










一 概括
简介
LinkedBlockingQueue(链接阻塞队列)类(下文简称链接阻塞队列)是BlockingQueue(阻塞队列)接口的主要实现类之一,也是Executor(执行器)框架最常搭配使用的实现之一,采用链表的方式实现。相比基于数组的实现,基于链表的实现有着更高的并发量,但是在绝大多数的并发应用中其性能的可预见性较差(即难以预测性能可以达到什么程度)。由于需要额外创建节点(节点是元素的容器,也是队列的组成单位)用于容纳元素的原因,在需要长时间高效并发地处理大批量数据时,对于GC可能存在较大影响(多出了分配内存创建节点以及回收节点的消耗)。链接阻塞队列是一个标准的FIFO队列,新元素会从队列的尾部插入/放置(即尾插法),而元素的移除/拿取则会在队列的头部进行。
链接阻塞队列不允许存null值,或者说BlockingQueue(阻塞队列)接口的所有的实现类都不允许存null值。null被作为poll()及peek()方法(两个方法由Queue(队列)接口定义)作为队列不存在元素的标记值,因此所有的BlockingQueue(阻塞队列)接口实现类都不允许存null值。
链接阻塞队列支持有界及无界两种使用方式,即是否人为限制可保存的元素总数。如果在创建链接阻塞队列时没有指定具体容量,则其便为无界队列。我们并不推荐使用无界队列,由于元素可无限制保存的原因,一旦元素的移除/拿取速率低于其插入/放置的速率,则很容易导致元素大量堆积造成内存溢出错误。因此在实际开发中,还是推荐指定容量的有界队列用法,并根据业务的实际场景及资源的硬性限制选择合适的容量大小。此外,链接阻塞队列在无界队列的实现上并不纯粹,采用的是通过Integer.MAX_VALUE大小的有界队列来模拟无界队列的方式,这在一定程度上违背了无界队列的实现规范,该知识点的详细内容会在下文详述。
链接阻塞队列是线程安全的。线程安全实际上是BlockingQueue(阻塞队列)接口的定义,而链接阻塞队列只是实现了该定义。链接阻塞队列采用一种被称为双锁的线程安全机制(下文简称双锁机制)来保证同步,通俗的讲就是链接阻塞队列在内部创建了放置与拿取两把ReentrantLock(可重入)类对象锁分别用于管理插入/放置及移除/拿取两类方法的同步(即插入/放置方法只会受放置锁的保护,而移除/拿取方法只会受拿取锁的保护),从而在保证线程安全的同时有效的提高并发,该知识点的详细内容会在下文详述。
链接阻塞队列的迭代器是弱一致性,即可能迭代到已移除的元素或迭代不到新插入的元素。弱一致性迭代器可以有效兼容并发的使用环境,使得插入/放置及移除/拿取方法的执行不会导致迭代的中断,该知识点的详细内容会在下文详述。
链接阻塞队列虽然与BlockingQueue(阻塞队列)接口一样都被纳入Executor(执行器)框架的范畴,但同时是Collection(集)框架的成员。
结构
与ArrayBlockingQueue(数组阻塞队列)类的对比
- 链接阻塞队列是基于链表实现的,而ArrayBlockingQueue(数组阻塞队列)类则给予数组实现,这使得在容量较大的情况下数组对象本身也会占用较多内存;
- 链接阻塞队列支持无界队列用法,而ArrayBlockingQueue(数组阻塞队列)类理论上不支持(实际上创建一个容量为int类型最大值的对象也是一样的);
- 链接阻塞队列的线程访问是非公平的,而ArrayBlockingQueue(数组阻塞队列)类支持公平及非公平,这是基于内部的ReentrantLock(可重入锁)类对象实现的;
- 链接阻塞队列使用双锁机制保证线程安全(插入/放置与移除/拿取的锁是分离的),而ArrayBlockingQueue(数组阻塞队列)类使用的则是常规的单锁机制。
方法的不同形式
方法的不同形式实际上是BlockingQueue(阻塞队列)接口的定义,链接阻塞双端队列只是继承了这个定义而已。所谓方法的不同形式,是指方法在保证自身核心操作不变的情况下实现了多种不同的回应形式来应对不同场景下的使用要求。例如对于插入,当容量不足时,有些场景希望在失败时抛出异常;而有些场景则希望能直接返回失败的标记值;而有些场景又希望可以等待直至有可用空间后成功新增为止…正因如此,BlockingQueue(阻塞队列)接口特意提供了四种不同的形式风格以满足不同场景下的使用需求,因此一个方法最多(并非所有方法都实现了四种形式)可能有四种不同回应形式。具体四种回应形式如下:
- 异常:当不满足操作条件时直接抛出异常;
- 特殊值:当不满足操作条件时直接返回失败标记值。例如之所以不允许存null值就是因为null被作为了获取操作失败时的标记值;
- 阻塞(无限等待):当不满足操作条件时无限等待,直至满足操作条件后执行;
- 超时(有限等待):当不满足操作条件时有限等待,如果在指定等待时间之前直至满足操作条件则执行;否则返回失败标记值。
二 创建
-
public LinkedBlockingQueue(int capacity) —— 创建一个指定容量的“有界”链接阻塞队列。该构造方法是现实中使用最多,也是最推荐使用的构造方法。优点在于其容量由开发者预先指定,最大程度的贴合了业务的实际场景及资源的硬性限制。
-
public LinkedBlockingQueue() —— 创建一个容量为Integer.MAX_VALUE的“无界”链接阻塞队列。现实开发中我们不推荐该构造方法,容易导致内存溢出错误(OOM)。
-
public LinkedBlockingDeque(Collection<? extends E> c) —— 创建一个容量为Integer.MAX_VALUE,并按迭代器顺序包含指定集中所有元素的“无界”链接阻塞队列。既然是无界队列,那自然也是不推荐使用的,但该方法在实现上也有值得一说的地方。具体源码及注释如下:
/**
* Creates a {@code LinkedBlockingQueue} with a capacity of {@link Integer#MAX_VALUE}, initially containing the elements of the given collection, added
* in traversal order of the collection's iterator.
