






**1.有单线程和多线程:
**
*
1.1 单线程:*
a.每个正在运行的程序(即进程),至少包括一个线程,这个线程叫主 线程
b.主线程在程序启动时被创建,用于执行main函数
c.只有一个主线程的程序,称作单线程程序
d.主线程负责执行程序的所有代码(UI展现以及刷新,网络请求,本地存储等等)。这些代码只能顺序执行,无法并发执行
1.2.多线程:
a. 拥有多个线程的程序,称作多线程程序。
b.iOS允许用户自己开辟新的线程,相对于主线程来讲,这些线程,称为子线程
c.可以根据需要开辟若干子线程
d.子线程和主线程都是独立的运行单元,各自的执行互不影响,因此能够并发执行
2.线程的实现和启动:
2.1.写一个类继承自Thread类,重写run()方法。用start方法启动线程
2.2.写一个类实现Runnable接口,实现run方法。用new Thread(Runnable target).start()方法来启动
*
3.redis用在什么地方:
3.1. 高并发缓存/共享session(单点登录)
3.2…
*
4.redis有什么好处*
4.1.读写性能优异
**
5.redis缓存穿透,雪崩,击穿是什么意思:**
缓存穿透:是指查询一个数据库一定不存在的数据。
雪崩:是指在某一时间段,缓存集中过期失效。
击穿:是指一个key非常热点在不停的大并发,大并发集中在一个热点进行访问,当这个key在失效的瞬间,持续的大并发访问数据库.
*
6.String和StringBuffer,StringBuilder 的区别;
这三个类之间的区别主要是在两个方面,即运行速度和线程安全这两方面。
首先说运行速度,或者说是执行速度,在这方面运行速度快慢为:StringBuilder > StringBuffer > String
String为字符串常量,而StringBuilder和StringBuffer均为字符串变量,即String对象一旦创建之后该对象是不可更改的,但后两者的对象是变量,是可以更改的。
在线程安全上,StringBuilder是线程不安全的,而StringBuffer是线程安全的
总结:
String:适用于少量的字符串操作的情况
StringBuilder:适用于单线程下在字符缓冲区进行大量操作的情况
StringBuffer:适用多线程下在字符缓冲区进行大量操作的情况
*
7.简单说一下spring的ioc和aop
-
*
7.1.spring的常用注解
*:
1、@Controller:用于标注控制器层组件
2、@Service:用于标注业务层组件
3、@Repository:用于标注数据访问组件,即DAO组件
4、@Bean:方法级别的注解,主要用在@Configuration和@Component注解的类里,@Bean注解的方法会产生一个Bean对象,该对象由Spring管理并放到IoC容器中。引用名称是方法名,也可以用@Bean(name = “beanID”)指定组件名
5、@Autowired:默认按类型进行自动装配。在容器查找匹配的Bean,当有且仅有一个匹配的Bean时,Spring将其注入@Autowired标注的变量中。
6、@Resource:默认按名称进行自动装配,当找不到与名称匹配的Bean时会按类型装配。
7.2控制反转(IoC)
控制反转,简单点说,就是创建对象的控制权,被反转到了Spring框架上。
IoC的主要实现方式有:依赖注入。
@Autowired默认按类型进行自动装配(该注解属于Spring),默认情况下要求依赖对象必须存在,如果要允许为null,需设置required属性为false,例:@Autowired(required=false)。如果要使用名称进行装
@Resource默认按照名称进行装配
**
7.3:面向切面编程(AOP)
面向切面编程(AOP)就是纵向的编程。比如业务A和业务B现在需要一个相同的操作,传统方法我们可能需要在A、B中都加入相关操作代码,而应用AOP就可以只写一遍代码,A、B共用这段代码。并且,当A、B需要增加新的操作时,可以在不改动原代码的情况下,灵活添加新的业务逻辑实现。
在实际开发中,比如商品查询、促销查询等业务,都需要记录日志、异常处理等操作,AOP把所有共用代码都剥离出来,单独放置到某个类中进行集中管理,在具体运行时,由容器进行动态织入这些公共代码。
AOP主要一般应用于签名验签、参数校验、日志记录、事务控制、权限控制、性能统计、异常处理等
**
8.模糊查询怎么使用索引
通配符(%)在搜寻词首出现,一般会导致Oracle系统不使用索引。因此,要尽量避免在模糊查询中使用通配符开头,或者是开头结尾都有通配符,这样会导致降低查询速度。例如:
