







# CDA 11 聚类分析(客户画像)
# 导入数据
customer<- read.csv("D:\\桃子的数据\\CDA\\11 聚类分析\\课件&代码-11.客户画像\\Data\\Age_Income3.csv",header=T,sep=',')
names(customer)
customer1<- customer[,c(2,4)]
names(customer1)
#### 11.2---银行客户 k均值/层次聚类----####
names(customer1)
#找到聚类数--pam算法
pamkmd<-pamk(customer1)
pamkmd$nc
layout(matrix(c(1,2),1,2))
plot(pamkmd$pamobject)
# 结果:2类
#找到聚类数--轮廓系数
silhouette()
library(cluster)
result <- list()
for (i in 2:5){
kmd <- kmeans(customer1,centers = i)
sil <- silhouette(kmd$cluster, dist(customer1))
result[[paste('k=',i,sep='')]] <- mean(sil[,'sil_width'])
}
result
# K=2时轮廓系数最高,k=3时候轮廓系数最小,但是从图中看存在离群点,因此用聚类法5类来删掉离群点
#选择聚类5类,去掉离群值的类
#1.正规化后再聚类
library(clusterSim)
customer2<- data.Normalization(customer1,type= "n4")
kmd <- kmeans(customer2,centers = 5)
plot(customer2,col=kmd$cluster)
table(kmd$cluster)
#去掉含有2个异常值的2个类
customer3<- customer1[kmd$cluster!=3&kmd$cluster!=4,]
# #2.正规化后再聚类
# customer4<- data.Normalization(customer3,type= "n4")
# kmd <- kmeans(customer4,centers = 4)
# plot(customer4,col=kmd$cluster)
# table(kmd$cluster)
# #去掉第二类,因为样本有2个异常值
# customer5<- customer3[kmd$cluster!=2,]
#3.正规化后再次寻找最优聚类数
customer6<- data.Normalization(customer3,type= "n4")
write.csv(customer6,file = "D:\\桃子的数据\\CDA\\11 聚类分析\\课件&代码-11.客户画像\\Data\\customer6.csv")
#找到聚类数--pam算法
pamkmd<-pamk(customer6)
pamkmd$nc
layout(matrix(c(1,2),1,2))
plot(pamkmd$pamobject)
#聚类
kmd <- kmeans(customer6,centers = 3)
plot(customer6,col=kmd$cluster)
table(kmd$cluster)
#------ 找到三个类,特征描述------#
plot(customer6,col=kmd$cluster)
points(kmd$centers,col=1:3,pch=8,cex=2)
table(kmd$cluster)
#对原始数据(未正规化但已经去掉异常值的数据)进行解释
write.csv(customer3,file = "D:\\桃子的数据\\CDA\\11 聚类分析\\课件&代码-11.客户画像\\Data\\customer3.csv")
clust <- list()
for (i in 1:3){
clust[[i]]<- customer3[kmd$cluster==i,]
result<- data.frame()
}
for (i in 1:3){
out<-data.frame(cluster=i,Income = mean(clust[[i]]$Income),Age= mean(clust[[i]]$Age))
result<- rbind(result,out)
}
re1<-as.data.frame(result)
# re1$cluster<- factor(re1$cluster,levels = c(1,2,3),labels = c("年老多金", "中年收入不高", "富裕青年"))
#数据每个类的均值
kmd$cluster
#rechart作图
customer4<- cbind(customer3,cluster=kmd$cluster)
customer4$cluster<- factor(customer4$cluster,levels = c(1,2,3),labels = c("年老多金", "中年收入不高", "富裕青年"))
library(recharts)
png("D:\\桃子的数据\\CDA\\cluster.png")
ePoints(customer4[,c(2:4)],xvar =~Income,yvar = ~Age,series = ~cluster,
xlab.name = "Income:千元",ylab.name = "Age:岁",xlab.namePosition = "end",ylab.namePosition = "end",theme = 2)
dev.off()数据预览(前5行))
| CID | Income | Sex | Age | Marriage |
| 1 | 70 | M | 15 | S |
| 2 | 90 | M | 17 | M |
| 3 | 80 | M | 20 | S |
| 4 | 220 | M | 22 | S |
| 5 | 75 | F | 24 | S |
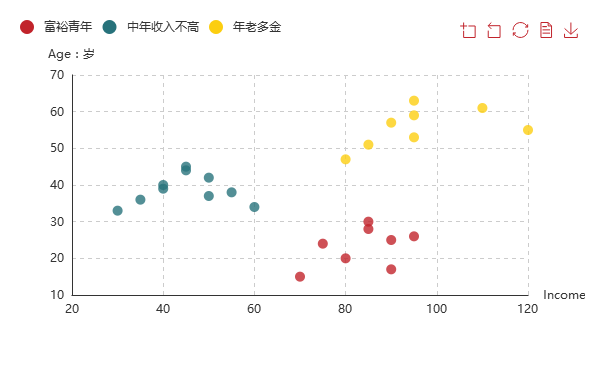
第一类:年老多金型,年龄均值为55岁,收入约9.6万每年,这类人群财富有所积累,但可能思想保守,可推荐保本型投资的理财产品。
第二类:中年收入不高型,年龄均值为38岁,收入约4.5万每年,这类人收入较低,可推荐保险。
第三类:富裕青年型,年龄均值为23岁,收入约8.3万每年,年轻人思想比较开放,具有冒险精神,因此可推荐高获利高风险的投资产品。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









