table: CREATE TABLE `gold_log` ( `id` int(10) NOT NULL AUTO_INCREMENT, `uid` int(10) DEFAULT '0' COMMENT '用户id', `change_type` tinyint(4) DEFAULT '0' COMMENT '来源类型', `num` int(10) DEFAULT '0' COMMENT '数量', `left_num` int(10) DEFAULT '0' COMMENT '剩余数量', `type` int(10) DEFAULT '0' COMMENT '行为类型', `create_time` int(10) DEFAULT '0' COMMENT '创建时间', `game_type` int(10) DEFAULT '0' COMMENT '游戏分类', `sub_type` int(10) DEFAULT '0' COMMENT '游戏id', `order_id` varchar(32) DEFAULT '0' COMMENT '订单id', `lvl` int(11) NOT NULL DEFAULT '0', `relief_status` tinyint(1) NOT NULL DEFAULT '0' COMMENT '需要救济状态', PRIMARY KEY (`id`) USING BTREE, KEY `ctime_type_left_num` (`create_time`,`type`,`left_num`) USING BTREE, KEY `uid_num` (`uid`,`num`), KEY `num` (`num`), KEY `num2` (`num`) ) ENGINE=InnoDB AUTO_INCREMENT=205329440 DEFAULT CHARSET=utf8 COMMENT='金币日志表'冗余索引指,2个索引所覆盖的列有重叠,称为冗余索引
比如,x,y列加索引 inde x(x),index xy(x,y),
或者顺序不一样,index xy(x,y),index yx(y,x) -
索引碎片修复
在长期的数据修改过程中,索引文件和数据文件吗,都将产生空洞,形成碎片.
我们可以通过一个nop操作(不产生对数据实质影响的操作),来修改表.
比如:表的引擎为innodb,可以alter table table_name engine innodb.
optimize table table_name,也可以修复注意:修复表的数据和索引文件,就会把所有的数据文件重新整理一遍,使之对齐.
这个过程,如果表的行数比较大,也是非常耗费资源的操作,所以不能频繁修复.如果表的update操作很频繁,可以按 周/月 来修复.
如果不频繁,可以更长的周期来修复.一键优化脚本:
#!/bin/sh echo -n "username: " ; read username echo -n "password: " ; stty -echo ; read password ; stty echo ; echo mysql -u $username -p"$password" -NBe "SHOW DATABASES;" | grep -v 'lost+found' | while read database ; do mysql -u $username -p"$password" -NBe "SHOW TABLE STATUS;" $database | while read name engine version rowformat rows avgrowlength datalength maxdatalength indexlength datafree autoincrement createtime updatetime checktime collation checksum createoptions comment ; do if [ "$datafree" -gt 0 ] ; then fragmentation=$(($datafree * 100 / $datalength)) echo "$database.$name is $fragmentation% fragmented." mysql -u "$username" -p"$password" -NBe "OPTIMIZE TABLE $name;" "$database" fi done
十一、explain分析sql效果
-
id列
select的编号从1开始
子查询则编号增加 -
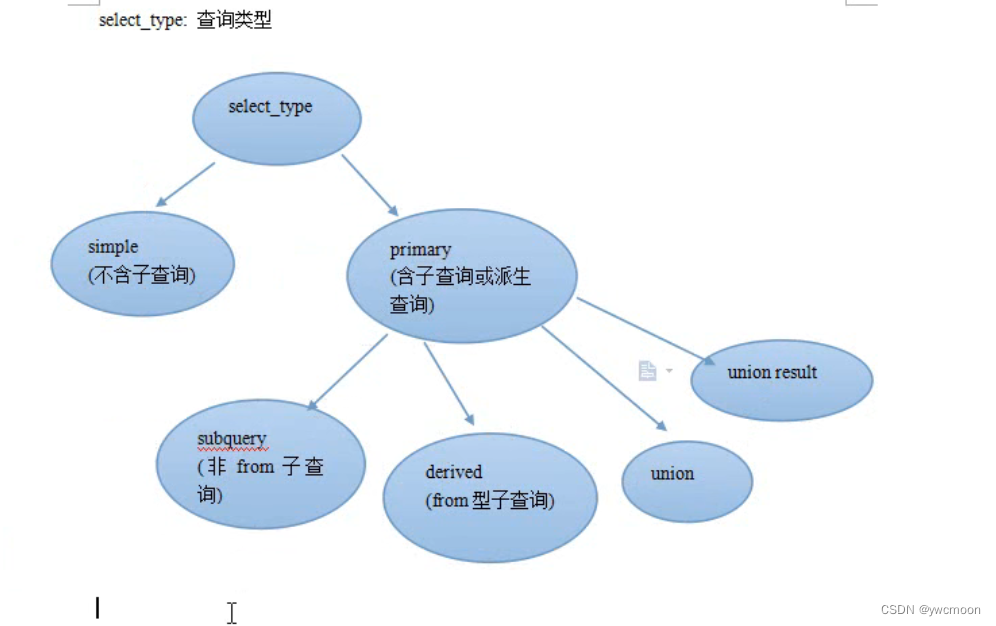
select_type列
simple/primary
subquerymysql> explain select (select * from t2) from t1; +----+-------------+-------+-------+---------------+------+---------+------+------+-------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+-------+-------+---------------+------+---------+------+------+-------------+ | 1 | PRIMARY | t1 | index | NULL | name | 3 | NULL | 2 | Using index | | 2 | SUBQUERY | t2 | index | NULL | name | 4 | NULL | 2 | Using index | +----+-------------+-------+-------+---------------+------+---------+------+------+-------------+derived
mysql> explain select 1 from (select 1)as a; +----+-------------+------------+--------+---------------+------+---------+------+------+----------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+------------+--------+---------------+------+---------+------+------+----------------+ | 1 | PRIMARY | <derived2> | system | NULL | NULL | NULL | NULL | 1 | NULL | | 2 | DERIVED | NULL | NULL | NULL | NULL | NULL | NULL | NULL | No tables used | +----+-------------+------------+--------+---------------+------+---------+------+------+----------------+union
union result
-
table列
实际的表名
表的别名
派生表名,如derived,from型子查询
null,直接计算的结果不用走表mysql> explain select 1; +----+-------------+-------+------+---------------+------+---------+------+------+----------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+-------+------+---------------+------+---------+------+------+----------------+ | 1 | SIMPLE | NULL | NULL | NULL | NULL | NULL | NULL | NULL | No tables used | +----+-------------+-------+------+---------------+------+---------+------+------+----------------+ -
type列
指查询方式,是分析“查询数据过程”的重要依据
执行效率 system > const > eq_ref > ref > range > index > ALL名称 含义 system 系统表,少量数据,往往不需要进行磁盘IO const 常量连接 eq_ref 主键索引(primary key)或者非空唯一索引(unique not null)等值扫描 ref 非主键非唯一索引等值扫描 range 范围扫描 index 索引树扫描 ALL 全表扫描(full table scan) All
全表数据扫描
意味着从表的第一行,往后逐行做全表扫描.可能扫描到最后一行mysql> explain select * from gold_log \G; *************************** 1. row *************************** id: 1 select_type: SIMPLE table: gold_log type: ALL possible_keys: NULL key: NULL key_len: NULL ref: NULL rows: 63118 Extra: NULLindex
全索引扫描
通俗来说,all扫描所有数据行data_all,而index扫描所有索引节点,相当于index_allmysql> explain select id from gold_log order by id \G; *************************** 1. row *************************** id: 1 select_type: SIMPLE table: gold_log type: index possible_keys: NULL key: PRIMARY key_len: 4 ref: NULL rows: 63118 Extra: Using indexrange
索引范围扫描mysql> explain select * from gold_log where id>5 \G; *************************** 1. row *************************** id: 1 select_type: SIMPLE table: gold_log type: range possible_keys: PRIMARY key: PRIMARY key_len: 4 ref: NULL rows: 31559 Extra: Using whereref
通过索引列,直接引用到某些数据行mysql> explain select * from gold_log where num=5 \G; *************************** 1. row *************************** id: 1 select_type: SIMPLE table: gold_log type: ref possible_keys: num,num2 key: num key_len: 5 ref: const rows: 1 Extra: NULLeq_ref
通过索引列,直接引用某一行数据mysql> explain select a.id,b.room_id from gold_log a inner join gold_room_log b on a.id=b.log_id where a.id >0 \G; *************************** 1. row *************************** id: 1 select_type: SIMPLE table: a type: range possible_keys: PRIMARY key: PRIMARY key_len: 4 ref: NULL rows: 31559 Extra: Using where; Using index *************************** 2. row *************************** id: 1 select_type: SIMPLE table: b type: eq_ref possible_keys: PRIMARY key: PRIMARY key_len: 4 ref: test.a.id rows: 1 Extra: NULLconst,system,null
这三个分别值,查询优化到了常量级别,甚至不需要查询时间
一般按照主键查询时,易出现const,system
或者直接查找某个表达式不经过表时,出现nullmysql> explain select * from t1 where id =1; +----+-------------+-------+-------+---------------+---------+---------+-------+------+-------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+-------+-------+---------------+---------+---------+-------+------+-------+ | 1 | SIMPLE | t1 | const | PRIMARY | PRIMARY | 4 | const | 1 | NULL | +----+-------------+-------+-------+---------------+---------+---------+-------+------+-------+mysql> explain select * from (select * from t1 where id=1) a; +----+-------------+------------+--------+---------------+---------+---------+-------+------+-------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+------------+--------+---------------+---------+---------+-------+------+-------+ | 1 | PRIMARY | <derived2> | system | NULL | NULL | NULL | NULL | 1 | NULL | | 2 | DERIVED | t1 | const | PRIMARY | PRIMARY | 4 | const | 1 | NULL | +----+-------------+------------+--------+---------------+---------+---------+-------+------+-------+mysql> explain select * from t1 where id =3; +----+-------------+-------+------+---------------+------+---------+------+------+-----------------------------------------------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+-------+------+---------------+------+---------+------+------+-----------------------------------------------------+ | 1 | SIMPLE | NULL | NULL | NULL | NULL | NULL | NULL | NULL | Impossible WHERE noticed after reading const tables | +----+-------------+-------+------+---------------+------+---------+------+------+-----------------------------------------------------+ -
