









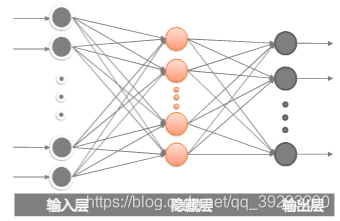
MLP的输入
DBRHD数据集的每张图片是一个由0或1组成的3232的文本矩阵
多层感知机的输入为图片矩阵展开的11024个神经元
MLP输出
一个one-hot向量(除了某一位的数字是1以外其余各维度数字都是0)
图片标签将表示成一个只有在第n维度数字为1的10维向量
比如,标签0将表示成{1,0,0,0,0,0,0,0,0,0}
MLP结构
import numpy as np #导入numpy工具包
from os import listdir #使用listdir模块,用于访问本地文件
from sklearn.neural_network import MLPClassifier
def img2vector(fileName):
retMat = np.zeros([1024],int) #定义返回的矩阵,大小为1*1024
fr = open(fileName) #打开包含32*32大小的数字文件
lines = fr.readlines() #读取文件的所有行
for i in range(32): #遍历文件所有行
for j in range(32): #并将01数字存放在retMat中
retMat[i*32+j] = lines[i][j]
return retMat
def readDataSet(path):
fileList = listdir(path) #获取文件夹下的所有文件
numFiles = len(fileList) #统计需要读取的文件的数目
dataSet = np.zeros([numFiles,1024],int) #用于存放所有的数字文件
hwLabels = np.zeros([numFiles,10]) #用于存放对应的one-hot标签
for i in range(numFiles): #遍历所有的文件
filePath = fileList[i] #获取文件名称/路径
digit = int(filePath.split('_')[0]) #通过文件名获取标签
hwLabels[i][digit] = 1.0 #将对应的one-hot标签置1
dataSet[i] = img2vector(path +'/'+filePath) #读取文件内容
return dataSet,hwLabels
#read dataSet
train_dataSet, train_hwLabels = readDataSet('trainingDigits')
clf = MLPClassifier(hidden_layer_sizes=(100,),
activation='logistic', solver='adam',
learning_rate_init = 0.0001, max_iter=2000)
print(clf)
clf.fit(train_dataSet,train_hwLabels)
#read testing dataSet
dataSet,hwLabels = readDataSet('testDigits')
res = clf.predict(dataSet) #对测试集进行预测
error_num = 0 #统计预测错误的数目
num = len(dataSet) #测试集的数目
for i in range(num): #遍历预测结果
#比较长度为10的数组,返回包含01的数组,0为不同,1为相同
#若预测结果与真实结果相同,则10个数字全为1,否则不全为1
if np.sum(res[i] == hwLabels[i]) < 10:
error_num += 1
print("总样本数:",num," 错误样本数:", \
error_num," 错误率:",error_num / float(num))
输出:
总样本数: 946 错误样本数: 39 错误率: 0.0412262156448203















 3873
3873











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