* 创建一个容量为int最大值的链接阻塞队列,最初包含指定集的元素,按集的迭代器顺序新增(即按集的迭代器的顺序将元素添加到队列中)。
*
* @param c the collection of elements to initially contain 为了最初包含的元素集
* @throws NullPointerException if the specified collection or any of its elements are null 如果指定元素集中有任何元素为null
*/
public LinkedBlockingQueue(Collection<? extends E> c) {
// 容量为int类型的最大值。
this(Integer.MAX_VALUE);
// 加放置锁,将指定集中的所有元素都添加到队列中。
final ReentrantLock putLock = this.putLock;
putLock.lock();
// Never contended, but necessary for visibility
// 没有竞争,但为了可见性有必要(加锁)。
try {
int n = 0;
for (E e : c) {
if (e == null)
throw new NullPointerException();
// 如果队列满了,也要抛出异常。
if (n == capacity)
throw new IllegalStateException("Queue full");
enqueue(new Node<E>(e));
++n;
}
// 设置总数。
count.set(n);
} finally {
putLock.unlock();
}
}
我们可以在上述的源码中发现将指定集中的元素存入链接阻塞队列的整个过程是加了锁的,而源码给出的英文注释是“没有竞争,但为了可见性有必要(加锁)”。其中本人对可见性是可以理解的(如果理解没有错的话):如果在过程中没有加锁,就会出现并发中其它线程获取到节点但获取不到元素的情况(即节点中不包含元素)。为什么会出现这样的问题呢?这是因为在Java中对象的创建不是原子操作,整个过程按顺序大致可分为以下三部分:
- 实例化(分配内存);
- 初始化(执行构造方法);
- 引用赋值(令变量持有对象的引用)。
但现实中由于指令重排序的原因,具体在执行中顺序就可能变成:
- 实例化(分配内存);
- 引用赋值(令变量持有对象的引用);
- 初始化(执行构造方法)。
这就意味着加入到链接阻塞队列中的节点可能是个空节点(即还未完成初始化的过程)。如此一来,如果有线程在链接阻塞队列构造方法执行结束后获取元素,则其获取到的节点中元素完全可能是空的,因此整个过程必须在锁的保护下执行。锁的存在虽然无法避免同步块中的指令重排序,但可以避免其重排序到同步块外,这就使得节点的初始化一定会在同步块中完成,确保队列创建完成后其它线程获取到的节点一定是完整的(存在元素的)。
如果上述我的理解都是对的,那就有一个讲不通的地方就是既然对象的创建不是原子操作,那么在不加锁的情况下,完全可能存在有线程向一个未执行初始化(或未执行完初始化)的链接阻塞队列保存元素的可能,如此应该是可能存在竞争的,而不是英文注释中说的“没有竞争”,这也是我目前尚未完全理解的地方…当然,也可能是我对可见性的理解本就是错的,希望有懂的同学能在评论区不吝赐教,本人万分感谢。
无界队列
上文已经提及过链接阻塞队列在无界队列的实现上并不纯粹,观察上述罗列的构造方法其实也可以看出链接阻塞队列的无界队列用法实质上是通过有界队列用法模拟实现的。通过创建一个指定容量为Integer.MAX_VALUE的有界队列,确实可以达到与无界队列基本一致的效果,从而简化了链接阻塞队列的实现,但由于该方案毕竟不是无界队列的标准实现,故而如此获得的“无界”队列与真正的无界队列还是存在部分差异的。
标准无界队列的容量只受限于堆内存的大小。当然,这是逻辑上的说法,在实现中其可能会受到具体的物理限制(例如int类型的空间制约),但这属于被动情况,并且当触发该类限制时也会模拟堆内存不足的场景手动抛出内存溢出错误来掩盖真实原因。除此之外,BlockingQueue(阻塞队列)接口还规定对于无界队列,当获取其剩余容量时需强制返回Integer.MAX_VALUE表示容量无限,诸如PriorityBlockingQueue(优先级阻塞队列)类、DelayQueue(延迟队列)类及LinkedTransferQueue(链接迁移队列)类等无界队列在实现上皆是如此。
链接阻塞队列的无界队列用法与标准无界队列的差异如下。也正是因为下列几点,虽然在说法上称链接阻塞队列支持有界及无界两种使用方式,但个人一直将之视为纯粹的有界队列。
- 人为的限制了容量,该容量虽然等同于Integer.MAX_VALUE,但由“被动”转为“主动”使得自身性质发生了根本性改变,成为了实际的有界队列;
- 当元素总数达到Integer.MAX_VALUE时并不会抛出内存溢出错误,而是抛出非法状态异常,或是因为其它方法形式而返回特殊值/无限阻塞/有限阻塞,使得真实的异常原因暴露在外。而对于无界队列来说,无论方法形式如何,都只应该抛出内存溢出错误;
- 获取剩余容量时不会返回Integer.MAX_VALUE表示容量无限,而是返回真实的剩余容量。
三 方法
插入/放置
插入/放置是链接阻塞队列两大最核心也是最常用的方法之一,用于向阻塞队列的尾部插入指定元素。插入/放置方法受双锁中放置锁的保护以确保同步,因此在同一时刻内最多只会存在一个执行插入/放置方法的线程(下文简称放置者)。由于场景的多样性需求,链接阻塞队列定义了该类方法四种形式的实现以供使用(更准确的说,这四种形式是由BlockingQueue(阻塞队列)接口定义的,包括后续的移除/拿取及检查)。
- public boolean add(E e) —— 新增 —— 向当前链接阻塞队列的尾部插入指定元素。该方法是插入/放置方法“异常”形式的实现,当链接阻塞队列存在剩余容量时插入/放置成功并返回true;否则抛出非法状态异常。链接阻塞队列并没有自实现add(E e)方法,而是直接使用了父类AbstractQueue(抽象队列)抽象类的实现(具体源码如下)。在实现中其调用了插入/放置方法“特殊值”形式的offer(E e)方法来达成目的,使得所有AbstractQueue(抽象队列)抽象类的子类只需实现offer(E e)方法后就可以正常调用add(E e)方法。这种代码结构是设计模式的一种,被称为“模板模式”。
/**
- Inserts the specified element into this queue if it is possible to do so immediately without violating capacity restrictions, returning <tt>true</tt>
- upon success and throwing an <tt>IllegalStateException</tt> if no space is currently available.