possible_keys列
可能用到的索引
系统估计可能用的几个索引,最终只用一个 -
keys列
实际用到的索引 -
key_len列
使用的索引最大长度 -
ref列
连接查询时,前表与后表的引用关系 -
rows列
估计扫描多少行 -
extra列
using index
using where
using temporary,使用临时表
using filesort,使用文件排序
range checked for each record
十二、mysql函数查询优化
-
in型子查询陷井
mysql的查询优化器,针对in型做优化,被改成了exists的执行效果.
表数据越大,查询速度越慢
改进:用连接查询来代替子查询mysql> select log_id,str from gold_room_log where log_id in (select id from t1);mysql> explain select a.log_id,a.str from gold_room_log as a inner join (select id from t1) as tmp on a.log_id=tmp.id; +----+-------------+------------+--------+---------------+---------+---------+--------+------+-------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+------------+--------+---------------+---------+---------+--------+------+-------------+ | 1 | PRIMARY | <derived2> | ALL | NULL | NULL | NULL | NULL | 5 | NULL | | 1 | PRIMARY | a | eq_ref | PRIMARY | PRIMARY | 4 | tmp.id | 1 | Using where | | 2 | DERIVED | t1 | index | NULL | name | 3 | NULL | 5 | Using index | +----+-------------+------------+--------+---------------+---------+---------+--------+------+-------------+ -
exists一定比子查询慢吗
连接查询用exists代替select a.uid,a.id from gold_log as a inner join user as b on a.uid=b.uid group by b.uid group by uidselect a.uid,a.id from gold_log as a where exists(select uid from user as b where b.uid=a.uid) -
max min非常规优化技巧
有一个地区表,pid无索引
现要查询pid为98的最小id
改为强制使用id的索引,可提升查询速度
因为id是有顺序的(默认索引升序排列),因此沿着id的索引方向走,第一个pid=98的索引节点的id就是最小的
该方法语义不清晰,仅实验目的mysql> show create table region \G; *************************** 1. row *************************** Table: region Create Table: CREATE TABLE `region` ( `id` smallint(5) unsigned NOT NULL AUTO_INCREMENT, `pid` smallint(5) unsigned NOT NULL DEFAULT '0' COMMENT '父级id', `name` varchar(120) NOT NULL DEFAULT '' COMMENT '地域名', `type` tinyint(1) NOT NULL DEFAULT '2' COMMENT '地域级别:1省,2市,3区', PRIMARY KEY (`id`) USING BTREE ) ENGINE=MyISAM AUTO_INCREMENT=3409 DEFAULT CHARSET=utf8 COMMENT='全国地区表'mysql> explain select min(id) from region where pid = 98; +----+-------------+--------+------+---------------+------+---------+------+------+-------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+--------+------+---------------+------+---------+------+------+-------------+ | 1 | SIMPLE | region | ALL | NULL | NULL | NULL | NULL | 3408 | Using where | +----+-------------+--------+------+---------------+------+---------+------+------+-------------+mysql> explain select id from region use index(primary) where pid = 98 limit 1; +----+-------------+--------+------+---------------+------+---------+------+------+-------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+--------+------+---------------+------+---------+------+------+-------------+ | 1 | SIMPLE | region | ALL | NULL | NULL | NULL | NULL | 3408 | Using where | +----+-------------+--------+------+---------------+------+---------+------+------+-------------+mysql> show profiles; +----------+------------+----------------------------------------------------------------------------------+ | Query_ID | Duration | Query | +----------+------------+----------------------------------------------------------------------------------+ | 1 | 0.00044125 | select min(id) from region where pid = 98 | 2 | 0.00022225 | select id from region use index(primary) where pid = 98 limit 1 | +----------+------------+----------------------------------------------------------------------------------+ -
count优化小技巧
利用减法提升count的查询速度mysql> select count(*) from gold_room_log where log_id > 100; +----------+ | count(*) | +----------+ | 29081923 | +----------+ 1 row in set (4.95 sec)mysql> select (select count(*) from gold_room_log) - (select count(*) from gold_room_log where log_id <= 100) as cnt; +----------+ | cnt | +----------+ | 29081923 | +----------+ 1 row in set (3.08 sec) -
group by
1.分组用于统计,而不用于筛选数据
比如:适合统计平均分,最高分,不合适筛选重复数据2.以A,B表连接为例,主要查询A表的列
那么group by,order by 的列尽量相同,而且列应该显示声明为A的列 -
union
union all不过滤,效率提高,如非必要用union all
union去重代价很高,在程序里去重 -
用变量计算真正影响的行数
当插入多条,主键重复则自动更新,可以用
insert ... on duplicate for updatemysql> select * from t10 order by score desc; +-------+-------+ | name | score | +-------+-------+ | zhang | 100 | | qian | 100 | | li | 95 | | wang | 95 | | zhao | 90 | +-------+-------+ mysql> set @pres:=0,@currs:=0,@rank:=0; mysql> select name,(@currs:=score) as score,@rank:=if(@currs<>@pres,@rank:=@rank+1,@rank) as rank,@pres:=score as pre from t10 order by score desc; +-------+-------+------+-----+ | name | score | rank | pre | +-------+-------+------+-----+ | zhang | 100 | 1 | 100 | | qian | 100 | 1 | 100 | | li | 95 | 2 | 95 | | wang | 95 | 2 | 95 | | zhao | 90 | 3 | 90 | +-------+-------+------+-----+ mysql> insert into t10(name,score) values('li',80) on duplicate key update score=score+1; mysql> select * from t10; +-------+-------+ | name | score | +-------+-------+ | zhang | 100 | | li | 96 | | wang | 95 | | zhao | 90 | | qian | 100 | +-------+-------+要统计真正“新增”的条目,新增行数 = 总影响行数 - 2*变量(实际的update数)
mysql> set @x:=0; mysql> insert into t10(name,score) values('zhen',79),('li',80) on duplicate key update score=score+1+0*(@x:=@x+1); Query OK, 3 rows affected (0.00 sec) Records: 2 Duplicates: 1 Warnings: 0 mysql> select @x; +------+ | @x | +------+ | 1 | +------+ mysql> set @x:=0; mysql> insert into t10(name,score) values('zhen',79),('li',80) on duplicate key update score=score+1+0*(@x:=@x+1); Query OK, 4 rows affected (0.00 sec) Records: 2 Duplicates: 2 Warnings: 0 mysql> select @x; +------+ | @x | +------+ | 2 | +------+ -
简化union
使用union时,两个查询都要执行
如果想要,当其中一个查询有结果时,另一个不执行,则可减少查询时间mysql> select * from new1; +------+-------+ | id | title | +------+-------+ | 1 | hello | +------+-------+ mysql> select * from new2; +------+-------+ | id | title | +------+-------+ | 2 | world | +------+-------+ mysql> set @find:=0; mysql> select id,title,@find:=1 from news1 where id=1 -> union -> select id,title,1 from new2 where id=1 and @find<>1 -> union -> select 1,1,@find:=0 from new2 where 0; mysql> select id,title,@find:=1 from new1 where id=1 union select id,title,1 from new2 where id=1 and @find<>1 union select 1,1,@find:=0 from new2 where 0; +------+-------+----------+ | id | title | @find:=1 | +------+-------+----------+ | 1 | hello | 1 | +------+-------+----------+
十三、主从集群配置
-
原理:
主服务器建立二进制日志,每产生语句或磁盘变化,写进日志.