如果开头结尾都要用到通配符,且select获取的字段只有该模糊查询字段,则可以用上索引:
--用到了name字段的一般索引IDX_B$L_INTEREST_INFO_NAME
select name from b$l_interest_info where name like '%瑞德工业园%';
**
9.集合
java集合类存放于 java.util 包中,是一个用来存放对象的容器。
注意:
①、集合只能存放对象。比如你存一个 int 型数据 1放入集合中,其实它是自动转换成 Integer 类后存入的,Java中每一种基本类型都有对应的引用类型。
②、集合存放的是多个对象的引用,对象本身还是放在堆内存中。
③、集合可以存放不同类型,不限数量的数据类型。
①、Iterator:迭代器,它是Java集合的顶层接口(不包括 map 系列的集合,Map接口 是 map 系列集合的顶层接口)
Object next():返回迭代器刚越过的元素的引用,返回值是 Object,需要强制转换成自己需要的类型
boolean hasNext():判断容器内是否还有可供访问的元素
void remove():删除迭代器刚越过的元素
所以除了 map 系列的集合,我们都能通过迭代器来对集合中的元素进行遍历。
注意:我们可以在源码中追溯到集合的顶层接口,比如 Collection 接口,可以看到它继承的是类 Iterable

那这就得说明一下 Iterator 和 Iterable 的区别:
Iterable :存在于 java.lang 包中。
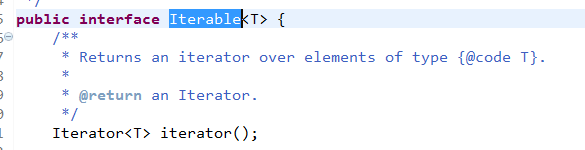
我们可以看到,里面封装了 Iterator 接口。所以只要实现了只要实现了Iterable接口的类,就可以使用Iterator迭代器了。
Iterator :存在于 java.util 包中。核心的方法next(),hasnext(),remove()。
这里我们引用一个Iterator 的实现类 ArrayList 来看一下迭代器的使用:暂时先不管 List 集合是什么,只需要看看迭代器的用法就行了
//产生一个 List 集合,典型实现为 ArrayList。
List list = new ArrayList();
//添加三个元素
list.add("Tom");
list.add("Bob");
list.add("Marry");
//构造 List 的迭代器
Iterator it = list.iterator();
//通过迭代器遍历元素
while(it.hasNext()){
Object obj = it.next();
System.out.println(obj);
}
②、Collection:List 接口和 Set 接口的父接口

看一下 Collection 集合的使用例子:
//我们这里将 ArrayList集合作为 Collection 的实现类
Collection collection = new ArrayList();
//添加元素
collection.add("Tom");
collection.add("Bob");
//删除指定元素
collection.remove("Tom");
//删除所有元素
Collection c = new ArrayList();
c.add("Bob");
collection.removeAll(c);
//检测是否存在某个元素
collection.contains("Tom");
//判断是否为空
collection.isEmpty();
//利用增强for循环遍历集合
for(Object obj : collection){
System.out.println(obj);
}
//利用迭代器 Iterator
Iterator iterator = collection.iterator();
while(iterator.hasNext()){
Object obj = iterator.next();
System.out.println(obj);
}
③、List :有序,可以重复的集合。

由于 List 接口是继承于 Collection 接口,所以基本的方法如上所示。
1、List 接口的三个典型实现:
①、List list1 = new ArrayList();
底层数据结构是数组,查询快,增删慢;线程不安全,效率高
②、List list2 = new Vector();
底层数据结构是数组,查询快,增删慢;线程安全,效率低,几乎已经淘汰了这个集合
③、List list3 = new LinkedList();
底层数据结构是链表,查询慢,增删快;线程不安全,效率高