- 再没有违背容量限制的情况下并指定元素插入至队列,并在成功之后返回true。如果当前没有可用空间则抛出非法状态异常。
- <p>
- This implementation returns <tt>true</tt> if <tt>offer</tt> succeeds, else throws an <tt>IllegalStateException</tt>.
- 该实现如果offer()方法成功则返回true,否则抛出一个非法状态异常(该方法底层是通过调用offer()方法实现的,而offer()方法则交由子类进行
- 实现,故而子类可以无需实现add()方法,这是一种模板模式的使用)。
- - @param e the element to add 新增的元素
- @return <tt>true</tt> (as specified by {@link Collection#add}) true(具体看Collection#add方法文档)
- @throws IllegalStateException if the element cannot be added at this time due to capacity restrictions
- 非法状态异常:如果元素当前由于容量限制无法新增
- @throws ClassCastException if the class of the specified element prevents it from being added to this queue
- 类型转换异常:如果指定元素的类妨碍其新增至队列
- @throws NullPointerException if the specified element is null and this queue does not permit null elements
- 空指针异常:如果元素为null并且该队列不允许null元素
- @throws IllegalArgumentException if some property of this element prevents it from being added to this queue
- 非法参数异常:如果元素的特性妨碍其新增至队列
*/
public boolean add(E e) {
// 调用offer(E)方法。
if (offer(e))
// 如果调用成功,直接返回true。
return true;
else
// 如果调用失败,抛出一个非法状态异常。
throw new IllegalStateException("Queue full");
}
-
public boolean offer(E e) —— 新增 —— 向当前链接阻塞队列的尾部插入指定元素。该方法是插入/放置方法“特殊值”形式的实现,当链接阻塞队列存在剩余容量时插入/放置成功并返回true;否则返回false。
-
public void put(E e) throws InterruptedException —— 放置 —— 向当前链接阻塞队列的尾部插入指定元素。该方法是插入/放置方法“阻塞”形式的实现,当链接阻塞队列存在剩余容量时插入/放置成功;否则等待至存在剩余容量为止。
-
public boolean offer(E e, long timeout, TimeUnit unit) throws InterruptedException —— 提供 —— 向当前链接阻塞队列的尾部插入指定元素。该方法是插入/放置方法“超时”形式的实现,当链接阻塞队列存在剩余容量时插入/放置成功并返回true;否则在指定等待时间内等待至存在剩余容量,超出指定等待时间则返回false。
移除/拿取
移除/拿取是链接阻塞队列两大最核心也是最常用的方法之一,用于从阻塞队列的头部移除并获取元素。移除/拿取方法受双锁中拿取锁的保护以确保同步,因此在同一时刻内最多只会存在一个执行移除/拿取方法的线程(下文简称拿取者)。移除/拿取方法同样有四种形式的实现。
public E remove() —— 移除 —— 从当前链接阻塞队列的头部移除并获取元素。该方法是移除/拿取方法中“异常”形式的实现,当链接阻塞队列存在元素时移除/拿取并返回头元素;否则抛出无如此元素异常。链接阻塞队列并没有自实现remove()方法,而是直接使用了父类AbstractQueue(抽象队列)抽象类的实现(具体源码如下)。在实现中其调用了移除/拿取方法“特殊值”形式的poll()方法来达成目的,使得所有AbstractQueue(抽象队列)抽象类的子类只需实现poll()方法后就可以正常调用remove()方法。这种代码结构是设计模式的一种,被称为“模板模式”。
/**
* Retrieves and removes the head of this queue. This method differs from {@link #poll poll} only in that it throws an exception if this queue is empty.
* 检索并移除队列的头。该方法不同于poll()方法,如果队列为空时其会抛出一个异常。
* <p>
* This implementation returns the result of <tt>poll</tt> unless the queue is empty.