从服务器建立中继日志relaylog,复制主服务器日志.
从读取日志需要授权,主建立授权复制账号,从利用授权账号监听主服务器日志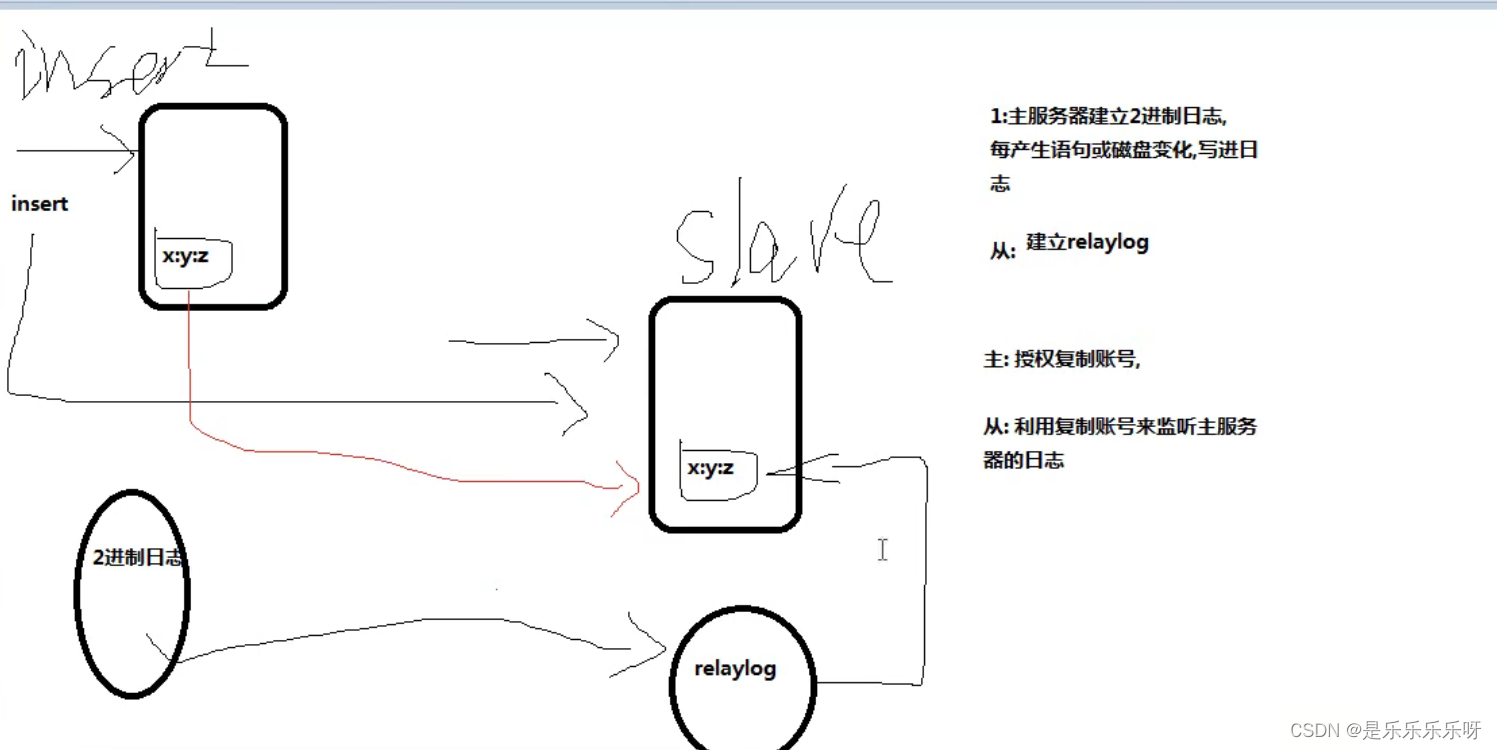
-
注意点:
主服务器
创建复制账号mysql> grant replication client,replication slave on *.* to repl@'192.168.6.%' identified by '123456'; mysql> flush privileges;从服务器
指定要复制的主服务器mysql> change master to master_host='192.168.6.3',master_user='repl',master_password='123456',master_log_file='mysql-bin.000027',master_log_pos=427;主服务器的日志格式:
statement 适合多行变化
row 适合少行变化
mixed 混合 -
一些报错:
1.Last_IO_Error: Fatal error: The slave I/O thread stops because master and slave have equal MySQL server UUIDs; these UUIDs must be different for replication to work.mysql> show slave status \G; *************************** 1. row *************************** Slave_IO_State: Master_Host: 192.168.6.3 Master_User: repl Master_Port: 3306 Connect_Retry: 60 Master_Log_File: mysql-bin.000027 Read_Master_Log_Pos: 427 Relay_Log_File: mysql-relay.000001 Relay_Log_Pos: 4 Relay_Master_Log_File: mysql-bin.000027 Slave_IO_Running: No Slave_SQL_Running: Yes Replicate_Do_DB: Replicate_Ignore_DB: Replicate_Do_Table: Replicate_Ignore_Table: Replicate_Wild_Do_Table: Replicate_Wild_Ignore_Table: Last_Errno: 0 Last_Error: Skip_Counter: 0 Exec_Master_Log_Pos: 427 Relay_Log_Space: 120 Until_Condition: None Until_Log_File: Until_Log_Pos: 0 Master_SSL_Allowed: No Master_SSL_CA_File: Master_SSL_CA_Path: Master_SSL_Cert: Master_SSL_Cipher: Master_SSL_Key: Seconds_Behind_Master: NULL Master_SSL_Verify_Server_Cert: No Last_IO_Errno: 1593 Last_IO_Error: Fatal error: The slave I/O thread stops because master and slave have equal MySQL server UUIDs; these UUIDs must be different for replication to work. Last_SQL_Errno: 0 Last_SQL_Error: Replicate_Ignore_Server_Ids: Master_Server_Id: 1 Master_UUID: Master_Info_File: /www/server/data/master.info SQL_Delay: 0 SQL_Remaining_Delay: NULL Slave_SQL_Running_State: Slave has read all relay log; waiting for the slave I/O thread to update it Master_Retry_Count: 86400 Master_Bind: Last_IO_Error_Timestamp: 220607 14:50:16 Last_SQL_Error_Timestamp: Master_SSL_Crl: Master_SSL_Crlpath: Retrieved_Gtid_Set: Executed_Gtid_Set: Auto_Position: 0主从服务器的 UUID 不一致
查看uuid,复制到auto.cnf,重启mysqlmysql> select uuid(); +--------------------------------------+ | uuid() | +--------------------------------------+ | 895c249c-e62e-11ec-af6c-000c29e89922 | +--------------------------------------+ [root@localhost data]# find / -name 'auto.cnf' /www/server/data/auto.cnf [root@localhost data]# cat /www/server/data/auto.cnf [auto] server-uuid=2a153634-e62e-11ec-b434-000c29e89922 [root@localhost data]# service mysqld restart2.