怎么记呢?我们可以想象:
数组就像身上编了号站成一排的人,要找第10个人很容易,根据人身上的编号很快就能找到。但插入、删除慢,要望某个位置插入或删除一个人时,后面的人身上的编号都要变。当然,加入或删除的人始终末尾的也快。
链表就像手牵着手站成一圈的人,要找第10个人不容易,必须从第一个人一个个数过去。但插入、删除快。插入时只要解开两个人的手,并重新牵上新加进来的人的手就可以。删除一样的道理
④、Set:典型实现 HashSet()是一个无序,不可重复的集合
1、Set hashSet = new HashSet();
①、HashSet:不能保证元素的顺序;不可重复;不是线程安全的;集合元素可以为 NULL;
②、其底层其实是一个数组,存在的意义是加快查询速度。我们知道在一般的数组中,元素在数组中的索引位置是随机的,元素的取值和元素的位置之间不存在确定的关系,因此,在数组中查找特定的值时,需要把查找值和一系列的元素进行比较,此时的查询效率依赖于查找过程中比较的次数。而 HashSet 集合底层数组的索引和值有一个确定的关系:index=hash(value),那么只需要调用这个公式,就能快速的找到元素或者索引。
③、对于 HashSet: 如果两个对象通过 equals() 方法返回 true,这两个对象的 hashCode 值也应该相同。
1、当向HashSet集合中存入一个元素时,HashSet会先调用该对象的hashCode()方法来得到该对象的hashCode值,然后根据hashCode值决定该对象在HashSet中的存储位置
1.1、如果 hashCode 值不同,直接把该元素存储到 hashCode() 指定的位置
1.2、如果 hashCode 值相同,那么会继续判断该元素和集合对象的 equals() 作比较
1.2.1、hashCode 相同,equals 为 true,则视为同一个对象,不保存在 hashSet()中
1.2.2、hashCode 相同,equals 为 false,则存储在之前对象同槽位的链表上,这非常麻烦,我们应该约束这种情况,即保证:如果两个对象通过 equals() 方法返回 true,这两个对象的 hashCode 值也应该相同。
注意:每一个存储到 哈希 表中的对象,都得提供 hashCode() 和 equals() 方法的实现,用来判断是否是同一个对象
对于 HashSet 集合,我们要保证如果两个对象通过 equals() 方法返回 true,这两个对象的 hashCode 值也应该相同。
2、Set linkedHashSet = new LinkedHashSet();
①、不可以重复,有序
因为底层采用 链表 和 哈希表的算法。链表保证元素的添加顺序,哈希表保证元素的唯一性
3、Set treeSet = new TreeSet();
TreeSet:有序;不可重复,底层使用 红黑树算法,擅长于范围查询。
* 如果使用 TreeSet() 无参数的构造器创建一个 TreeSet 对象, 则要求放入其中的元素的类必须实现 Comparable 接口所以, 在其中不能放入 null 元素
* 必须放入同样类的对象.(默认会进行排序) 否则可能会发生类型转换异常.我们可以使用泛型来进行限制
Set treeSet = new TreeSet();
treeSet.add(1); //添加一个 Integer 类型的数据
treeSet.add("a"); //添加一个 String 类型的数据
System.out.println(treeSet); //会报类型转换异常的错误

* 自动排序:添加自定义对象的时候,必须要实现 Comparable 接口,并要覆盖 compareTo(Object obj) 方法来自定义比较规则
如果 this > obj,返回正数 1
如果 this < obj,返回负数 -1
如果 this = obj,返回 0 ,则认为这两个对象相等
* 两个对象通过 Comparable 接口 compareTo(Object obj) 方法的返回值来比较大小, 并进行升序排列
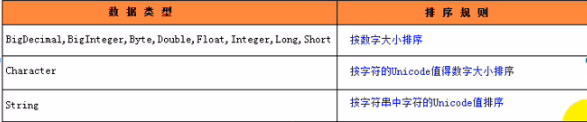
* 定制排序: 创建 TreeSet 对象时, 传入 Comparator 接口的实现类. 要求: Comparator 接口的 compare 方法的返回值和 两个元素的 equals() 方法具有一致的返回值
public class TreeSetTest {
public static void main(String[] args) {
Person p1 = new Person(1);
Person p2 = new Person(2);