* 除非队列为空,否则该实现返回poll()的结果。
*
* @return the head of this queue 队列的头(元素)
* @throws NoSuchElementException if this queue is empty
* 无元素异常:如果队列为空
*/
public E remove() {
// 调用poll()方法获取元素。
E x = poll();
if (x != null)
// 如果元素存在,直接返回。
return x;
else
// 如果元素不存在,抛出无元素异常。
throw new NoSuchElementException();
}
-
public E poll() —— 轮询 —— 从当前链接阻塞队列的头部移除并获取元素。该方法是移除/拿取方法中“特殊值”形式的实现,当链接阻塞队列存在元素时移除/拿取并返回头元素;否则返回null。
-
public E take() throws InterruptedException —— 拿取 —— 从当前链接阻塞队列的头部移除并获取元素。该方法是移除/拿取方法中“阻塞”形式的实现,当链接阻塞队列存在元素时移除/拿取并返回头元素;否则等待至存在元素。
-
public E poll(long timeout, TimeUnit unit) throws InterruptedException —— 轮询 —— 从当前链接阻塞队列的头部移除并获取元素。该方法是移除/拿取方法中“超时”形式的实现,当链接阻塞队列存在元素时移除/拿取并返回头元素;否则在指定等待时间内等待至存在元素,超出指定等待时间则返回null。
检查
检查也是阻塞队列的常用方法之一,用于从阻塞队列的头部获取元素,但并不会将元素从阻塞队列中移除,属于移除/拿取方法的阉割版,因此也属于拿取锁的保护范围。检查方法同样具备多形式的实现,但只有“异常”与“特殊值”两种。
- public E element() —— 元素 —— 从当前链接阻塞双端队列的头部获取元素。该方法是头部检查方法中“异常”形式的实现,当链接阻塞双端队列存在元素时返回头元素;否则抛出无如此元素异常。链接阻塞队列并没有自实现element()方法,而是直接使用了父类AbstractQueue(抽象队列)抽象类的实现(具体源码如下)。在实现中其调用了检查方法“特殊值”形式的peek()方法来达成目的,使得所有AbstractQueue(抽象队列)抽象类的子类只需实现peek()方法后就可以正常调用element()方法。这种代码结构是设计模式的一种,被称为“模板模式”。
/**
* Retrieves, but does not remove, the head of this queue. This method differs from {@link #peek peek} only in that it throws an exception if this
* queue is empty.
* 检索,但不移除队列的头(元素)。该方法不同于peek()方法,如果队列为空时其会抛出一个异常。
* <p>
* This implementation returns the result of <tt>peek</tt> unless the queue is empty.
* 除非队列为空,否则该实现返回peek()的结果。
*
* @return the head of this queue 队列的头(元素)
* @throws NoSuchElementException if this queue is empty
* 无元素异常:如果队列为空
* @Description: 元素:用于返回队列的头元素(但不移除)。当队列中不存在元素时抛出无元素异常。
*/
public E element() {
E x = peek();
if (x != null)
return x;
else
throw new NoSuchElementException();
}
- public E peek() —— 窥视 —— 从当前链接阻塞队列的头部获取元素。该方法是头部检查方法中“特殊值”形式的实现,当链接阻塞队列存在元素时返回头元素;否则返回null。
迁移
迁移也是阻塞队列的常用方法之一,用于将阻塞队列中的元素迁移至指定集中,迁移后的元素不再存在于阻塞队列中。为了避免迁移过程中元素丢失问题,实现往往会先将元素加入指定集中后再将元素从阻塞队列中移除。
- public int drainTo(Collection<? super E> c) —— 流失 —— 将当前链接阻塞队列中的所有元素迁移至指定集中,并返回迁移的元素总数。