Last_Error: Slave failed to initialize relay log info structure from the repositorymysql> show slave status \G; *************************** 1. row *************************** Slave_IO_State: Master_Host: 192.168.6.3 Master_User: repl Master_Port: 3306 Connect_Retry: 60 Master_Log_File: mysql-bin.000027 Read_Master_Log_Pos: 427 Relay_Log_File: slave-relay-bin.000001 Relay_Log_Pos: 4 Relay_Master_Log_File: mysql-bin.000027 Slave_IO_Running: No Slave_SQL_Running: No Replicate_Do_DB: Replicate_Ignore_DB: Replicate_Do_Table: Replicate_Ignore_Table: Replicate_Wild_Do_Table: Replicate_Wild_Ignore_Table: Last_Errno: 1872 Last_Error: Slave failed to initialize relay log info structure from the repository Skip_Counter: 0 Exec_Master_Log_Pos: 427 Relay_Log_Space: 0 Until_Condition: None Until_Log_File: Until_Log_Pos: 0 Master_SSL_Allowed: No Master_SSL_CA_File: Master_SSL_CA_Path: Master_SSL_Cert: Master_SSL_Cipher: Master_SSL_Key: Seconds_Behind_Master: NULL Master_SSL_Verify_Server_Cert: No Last_IO_Errno: 0 Last_IO_Error: Last_SQL_Errno: 1872 Last_SQL_Error: Slave failed to initialize relay log info structure from the repository Replicate_Ignore_Server_Ids: Master_Server_Id: 0 Master_UUID: Master_Info_File: /www/server/data/master.info SQL_Delay: 0 SQL_Remaining_Delay: NULL Slave_SQL_Running_State: Master_Retry_Count: 86400 Master_Bind: Last_IO_Error_Timestamp: Last_SQL_Error_Timestamp: 220607 14:42:23 Master_SSL_Crl: Master_SSL_Crlpath: Retrieved_Gtid_Set: Executed_Gtid_Set: Auto_Position: 0保存的relay_log信息错误
删除,重新指定主服务器信息mysql> reset salve; mysql> change master to master_host='192.168.6.3',master_user='repl',master_password='123456',master_log_file='mysql-bin.000027',master_log_pos=427; mysql> start slave;3.
error connecting to master 'repl@192.168.6.4:3306' - retry-time: 60 retries: 128mysql> show slave status \G; *************************** 1. row *************************** Slave_IO_State: Connecting to master Master_Host: 192.168.6.4 Master_User: repl Master_Port: 3306 Connect_Retry: 60 Master_Log_File: mysql-bin.000026 Read_Master_Log_Pos: 120 Relay_Log_File: mysql-relay.000001 Relay_Log_Pos: 4 Relay_Master_Log_File: mysql-bin.000026 Slave_IO_Running: Connecting Slave_SQL_Running: Yes Replicate_Do_DB: Replicate_Ignore_DB: Replicate_Do_Table: Replicate_Ignore_Table: Replicate_Wild_Do_Table: Replicate_Wild_Ignore_Table: Last_Errno: 0 Last_Error: Skip_Counter: 0 Exec_Master_Log_Pos: 120 Relay_Log_Space: 120 Until_Condition: None Until_Log_File: Until_Log_Pos: 0 Master_SSL_Allowed: No Master_SSL_CA_File: Master_SSL_CA_Path: Master_SSL_Cert: Master_SSL_Cipher: Master_SSL_Key: Seconds_Behind_Master: NULL Master_SSL_Verify_Server_Cert: No Last_IO_Errno: 2003 Last_IO_Error: error connecting to master 'repl@192.168.6.4:3306' - retry-time: 60 retries: 128 Last_SQL_Errno: 0 Last_SQL_Error: Replicate_Ignore_Server_Ids: Master_Server_Id: 0 Master_UUID: Master_Info_File: /www/server/data/master.info SQL_Delay: 0 SQL_Remaining_Delay: NULL Slave_SQL_Running_State: Slave has read all relay log; waiting for the slave I/O thread to update it Master_Retry_Count: 86400 Master_Bind: Last_IO_Error_Timestamp: 220614 13:59:43 Last_SQL_Error_Timestamp: Master_SSL_Crl: Master_SSL_Crlpath: Retrieved_Gtid_Set: Executed_Gtid_Set: Auto_Position: 0连接主服务器地址错误
关闭防火墙[root@localhost ~]# systemctl status firewalld ● firewalld.service - firewalld - dynamic firewall daemon Loaded: loaded (/usr/lib/systemd/system/firewalld.service; enabled; vendor preset: enabled) Active: active (running) since 四 2022-06-09 09:27:03 CST; 5 days ago Docs: man:firewalld(1) Main PID: 815 (firewalld) CGroup: /system.slice/firewalld.service └─815 /usr/bin/python2 -Es /usr/sbin/firewalld --nofork --nopid 6月 09 09:27:02 localhost.localdomain systemd[1]: Starting firewalld - dynamic firewall daemon... 6月 09 09:27:03 localhost.localdomain systemd[1]: Started firewalld - dynamic firewall daemon. 6月 09 09:27:03 localhost.localdomain firewalld[815]: WARNING: AllowZoneDrifting is enabled. This is considered an insecure configuration option. It will be removed in a future release. Please consider disabling it now. [root@localhost ~]# systemctl stop firewalld -
ERROR 1045 (28000): Access denied for user 'root'@'192.168.6.5' (using password: YES)
拒绝用户( ‘root’@‘192.168.6.5’ )访问D:\wnmp\Extensions\MySQL5.7.26\bin>mysql -h 192.168.6.5 -uroot -p123456 -P 4040 ERROR 1045 (28000): Access denied for user 'root'@'192.168.6.5' (using password: YES)指定ip授权
mysql> grant all on *.* to root@'192.168.6.5' identified by '123456'; mysql> flush privileges;
十四、主主复制和mysql proxy的使用
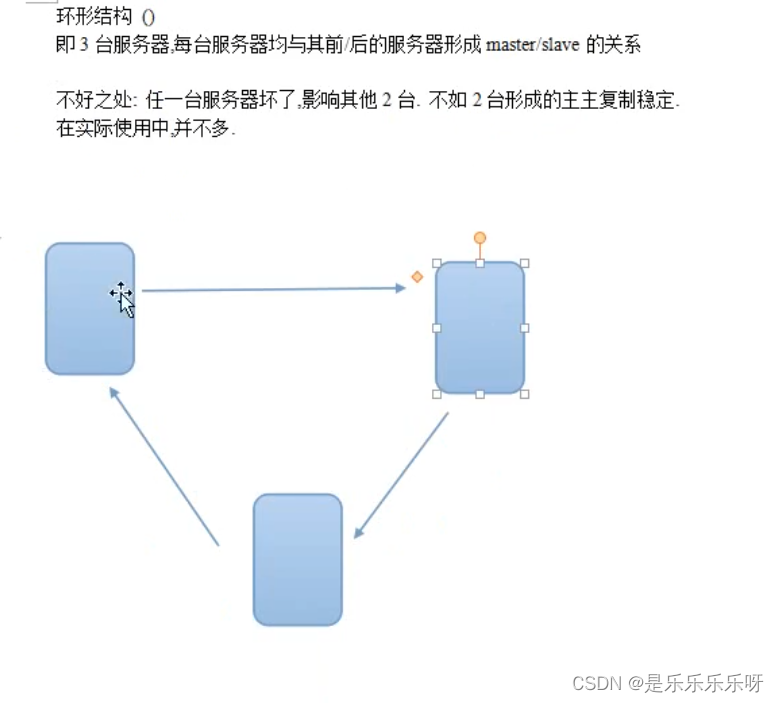
-
主主复制
即两台服务器互相复制
大致思路:
1.两台服务器都设置上2进制日志和relay日志
[root@localhost ~]# vi /etc/my.cnf [mysqld] #binary log server-id=1 #server-id=2 log-bin=mysql-bin binlog_format=mixed relay-log=mysql-relay2.都设置replication账号
mysql> grant replication client,replication slave on *.* to 'repl'@'192.168.6.%' identified by '123456';3.都设置对方为自己的master
change master to master_host='192.168.6.4',master_user='repl',master_password='123456',master_log_file='mysql-bin.000026',master_log_pos=120; -
主主复制时主键冲突问题
主主复制时,两台服务器同步的主键有重复
解决办法:
A服务器(192.168.6.3),主键按1,3,5奇数增长
mysql> set global auto_increment_increment=2; mysql> set global auto_increment_offset=1; mysql> set session auto_increment_increment=2; mysql> set session auto_increment_offset=1;B服务器(192.168.6.4),主键按2,4,6偶数增长
mysql> set global auto_increment_increment=2; mysql> set global auto_increment_offset=2; mysql> set session auto_increment_increment=2; mysql> set session auto_increment_offset=2;后期加业务此方法有限制,可在业务逻辑上解决.