Person p3 = new Person(3);
Set<Person> set = new TreeSet<>(new Person());
set.add(p1);
set.add(p2);
set.add(p3);
System.out.println(set); //结果为[1, 2, 3]
}
}
class Person implements Comparator<Person>{
public int age;
public Person(){}
public Person(int age){
this.age = age;
}
@Override
/***
* 根据年龄大小进行排序
*/
public int compare(Person o1, Person o2) {
// TODO Auto-generated method stub
if(o1.age > o2.age){
return 1;
}else if(o1.age < o2.age){
return -1;
}else{
return 0;
}
}
@Override
public String toString() {
// TODO Auto-generated method stub
return ""+this.age;
}
}
- 当需要把一个对象放入 TreeSet 中,重写该对象对应的 equals() 方法时,应保证该方法与 compareTo(Object obj) 方法有一致的结果
以上三个 Set 接口的实现类比较:
共同点:1、都不允许元素重复
2、都不是线程安全的类,解决办法:Set set = Collections.synchronizedSet(set 对象)
不同点:
HashSet:不保证元素的添加顺序,底层采用 哈希表算法,查询效率高。判断两个元素是否相等,equals() 方法返回 true,hashCode() 值相等。即要求存入 HashSet 中的元素要覆盖 equals() 方法和 hashCode()方法
LinkedHashSet:HashSet 的子类,底层采用了 哈希表算法以及 链表算法,既保证了元素的添加顺序,也保证了查询效率。但是整体性能要低于 HashSet
TreeSet:不保证元素的添加顺序,但是会对集合中的元素进行排序。底层采用 红-黑 树算法(树结构比较适合范围查询)
⑤、Map:key-value 的键值对,key 不允许重复,value 可以
1、严格来说 Map 并不是一个集合,而是两个集合之间 的映射关系。
2、这两个集合没每一条数据通过映射关系,我们可以看成是一条数据。即 Entry(key,value)。Map 可以看成是由多个 Entry 组成。
3、因为 Map 集合即没有实现于 Collection 接口,也没有实现 Iterable 接口,所以不能对 Map 集合进行 for-each 遍历。

Map<String,Object> hashMap = new HashMap<>();
//添加元素到 Map 中
hashMap.put("key1", "value1");
hashMap.put("key2", "value2");
hashMap.put("key3", "value3");
hashMap.put("key4", "value4");
hashMap.put("key5", "value5");
//删除 Map 中的元素,通过 key 的值
hashMap.remove("key1");
//通过 get(key) 得到 Map 中的value
Object str1 = hashMap.get("key1");
//可以通过 添加 方法来修改 Map 中的元素
hashMap.put("key2", "修改 key2 的 Value");
//通过 map.values() 方法得到 Map 中的 value 集合
Collection<Object> value = hashMap.values();
for(Object obj : value){
//System.out.println(obj);
}
//通过 map.keySet() 得到 Map 的key 的集合,然后 通过 get(key) 得到 Value
Set<String> set = hashMap.keySet();
for(String str : set){
Object obj = hashMap.get(str);
//System.out.println(str+"="+obj);
}
//通过 Map.entrySet() 得到 Map 的 Entry集合,然后遍历