- public int drainTo(Collection<? super E> c, int maxElements) —— 流失 —— 将当前链接阻塞队列中的最多指定数量的元素迁移至指定集中,并返回迁移的元素总数。
内部移除
内部移除的原始方法定义源自Collection(集)接口的remove(Object o)方法,用于将集中指定元素的首个单例(迭代器顺序)移除。由于指定元素可能处于集中的任意位置(不一定是头/尾),因此被称为内部移除。内部移除在队列中并不是常用的方法:一是其不符合队列FIFO的数据结构;二是各类队列为了提高性能可能会使用各种优化策略,而remove(Object o)方法往往无法适配这些策略,导致性能较/极差。
- public boolean remove(Object o) —— 移除 —— 从当前链接阻塞队列中移除指定元素的首个单例,移除成功返回true;否则返回false。
其它
除了上述提及的主要方法之外,链接阻塞队列还有一些常用方法如下所示:
- public int size() —— 大小 —— 获取当前链接阻塞队列中的元素总数。
- public int remainingCapacity() —— 剩余容量 —— 获取当前链接阻塞队列的剩余容量。
- public Object[] toArray() —— 转化数组 —— 获取一个按迭代器顺序包含当前链接阻塞队列中所有元素的数组。
- public T[] toArray(T[] a) —— 转化数组 —— 获取一个按迭代器顺序包含当前链接阻塞队列中所有元素的泛型数组。如果参数泛型数组长度足以容纳所有元素,则令之承载所有元素后返回。并且如果参数泛型数组的长度大于当前链接阻塞双端队列的元素总数,则将已承载所有元素的参数泛型数组的size索引位置设置为null,表示从当前链接阻塞双端队列中承载的元素到此为止。当然,该方案只对不允许保存null元素的集有效。如果参数泛型数组的长度不足以承载所有元素,则重分配一个相同泛型且长度与当前链接阻塞双端队列元素总数相同的新泛型数组以承接所有元素后返回。
- public void clear() —— 清理 —— 移除当前链接阻塞队列中的所有元素。
事实上,由于链接阻塞队列是Collection(集)接口的实现类,因为其也实现了其定义的所有方法,例如contains(Object o)、remove(Object o)及 toArray()等。但由于这些方法的执行效率不高,并且与链接阻塞队列的主流使用方式并不兼容,因此一般情况下是不推荐使用的,有兴趣的可以去查看源码实现。
四 双锁机制
链接阻塞队采用双锁机制来保证线程安全。所谓双锁机制,是指链接阻塞队列在内部创建了放置与拿取两把ReentrantLock(可重入)类对象锁,分别用于管理插入/放置及移除/拿取两类方法的同步(即插入/放置方法只会受放置锁的保护,而移除/拿取方法只会受拿取锁的保护)。如此设计的原因是由于调用最为频繁的插入/放置及移除/拿取方法分别在链接阻塞队列的两端发生,因此二者基本不存在资源的竞争问题,完全可以在大多数情况下实现两类方法的并发(基本不存在,但还是已存在的,下文有详述)。故而使用双锁机制不仅可以保证单类方法的同步执行,还允许两类方法的并发执行,有效的提高了队列的并发性能。
双锁机制虽然优秀,但也并非尽善尽美:首先,由于双锁机制是专为插入/放置及移除/拿取这两类方法的执行特性而设计,因此也只适用于这两类或操作本质与之相同(例如drainTo()方法)的方法。而对于类的其它方法而言为了保证线程安全性就必须加双锁,这增加了线程同步的成本。例如实现自Collection(集)接口的remove(Object o)方法的作用是从队列中移除指定元素,由于指定元素可能存在于队列的任意位置,因此虽然也是移除,但并不符合移除/拿取方法的执行特性(从队列头部移除),因此必须在双锁的保护下执行…不过由于这些方法的共性是性能较低,并且也只是为了偶尔的使用而保留,因此一般较少也不推荐使用,故而整体影响不大;其次想要正确的使用双锁机制至少有两个问题需要解决:
- 维护“总数”的正确性;
- 单元素时的安全并发。
维护“总数”的正确性
所谓总数,即队列中元素的数量,是代码逻辑中一个至关重要的运行数据及判断依据,关系着能否获取到正确的元素总数/剩余容量,挂起的放置者/拿取者是否应该唤醒以及放置者能否插入/放置,拿取者能否移除/拿取等一系列操作能否正确执行,因此总数必须保证绝对的正确,即与队列实际的元素总数保持强一致。
维护总数正确性的最终目的是实现总数快照(总数是保存在主内存中的共享数据,线程从主内存中读取共享数据时会在其工作内存中储存数据的拷贝,也被称为快照)的可靠性,而总数快照可靠性必须在总数正确性的基础上实现。那又为何要实现总数快照的可靠性呢?这是因为总数快照是是否执行插入/放置及移除/拿取两类方法的判断依据(总数快照等于容量,即队列已满时无法进行插入/放置,而总数快照等于0时无法进行移除/拿取),如果总数快照不可靠,那这两类方法必然也是不可靠的。