比如orcle,有sequnce序列
序列每次访问生成递增/递减的数据以redis为例,可专门构建global:userid
每次php插入mysql前,先incre->global:userid,得到一个不重复的userid -
被动主主复制
两台服务器地位一样,其中一台为只读,另一台为只写
优势为,写服务器出现问题,能迅速切换到从服务器,或者出于检修等目的,把写入功能切换到另一台服务器也比较方便.
设置为只读服务器
[root@localhost ~]# vi /etc/my.cnf [mysqld] read-only=1mysql> show variables like '%read_only%' +-----------------------------------------+---------------------------+ | Variable_name | Value | +-----------------------------------------+---------------------------+ | read_only | ON | +-----------------------------------------+---------------------------+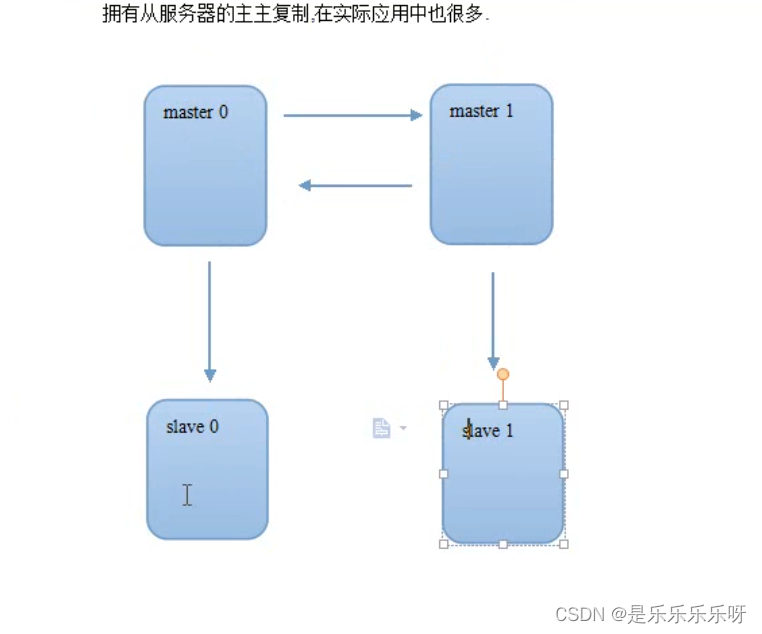


-
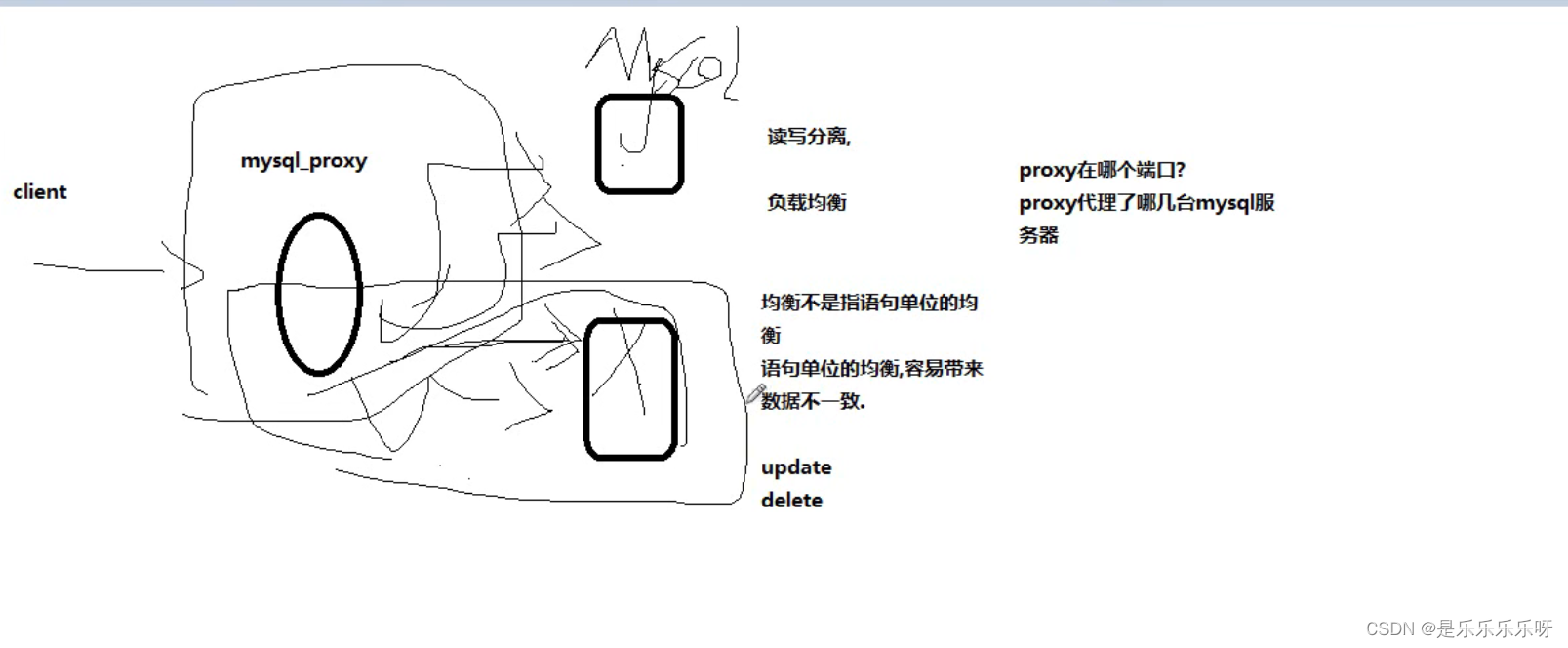
mysql proxy完成负载均衡和读写分离
简介
MySQL Proxy是一个处于你的client端和MySQL server端之间的简单程序,它可以监测、分析或改变它们的通信。它使用灵活,没有限制,常见的用途包括:负载平衡,故障、查询分析,查询过滤和修改等等。
MySQL Proxy就是这么一个中间层代理,简单的说,MySQL Proxy就是一个连接池,负责将前台应用的连接请求转发给后台的数据库,并且通过使用lua脚本,可以实现复杂的连接控制和过滤,从而实现读写分离和负载平衡。对于应用来说,MySQL Proxy是完全透明的,应用则只需要连接到MySQL Proxy的监听端口即可。当然,这样proxy机器可能成为单点失效,但完全可以使用多个proxy机器做为冗余,在应用服务器的连接池配置中配置到多个proxy的连接参数即可。
MySQL Proxy更强大的一项功能是实现“读写分离”,基本原理是让主数据库处理事务性查询,让从库处理SELECT查询。数据库复制被用来把事务性查询导致的变更同步到集群中的从库。下载安装
[root@localhost src]# wget https://downloads.mysql.com/archives/get/p/21/file/mysql-proxy-0.8.5-linux-debian6.0-x86-64bit.tar.gz [root@localhost src]# tar axvf mysql-proxy-0.8.5-linux-debian6.0-x86-64bit.tar.gz [root@localhost src]# cd mysql-proxy-0.8.5-linux-debian6.0-x86-64bit [root@localhost src]# mv mysql-proxy-0.8.5-linux-debian6.0-x86-64bit /usr/local/mysql-proxy [root@localhost src]#cd /usr/local/mysql-proxy [root@localhost mysql-proxy]# ls bin include lib libexec licenses share [root@localhost mysql-proxy]# ls bin/ mysql-binlog-dump mysql-myisam-dump mysql-proxy参数选项
[root@localhost mysql-proxy]# ./bin/mysql-proxy --help-all Usage: mysql-proxy [OPTION...] - MySQL Proxy Help Options: -?, --help Show help options --help-all Show all help options --help-proxy Show options for the proxy-module proxy-module -P, --proxy-address=<host:port> listening address:port of the proxy-server (default: :4040) -r, --proxy-read-only-backend-addresses=<host:port> address:port of the remote slave-server (default: not set) -b, --proxy-backend-addresses=<host:port> address:port of the remote backend-servers (default: 127.0.0.1:3306) --proxy-skip-profiling disables profiling of queries (default: enabled) --proxy-fix-bug-25371 fix bug #25371 (mysqld > 5.1.12) for older libmysql versions -s, --proxy-lua-script=<file> filename of the