Set<Map.Entry<String, Object>> entrys = hashMap.entrySet();
for(Map.Entry<String, Object> entry: entrys){
String key = entry.getKey();
Object value2 = entry.getValue();
System.out.println(key+"="+value2);
}
System.out.println(hashMap);
Map 的常用实现类:

⑥、Map 和 Set 集合的关系
1、都有几个类型的集合。HashMap 和 HashSet ,都采 哈希表算法;TreeMap 和 TreeSet 都采用 红-黑树算法;LinkedHashMap 和 LinkedHashSet 都采用 哈希表算法和红-黑树算法。
2、分析 Set 的底层源码,我们可以看到,Set 集合 就是 由 Map 集合的 Key 组成。

***
10.hashmap线程安全类是什么? ***
HashMap不支持线程的同步,是非线程安全的,即任一时刻可以有多个线程同时写HashMap,可能会导致数据的不一致。如果需要同步,可以用 Collections和synchronizedMap方法使HashMap具有同步能力,或者使用ConcurrentHashMap。
HashMap 是一个最常用的Map,它根据键的HashCode值存储数据,根据键可以直接获取它的值,具有很快的访问速度。
遍历时,取得数据的顺序是完全随机的。
HashMap最多只允许一条记录的键为Null;允许多条记录的值为 Null
Hashtable
Hashtable与 HashMap类似,它继承自Dictionary类,不同的是:
它不允许记录的键或者值为空。
它支持线程的同步,即任一时刻只有一个线程能写Hashtable,因此也导致了 Hashtable在写入时会比较慢。
LinkedHashMap
LinkedHashMap 保存了记录的插入顺序,在用Iterator遍历LinkedHashMap时,先得到的记录肯定是先插入的。在遍历的时候会比HashMap慢,不过有种情况例外,当HashMap容量很大,实际数据较少时,遍历起来可能会比LinkedHashMap慢,因为LinkedHashMap的遍历速度只和实际数据有关,和容量无关,而HashMap的遍历速度和容量有关。
TreeMap
TreeMap实现SortMap接口,能够把它保存的记录根据键排序,默认是按键值的升序排序,也可以指定排序的比较器,当用Iterator 遍历TreeMap时,得到的记录是排过序的。
区别:
一般情况下,我们用的最多的是HashMap,HashMap里面存入的键值对在取出的时候是随机的,它根据键的HashCode值存储数据,根据键可以直接获取它的值,具有很快的访问速度。在Map中插入、删除和定位元素,HashMap 是最好的选择。
TreeMap取出来的是排序后的键值对。但如果要按自然顺序或自定义顺序遍历键,那么TreeMap会更好。
LinkedHashMap是HashMap的一个子类,如果需要输出的顺序和输入的相同,那么用LinkedHashMap可以实现,它还可以按读取顺序来排列,像连接池中可以应用。
11.数据结构有哪些?linkedlist和arrylist有什么区别?
ArrayList和LinkedList都实现了List接口,他们有以下的不同点:
ArrayList是基于索引的数据接口,它的底层是数组。它可以以O(1)时间复杂度对元素进行随机访问。与此对应,LinkedList是以元素列表的形式存储它的数据,每一个元素都和它的前一个和后一个元素链接在一起,在这种情况下,查找某个元素的时间复杂度是O(n)。
相对于ArrayList,LinkedList的插入,添加,删除操作速度更快,因为当元素被添加到集合任意位置的时候,不需要像数组那样重新计算大小或者是更新索引。
LinkedList比ArrayList更占内存,因为LinkedList为每一个节点存储了两个引用,一个指向前一个元素,一个指向下一个元素。
也可以参考ArrayList vs. LinkedList。
-
因为 Array 是基于索引 (index) 的数据结构,它使用索引在数组中搜索和读取数据是很快的。 Array 获取数据的时间复杂度是 O(1), 但是要删除数据却是开销很大的,因为这需要重排数组中的所有数据。
-