总数的正确性由于受插入/放置及移除/拿取两类方法的影响,并且两类方法又允许并发,那根据常规做法,应该将对其的修改同时置于两把锁的保护下进行以保证同步。这不仅确保总数的正确性,甚至还确保了总数快照的正确性,因为在双锁的保护下程序是不存在并发的(请注意!!!这里我们形容总数快照时用的是正确性,而不是可靠性。所谓快照的正确性是指其与主数据保持强一致。正确的一定是可靠的,但可靠的并不一定是正确的。在并发环境中,我们并无法保证快照的正确性,因为其终究只是主数据的拷贝,而主数据完全可能已被其它线程所修改,那在这种情况下,快照就是错误的。而由于错误的快照也可能可靠,那此时快照是否可靠就变得难以揣测,除非我们能够得知主数据的变化趋势进行具体的分析)。可如此做法显然破坏了方案的整体基调,双锁机制不但没有带来任何收益,反而成为了额外的负担(即插入/放置时需要额外获取拿取锁,而移除/拿取时又需要额外获取放置锁,这不但造成了两类操作的再次阻塞,还徒增了一个锁的消耗)。为了避免这一点,链接阻塞队列采用的方案是将用于记录总数的count(总数)字段设计为AtomicInteger(原子整数)类型以使得对其的操作呈原子性,具体如下:
/**
* Current number of elements
* 当前元素数量
*
* @Description: 总数:记录当前队列中元素的数量。
*/
private final AtomicInteger count = new AtomicInteger();
AtomicInteger(原子整数)类是一个基于乐观锁实现的线程安全的整数类,其使得对count(总数)字段的修改都转变为了原子操作,这就意味着“总数”必然是正确的(都已经原子操作了怎么可能还不正确…除非用的不对),达成了实现总数快照可靠性的先决条件,并且也没有破坏插入/放置及移除/拿取两类方法间的并发,那么接下来要做的就是保证总数快照在两类方法中的可靠性。我们已知的是正确的一定是可靠的,那AtomicInteger(原子整数)类型的count(总数)字段能保证总数快照在两类方法的单锁场景下的正确性吗?不行!因为上文已经强调过无法保证并发环境中快照的正确性…那可靠性呢?答案是可以。
我们来仔细分析一下这个过程,首先直接跳过可能正确的情况,因为正确的一定是可靠的,故而没有分析的必要。在认定总数快照一定错误的情况下(即总数已被其它线程修改),如何判定其是否可靠呢?这就需要根据总数的变化趋势来进行判断,具体的模拟场景如下:
| 放置者(插入/放置) | 拿取者(移除/拿取) | |
|---|---|---|
| T01 | 获取放置锁 | |
| T02 | 获取总数快照(5)以判断队列是否已满(否) | |
| T03 | 获取拿取锁 | |
| T04 | 获取总数快照(5)以判断队列是否为空(否) | |
| T05 | 从队列头部移除/拿取元素(实际元素总数4) | |
| T06 | 原子操作递减总数(5 - 1 = 4) | |
| T07 | 从队列尾部插入/放置元素(实际元素总数5) | |
| T08 | 原子操作递增总数(4 + 1 = 5) | |
| T09 | 解除放置锁 | |
| T10 | 解除拿取锁 |
上述的模拟场景仅仅是一个示例,实际上我们可以列举出很多相似的场景。但无一例外我们都会发现,无论在放置者执行插入/放置方法期间,有多少拿取者(串行)执行了移除/拿取方法,都只会使总数在原有5的基础上进一步减少,并不会破坏放置者执行插入/放置的前提,即“总数快照(5)小于容量”;反之亦然,无论在拿取者执行移除/拿取方法期间,有多少放置者(串行)执行了插入/放置方法,都只会使总数在原有5的基础上进一步增加,也不会破坏拿取者执行移除/拿取的前提,即“总数快照(5)大于0”。因此我们可以得到一个结论:判断错误快照是否可靠的关键在于判断并发执行的操作是否会破坏“以快照作为判断依据并成立的判断结果”。而很显然,放置者与拿取者的并发执行并不会对方造成破坏,也因此,其各自的总数快照无论正确错误都是可靠的。
单元素时的安全并发
双锁机制虽然在绝大多数的情况下并不存在元素的竞争问题,但是细心的同学肯定很快就想到了一种场景 —— 队列中仅存在单元素。没错,这的确也是双锁机制中仅有的存在线程安全问题的场景。当放置者和拿取者都判断到队列只剩单个元素时,放置者要在其的基础上进行插入/放置,而拿取者则是要将之移除/拿取,那么就可能发生类似于以下场景的线程安全问题(注:由于队列中只存在一个元素,因此用于持有头节点引用的head(头)字段与用于持有尾节点引用的last(尾/最后)字段指向的都是同一个节点):
| 放置者(插入/放置) | 拿取者(移除/拿取) | |
|---|---|---|
| T01 | 获取放置锁 | |