lua script (default: not set) --no-proxy don't start the proxy-module (default: enabled) --proxy-pool-no-change-user don't use CHANGE_USER to reset the connection coming from the pool (default: enabled) --proxy-connect-timeout connect timeout in seconds (default: 2.0 seconds) --proxy-read-timeout read timeout in seconds (default: 8 hours) --proxy-write-timeout write timeout in seconds (default: 8 hours) Application Options: -V, --version Show version --defaults-file=<file> configuration file --verbose-shutdown Always log the exit code when shutting down --daemon Start in daemon-mode --user=<user> Run mysql-proxy as user --basedir=<absolute path> Base directory to prepend to relative paths in the config --pid-file=<file> PID file in case we are started as daemon --plugin-dir=<path> path to the plugins --plugins=<name> plugins to load --log-level=(error|warning|info|message|debug) log all messages of level ... or higher --log-file=<file> log all messages in a file --log-use-syslog log all messages to syslog --log-backtrace-on-crash try to invoke debugger on crash --keepalive try to restart the proxy if it crashed --max-open-files maximum number of open files (ulimit -n) --event-threads number of event-handling threads (default: 1) --lua-path=<...> set the LUA_PATH --lua-cpath=<...> set the LUA_CPATH启动 mysql-proxy
[root@localhost mysql-proxy]# ./bin/mysql-proxy -P 192.168.6.5:4040 --proxy-backend-addresses=192.168.6.3:3306 --proxy-backend-addresses=192.168.6.4:3306 2022-06-15 10:43:00: (critical) plugin proxy 0.8.5 started -
mysql proxy 负载均衡
mysql-proxy的负载均衡是指连接上的均衡,不是语句
当连接的服务器确定时,不会变动
示例1:切换至本机windows,使用命令窗口连接mysql-proxy
mysql -h 192.168.6.5 -uroot -p123456 -P 4040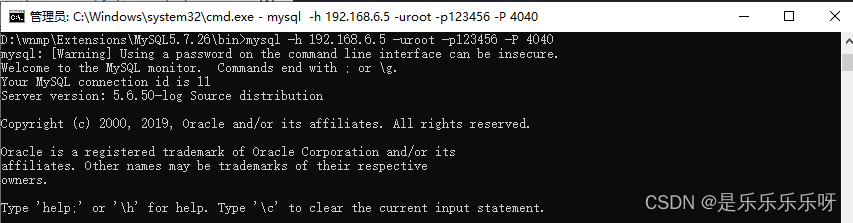
插入2条数据mysql> insert into t(name) values('g'); mysql> insert into t(name) values('h'); mysql> select * from t; +----+------+ | id | name | +----+------+ | 18 | g | | 20 | h | +----+------+可以看到主键都是偶数,可知连接的是B服务器
再打开4个窗口a,b,c,d,分别插入2条数据
mysql> insert into t(name) values('1'); mysql> insert into t(name) values('2');mysql> insert into t(name) values('3'); mysql> insert into t(name) values('4');mysql> insert into t(name) values('5'); mysql> insert into t(name) values('6');mysql> insert into t(name) values('7'); mysql> insert into t(name) values('8');查询数据
mysql> select * from t; +----+------+ | id | name | +----+------+ | 21 | 1 | | 23 | 2 | | 24 | 3 | | 26 | 4 | | 27 | 5 | | 29 | 6 | | 30 | 7 | | 32 | 8 | +----+------+可以看到a,c主键为奇数,b,d主键为偶数