相对于 ArrayList , LinkedList 插入是更快的。因为 LinkedList 不像 ArrayList 一样,不需要改变数组的大小,也不需要在数组装满的时候要将所有的数据重新装入一个新的数组,这是 ArrayList 最坏的一种情况,时间复杂度是 O(n) ,而 LinkedList 中插入或删除的时间复杂度仅为 O(1) 。 ArrayList 在插入数据时还需要更新索引(除了插入数组的尾部)。
-
类似于插入数据,删除数据时, LinkedList 也优于 ArrayList 。
-
LinkedList 需要更多的内存,因为 ArrayList 的每个索引的位置是实际的数据,而 LinkedList 中的每个节点中存储的是实际的数据和前后节点的位置 ( 一个 LinkedList 实例存储了两个值: Node first 和 Node last 分别表示链表的其实节点和尾节点,每个 Node 实例存储了三个值: E item,Node next,Node pre) 。
什么场景下更适宜使用 LinkedList,而不用ArrayList
-
你的应用不会随机访问数据 。因为如果你需要LinkedList中的第n个元素的时候,你需要从第一个元素顺序数到第n个数据,然后读取数据。
-
你的应用更多的插入和删除元素,更少的读取数据 。因为插入和删除元素不涉及重排数据,所以它要比ArrayList要快。
换句话说,ArrayList的实现用的是数组,LinkedList是基于链表,ArrayList适合查找,LinkedList适合增删
以上就是关于 ArrayList和LinkedList的差别。你需要一个不同步的基于索引的数据访问时,请尽量使用ArrayList。ArrayList很快,也很容易使用。但是要记得要给定一个合适的初始大小,尽可能的减少更改数组的大小。
12.简单说一下hashtable的原理。
第1部分 Hashtable介绍
Hashtable 简介
和HashMap一样,Hashtable 也是一个散列表,它存储的内容是键值对(key-value)映射。
Hashtable 继承于Dictionary,实现了Map、Cloneable、java.io.Serializable接口。
Hashtable 的函数都是同步的,这意味着它是线程安全的。它的key、value都不可以为null。此外,Hashtable中的映射不是有序的。
Hashtable 的实例有两个参数影响其性能:初始容量 和 加载因子。容量 是哈希表中桶 的数量,初始容量 就是哈希表创建时的容量。注意,哈希表的状态为 open:在发生“哈希冲突”的情况下,单个桶会存储多个条目,这些条目必须按顺序搜索。加载因子 是对哈希表在其容量自动增加之前可以达到多满的一个尺度。初始容量和加载因子这两个参数只是对该实现的提示。关于何时以及是否调用 rehash 方法的具体细节则依赖于该实现。
通常,默认加载因子是 0.75, 这是在时间和空间成本上寻求一种折衷。加载因子过高虽然减少了空间开销,但同时也增加了查找某个条目的时间(在大多数 Hashtable 操作中,包括 get 和 put 操作,都反映了这一点)。
Hashtable的构造函数
// 默认构造函数。
public Hashtable()
// 指定“容量大小”的构造函数
public Hashtable(int initialCapacity)
// 指定“容量大小”和“加载因子”的构造函数
public Hashtable(int initialCapacity, float loadFactor)
// 包含“子Map”的构造函数
public Hashtable(Map<? extends K, ? extends V> t)
(01) Hashtable继承于Dictionary类,实现了Map接口。Map是"key-value键值对"接口,Dictionary是声明了操作"键值对"函数接口的抽象类。
(02) Hashtable是通过"拉链法"实现的哈希表。它包括几个重要的成员变量:table, count, threshold, loadFactor, modCount。
table是一个Entry[]数组类型,而Entry实际上就是一个单向链表。哈希表的"key-value键值对"都是存储在Entry数组中的。
count是Hashtable的大小,它是Hashtable保存的键值对的数量。
threshold是Hashtable的阈值,用于判断是否需要调整Hashtable的容量。threshold的值=“容量*加载因子”。
loadFactor就是加载因子。
modCount是用来实现fail-fast机制的















 1444
1444











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