| T02 | 获取总数快照(1)以判断队列是否已满(否) | |
| T03 | 获取拿取锁 | |
| T04 | 获取总数快照(1)以判断队列是否为空(否) | |
| T05 | 通过head(头)字段获取头节点,并将之移除/拿取(实际元素总数0) | |
| T06 | 由于队列已不存在节点,将head(头)字段赋值为null | |
| T07 | 通过last(尾/最后)字段获取尾节点,于其后插入/放置(实际元素总数1) | |
| T08 | 将last(尾/最后)字段赋值为新插入/放置的节点 | |
| T09 | 由于队列已不存在节点,将last(尾/最后)字段赋值为null | |
| T10 | 原子操作递减总数(1 - 1 = 0) | |
| T11 | 原子操作递增总数(0 + 1 = 1) | |
| T12 | 解除放置锁 | |
| T13 | 解除拿取锁 |
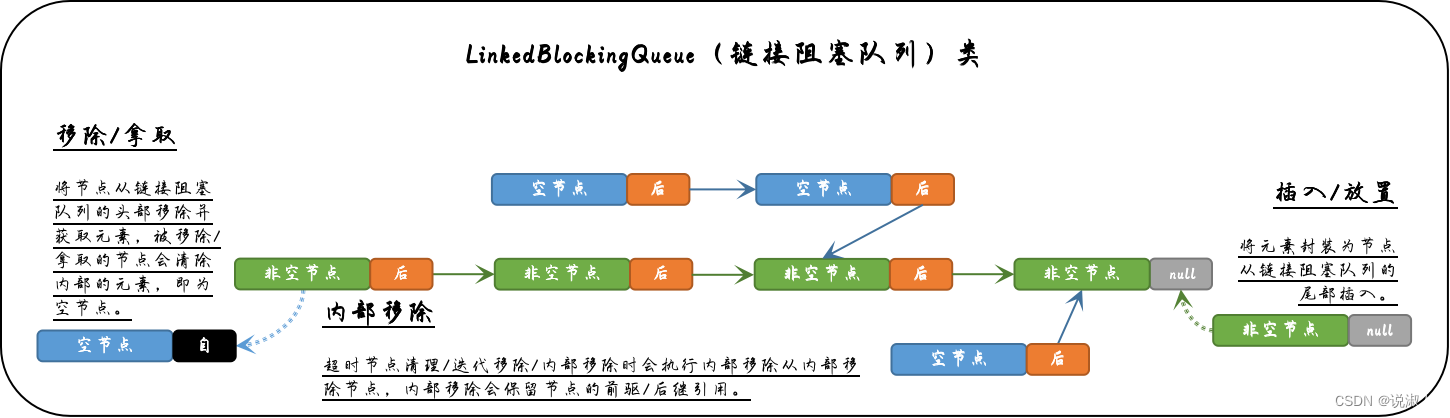
虽然只是列举了一个场景,但已足以说明“在单元素场景下,双锁机制依然存在线程安全问题”。如何解决这个问题呢?加双锁?这种不切实际的事情就别想了…事实上,链接阻塞队列采用了一个很常规的方案:预留一个空节点作为头节点。
所谓的空节点,即不容纳具体元素的节点。将空节点作为头节点是基于链表实现的API中非常常见的做法,例如AQS就是如此,因此其还有一个专属名词:dummy node(哨兵节点)。一般来说使用空节点的目的是为了避免插入首个节点时所需要进行的特殊判断,从而令首个节点可以按常规流程加入链表。那这和我们上文提及的问题有什么关系呢?有的,因为空节点可以避免资源竞争问题。所谓单线程场景下,双锁机制的线程安全问题,本质其实就是线程在没有同步的情况下竞争资源。那解决思路自然也就存在两种:一是保证同步;而是避免资源竞争。所谓保证同步就是加双锁,显然不可能采用这样的思路,那避免资源竞争恰好就是双锁机制的立身之本(除了单元素场景外,插入/放置与移除/拿取两类操作是不存在资源竞争问题的),因此自然是首选,而具体的方案就是空节点。
由于空节点充当了头节点,因此在单元素场景下当拿取者执行移除/拿取操作时,其虽然会将首个非空节点(即空节点的首个后继节点)中保存的元素用于返回,但真正移除/拿取的实际上是空节点,而被获取了元素的非空节点则会转变空节点成为新的头节点保留在队列中(虽然移除的是空节点,但是由于元素所在的节点成为了新的空节点,因此变相等价于元素所在的节点被移除)。如此以来就避免了移除/拿取操作对last(尾/最后)字段的影响(尾节点依然保留在队列中,只不过于此同是它还成为了头节点/空节点),避免了对资源的竞争,自然也就避免了与放置者的并发时的线程安全问题。两者的运行流程大致如下:
| 放置者(插入/放置) | 拿取者(移除/拿取) | |
|---|---|---|
| T01 | 获取放置锁 | |
| T02 | 获取总数快照(1)以判断队列是否已满(否) | |
| T03 | 获取拿取锁 | |
| T04 | 获取总数快照(1)以判断队列是否为空(否) | |
| T05 | 通过head(头)字段获取头节点,并将之移除/拿取(实际元素总数0) | |
| T06 | 将head(头)字段赋值为原头节点的后继节点 | |
| T07 | 通过last(尾/最后)字段获取尾节点,于其后插入/放置(实际元素总数1) | |
| T08 | 将last(尾/最后)字段赋值为新插入/放置的节点 | |
| T09 | 原子操作递减总数(1 - 1 = 0) | |
| T10 | 原子操作递增总数(0 + 1 = 1) | |
| T11 | 解除放置锁 | |
| T12 | 解除拿取锁 |
五 弱一致性迭代器
链接阻塞队列自身实现了弱一致性的迭代器。所谓弱一致性,即数据最终会达成一致,但可能存在延迟。具体表现在迭代器中即是迭代得到一个已从队列中移除的元素。大致表现如下:
| 迭代者(即执行迭代的线程) | 移除者(执行移除/拿取方法及remove(Object o)方法的线程) | |
|---|---|---|
| T01 | 实例化迭代器,通过head(头)字段获取头节点,并获取其后继节点/元素A(队列首个非空节点)并保存,以备迭代 | |
| T03 | 移除/拿取元素A | |
| T07 | 迭代获取元素A,并获取节点B的后继节点/元素B并保存,以备迭代 | |
| T08 | 迭代获取元素B,并获取节点B的后继节点/元素C并保存,以备迭代 | |
| T09 | remove(Object o)方法移除元素C | |
| T10 | 迭代获取元素C,并获取节点B的后继节点/元素D并保存,以备迭代 |
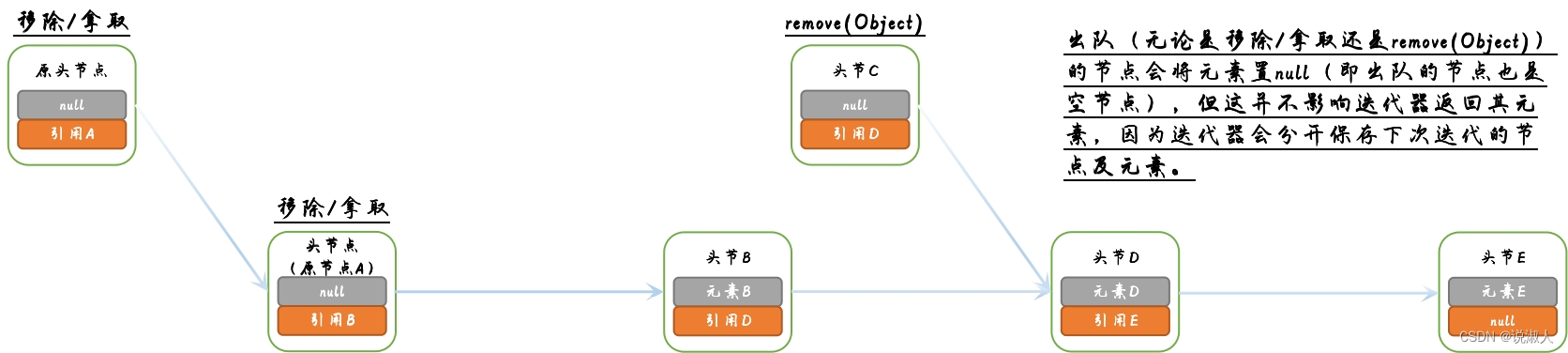