可知a,c窗口连接的是A服务器,另b,d窗口连接的是B服务器 -
mysql-proxy 读写分离
mysql-proxy通过读写分离脚本 rw-splitting.lua,读取分析sql语句,分成不同的类型做判断属于哪个服务器
[root@localhost mysql-proxy]# more share/doc/mysql-proxy/rw-splitting.lua ... ... -- read/write splitting function read_query( packet ) local is_debug = proxy.global.config.rwsplit.is_debug local cmd = commands.parse(packet) local c = proxy.connection.client local r = auto_config.handle(cmd) if r then return r end local tokens local norm_query -- looks like we have to forward this statement to a backend if is_debug then print("[read_query] " .. proxy.connection.client.src.name) print(" current backend = " .. proxy.connection.backend_ndx) print(" client default db = " .. c.default_db) print(" client username = " .. c.username) if cmd.type == proxy.COM_QUERY then print(" query = " .. cmd.query) end end ... ...在后台运行代理服务器,指定 rw-splitting.lua 脚本做读写分离操作,服务器A(192.168.6.3)为可写,服务器B(192.168.6.4)为只读
[root@localhost mysql-proxy]# /usr/local/mysql-proxy/bin/mysql-proxy -b 192.168.6.3:3306 -r 192.168.6.4:3306 -s /usr/local/mysql-proxy/share/doc/mysql-proxy/rw-splitting.lua --daemon 2022-06-16 16:32:11: (critical) plugin proxy 0.8.5 started示例2:
两个服务器表数据分别为:
服务器A
mysql> select * from t; +----+------+ | id | test | +----+------+ | 1 | a | | 2 | b | +----+------+服务器B
mysql> select * from t; +----+------+ | id | test | +----+------+ | 1 | a | +----+------+上例的5个窗口分别查询数据,可以看到连接的都是A服务器
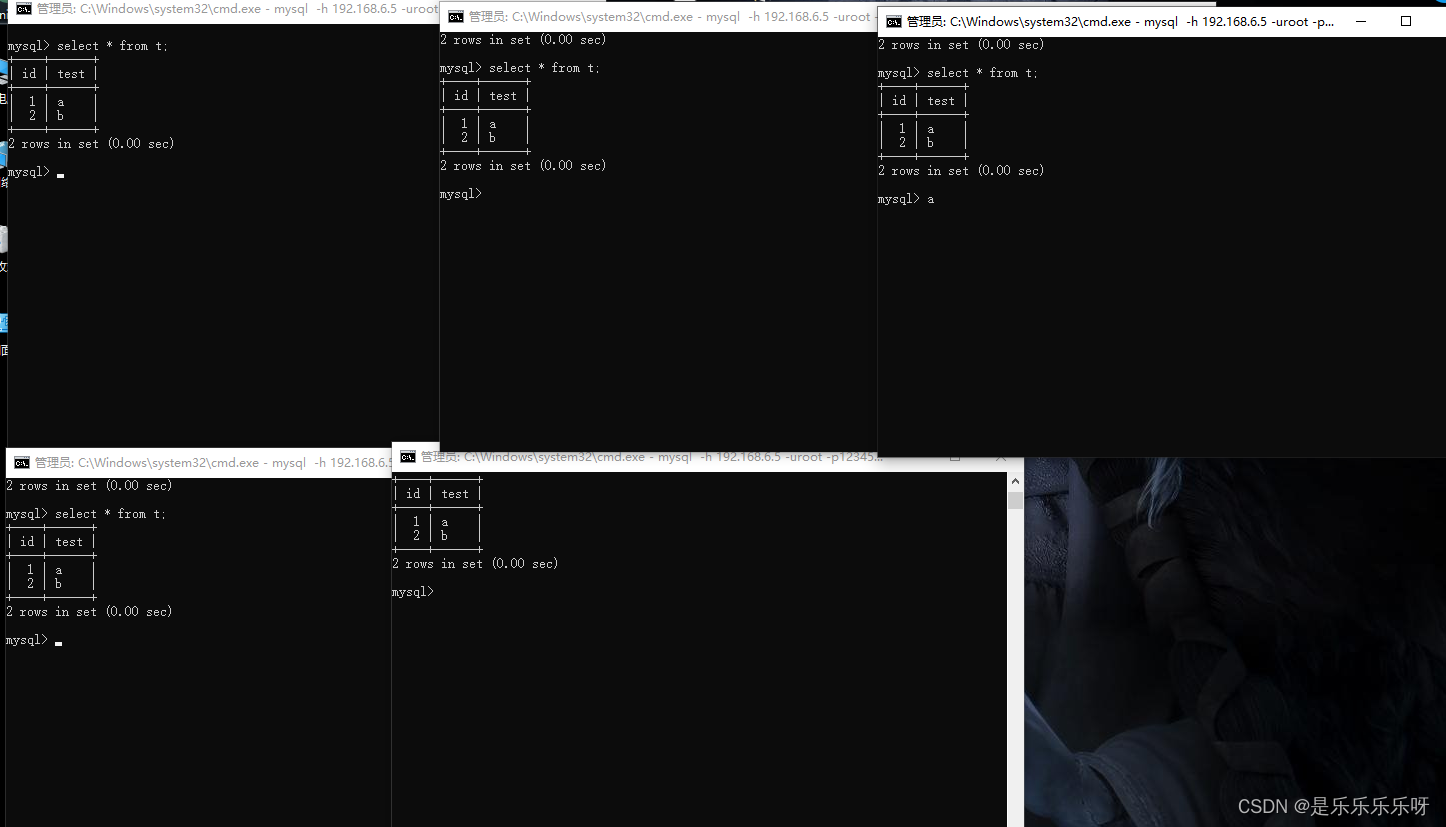
此时未开启读写分离,因为默认最大连接数为8才开启
[root@localhost mysql-proxy]# vi share/doc/mysql-proxy/rw-splitting.lua --- config -- connection pool if not proxy.global.config.rwsplit then proxy.global.config.rwsplit = { min_idle_connections = 4, max_idle_connections = 8, is_debug = false } end修改 min_idle_connections = 1,max_idle_connections = 2 ,重新开启代理
在5个窗口分别查询
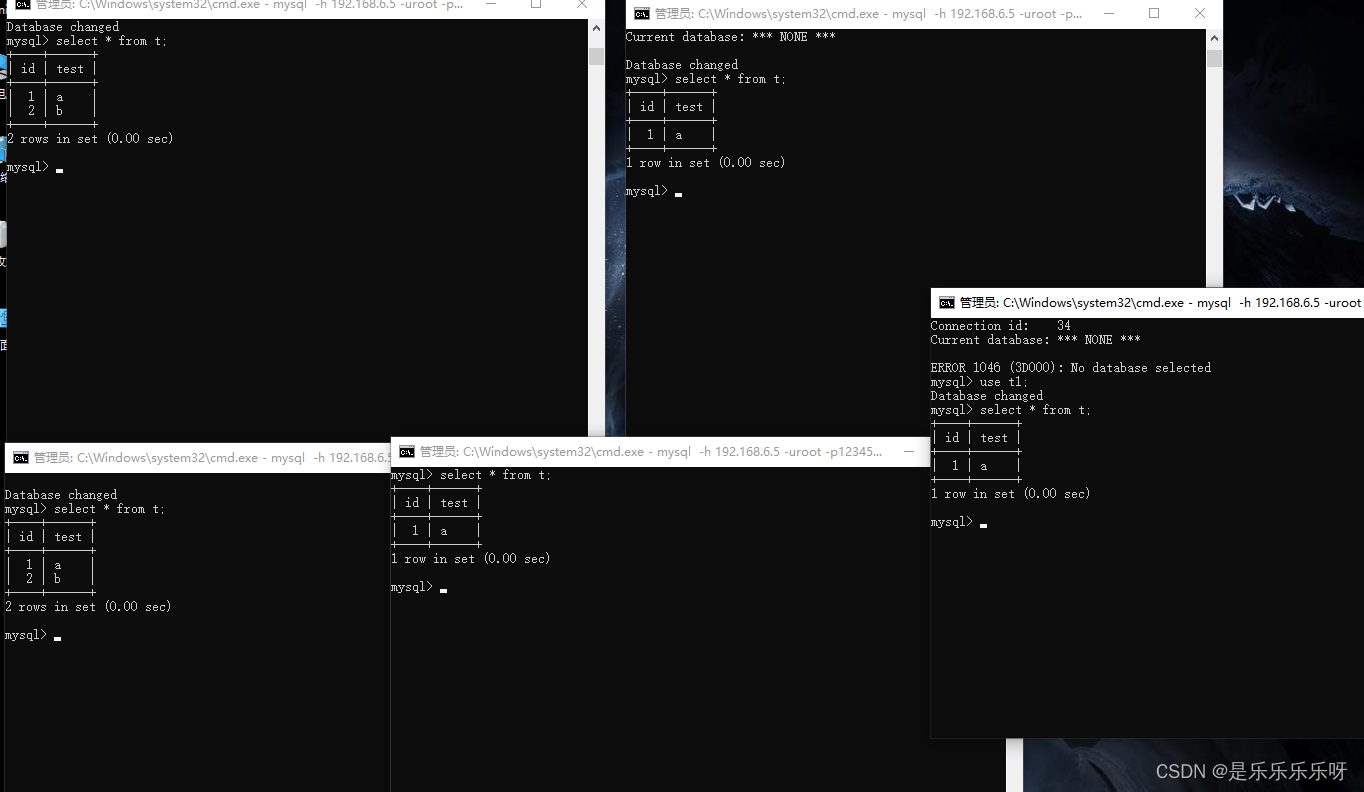 可以看到两个窗口查到A服务器的数据,3个窗口查到B服务器的数据,说明读写分离已经开启
可以看到两个窗口查到A服务器的数据,3个窗口查到B服务器的数据,说明读写分离已经开启在连接只读服务器B的窗口执行插入语句
可以看到数据添加到了A服务器,说明读写分离操作成功
十五、partition分区


按范围分区(range)
示例:
创建分区表,插入数据
mysql> use test;
mysql> create table topic(
-> tid int primary key auto_increment,
-> title char(20) not null default ''
-> )engine myisam charset utf8
-> partition by range(tid)(
-> partition t0 values less than(10),
-> partition t1 values less than(20),
-> partition t2 values less than(MAXVALUE)
-> );
mysql> insert into topic(title) values('a');
查看表文件
[root@localhost test]# cd /www/server/data/test
[root@localhost test]# ll
...