上述表格中重点标红的两句是实现弱一致性的关键。可以发现,无论是移除/拿取还是remove(Object o)方法都不会影响迭代器的正常迭代。这是因为链接阻塞队列为了实现弱一致性迭代器做了两步关键的操作:
- 迭代器保存了下次迭代节点/元素的快照:由于迭代器保存了下次迭代的节点/元素的快照,因此即使下次迭代时节点/元素实际已从链接阻塞队列中移除,迭代器也依然可以返回迭代元素。与之相应的是如果迭代器已判断下次迭代的节点/元素为null,则即使插入了新元素也无法被迭代,因为迭代器已经判定迭代完整结束。如此一来就实现了弱一致性“可能迭代到已移除的元素或迭代不到新插入的元素”的特点。
- 节点被移除(移除/拿取、内部移除)后不会断开后继引用:由于节点不会断开后继引用,因此即使节点已经被判定为下次迭代的节点且被移除(移除/拿取、内部移除),迭代器依然可以继续通过其持有引用访问到其在链接阻塞双端队列中的首个后继节点,从而避免迭代过程的异常中断。由于在迭代器两次迭代之间可能有多个节点被连续的移除(多发生于移除/拿取中,内部移除的可能性较小),因此如果发现后继节点同样已从链接阻塞双端队列中移除(通过查看节点中的元素是否为null判断),则需要连续的后遍历,直至找到首个存在于链接阻塞队列的后继节点作为下次迭代的节点/元素为止。
虽说通过上述两步操作成功实现了迭代器的弱一致性,但与此同时两者也各自带来了一个问题…并且只能解决其中的部分:
- 移除节点/元素可能在迭代器中长期保留;
- 可能导致的频繁老年代GC。
移除节点/元素可能在迭代器中长期保留
由于迭代器会提前保存迭代的节点/元素,因此即使该节点/元素已从链接阻塞队列中被移除,也可能无法被GC回收,因为迭代器还持有其引用。该问题的关键在于这种保留在时间上是难以预测的,即可能是短期、长期、甚至是永久保存。这完全取决于迭代器的迭代频率,而频率又与具体的业务相关。频率高就是短期,低就是长期,不调用就是永久。事实上,该问题也是所有弱一致性迭代器的共性,是难以被解决的。但所幸的是发生该问题的概率不高,并且也只会导致少许对象被延迟回收或浪费少量存储空间,因此并不会产生较大的负面影响。
可能导致的频繁老年代GC
由于被移除(移除/拿取、内部移除)的节点不会断开后继引用,那就可能造成这样一种情况:由于移除(移除/拿取、内部移除)操作的不断执行,使得在链接阻塞队列外也形成一条条空节点链(下文简称外链),并最终与队内节点相连接。大致示例如下:

上图看起来并无不妥,无外乎残留了部分无效节点节点,只需等待GC慢慢回收即可。事实上也确实如此,Java的GC太过智能,以至于我们往往/从来不会考虑垃圾回收的具体过程。实际上虽然无需亲自执行回收,但开发者仍有义务保证GC准确高效的执行。在上述所示情况中存在这样一种场景:外链中存在部分空节点存活于老年代,并与后继存活于新生代的节点相连,造成跨带引用的现象。示例如下:

跨带引用是非常难以处理的。在跨带引用中,为了回收被引用的新生代对象,必须先强制执行老年代对象的回收。老年代的Major GC本身就是不频繁的(因为老年代的对象存活周期一般都比较长),并且执行速度也远比新生代的Minor GC慢得多(有资料说至少有10倍以上的差距),因此在实际开发中要时刻注意避免。在当前场景中,为了回收外链中处于新生代的空节点,必须先触发老年代的Minor GC。这本质上不算太过严重的问题,一次跨带引用并不会对程序带来多少影响…但问题的关键在于程序在不断的运行,每时每刻都有新的元素被插入/放置,同样也不断会有元素被移除(移除/拿取、内部移除)。这就意味着外链会一次又一次的形成,从而频繁的导致跨带引用。
为了解决这一点(即在保证迭代器弱一致性的基础上避免跨带引用),链接阻塞队列采用的方案是将移除/拿取的节点的后继引用设置为自引用,之所以不设置null是因为null是尾节点的标志。节点自引用有两大作用:一是移除/拿取的节点不再具有其它节点的后继引用,那自然也就不会再出现跨带引用的问题;二是其可以作为迭代器的标记位使用。当迭代器迭代是发现节点是自引用时,就说明该节点已经因为移除/拿取出队了,这就意味着其首个存在于链接阻塞双端队列的后继节点必然是头节点,因此会直接跳跃至链接阻塞双端队列的头部继续进行迭代。

上述操作虽然精妙,但遗憾的是该操作并不能对内部移除的节点使用,即该类节点依然要保持原本的后继引用。这是因为该类移除可能在队列的任意位置发生,其首个存在于链接阻塞双端队列的后继节点并不一定位于头部,故而不可采用该方案,这也意味着内部移除存在着引发跨带引用的隐患…但由于内部移除本身在开发中就较少且不推荐使用…并且想要连续的移除还是有一定难度的…因此总体来说并不会有太大影响。















 920
920











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