-rw-rw---- 1 mysql mysql 8584 5月 10 11:54 t8.frm
-rw-rw---- 1 mysql mysql 0 5月 10 11:54 t8.MYD
-rw-rw---- 1 mysql mysql 1024 5月 10 11:54 t8.MYI
-rw-rw---- 1 mysql mysql 8618 5月 10 11:57 t9.frm
-rw-rw---- 1 mysql mysql 104 5月 10 13:45 t9.MYD
-rw-rw---- 1 mysql mysql 4096 5月 19 10:38 t9.MYI
-rw-rw---- 1 mysql mysql 8590 6月 17 13:53 topic.frm
-rw-rw---- 1 mysql mysql 32 6月 17 13:53 topic.par
-rw-rw---- 1 mysql mysql 65 6月 17 13:54 topic#P#t0.MYD
-rw-rw---- 1 mysql mysql 2048 6月 17 13:54 topic#P#t0.MYI
-rw-rw---- 1 mysql mysql 0 6月 17 13:53 topic#P#t1.MYD
-rw-rw---- 1 mysql mysql 1024 6月 17 13:53 topic#P#t1.MYI
-rw-rw---- 1 mysql mysql 0 6月 17 13:53 topic#P#t2.MYD
-rw-rw---- 1 mysql mysql 1024 6月 17 13:53 topic#P#t2.MYI
-rw-rw---- 1 mysql mysql 16528 5月 20 14:34 user.frm
-rw-rw---- 1 mysql mysql 10485760 5月 20 14:34 user.ibd
可以看到数据插入到了 topic#P#t0.MYD 文件
把数据存入t1分区
mysql> insert into topic(tid,title) values(11,'b');
可以看到数据存入到了 topic#P#t1.MYD 文件
[root@localhost test]# ll
...
-rw-rw---- 1 mysql mysql 65 6月 17 13:54 topic#P#t0.MYD
-rw-rw---- 1 mysql mysql 2048 6月 17 13:54 topic#P#t0.MYI
-rw-rw---- 1 mysql mysql 65 6月 17 14:06 topic#P#t1.MYD
-rw-rw---- 1 mysql mysql 2048 6月 17 14:06 topic#P#t1.MYI
-rw-rw---- 1 mysql mysql 0 6月 17 13:53 topic#P#t2.MYD
-rw-rw---- 1 mysql mysql 1024 6月 17 13:53 topic#P#t2.MYI
按散落的点分区(list)
示例:
mysql> create table area( aid int, zone char(6))engine myisam charset utf8;
mysql> insert into area values(1,'bj'),(2,'sh'),(3,'hn'),(4,'ah');
mysql> create table users(
-> uid int,
-> uname char(6),
-> aid int
-> )engine myisam charset utf8
-> partition by list(aid)(
-> partition bj values in(1),
-> partition sh values in(2),
-> partition hn values in(3),
-> partition ah values in(4)
-> );
mysql> insert into users(uname,aid) values('zhangsan',1);
mysql> insert into users(uname,aid) values('lisi',2);
mysql> insert into users(uname,aid) values('wangwu',9);
ERROR 1526 (HY000): Table has no partition for value 9
[root@localhost test]# ll
...
-rw-rw---- 1 mysql mysql 8618 6月 17 14:46 users.frm
-rw-rw---- 1 mysql mysql 0 6月 17 14:46 users#P#ah.MYD
-rw-rw---- 1 mysql mysql 1024 6月 17 14:46 users#P#ah.MYI
-rw-rw---- 1 mysql mysql 32 6月 17 14:46 users.par
-rw-rw---- 1 mysql mysql 54 6月 17 14:55 users#P#bj.MYD
-rw-rw---- 1 mysql mysql 1024 6月 17 14:55 users#P#bj.MYI
-rw-rw---- 1 mysql mysql 0 6月 17 14:46 users#P#hn.MYD
-rw-rw---- 1 mysql mysql 1024 6月 17 14:46 users#P#hn.MYI
-rw-rw---- 1 mysql mysql 27 6月 17 14:55 users#P#sh.MYD
-rw-rw---- 1 mysql mysql 1024 6月 17 14:55 users#P#sh.MYI
MYSQL的分区主要有两种形式:水平分区和垂直分区
水平分区
RANGE 分区:基于属于一个给定连续区间的列值,把多行分配给分区。
LIST分区:类似于按RANGE分区,区别在于LIST分区是基于列值匹配一个离散值集合中的某个值来进行选择。
HASH分区:基于用户定义的表达式的返回值来进行选择的分区,该表达式使用将要插入到表中的这些行的列值进行计算。这个函数可以包含MySQL中有效的、产生非负整数值的任何表达式。
KEY分区:类似于按HASH分区,区别在于KEY分区只支持计算一列或多列,且MySQL服务器提供其自身的哈希函数。必须有一列或多列包含整数值。
复合分区:基于RANGE/LIST 类型的分区表中每个分区的再次分割。子分区可以是 HASH/KEY等类型。
垂直分区
这种分区方式一般来说是通过对表的垂直划分来减少目标表的宽度,使某些特定的列被划分到特定的分区,每个分区都包含了其中的列所对应所有行。
十六、事务


示例:
1.隔离级别 read uncommitted
可以读取到另一个未结束事务的结果
mysql> select * from account;
+-------+-------+
| uname | money |
+-------+-------+
| zhang | 5000 |
| li | 4000 |
+-------+-------+
mysql> set session transaction isolation level read uncommitted;
mysql> set transaction;
mysql> update account set money = money +1000 where uname='li';
B窗口查看已到账,取款会提示超时
mysql> set session transaction isolation level read uncommitted;
mysql> select * from account;
+-------+-------+
| uname | money |
+-------+-------+
| zhang | 5000 |
| li | 5000 |
+-------+-------+
mysql> update account set money=money -1000 where uname='li';
ERROR 1205 (HY000): Lock wait timeout exceeded; try restarting transaction

2.隔离级别 read committed
可以读取到另一个结束事务的结果
A窗口
mysql> set session transaction isolation level read committed;
mysql> start transaction;
mysql> update account set money = money +1000 where uname='li';
mysql> commit;
B窗口
mysql> set session transaction isolation level read committed;
mysql> start transaction;
mysql> select * from account;
mysql> select * from account;
+-------+-------+
| uname | money |
+-------+-------+
| zhang | 5000 |
| li | 6000 |
+-------+-------+
3.隔离级别 repeatable read (默认)
不能读取到另一个结束事务的结果
A窗口
mysql> set session transaction isolation level repeatable read;
mysql> start transaction;
mysql> update account set money = money +1000 where uname='li';
mysql> commit;
B窗口
mysql> set session transaction isolation level read committed;
mysql> start transaction;
mysql> select * from account;
+-------+-------+
| uname | money |
+-------+-------+
| zhang | 5000 |
| li | 6000 |
+-------+-------+














 2012
2012











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









