







Reference
https://www.modb.pro/db/509268
笔记︱几款多模态向量检索引擎:Faiss 、milvus、Proxima、vearch、Jina等 - 知乎 (zhihu.com)
向量数据库入坑指南:聊聊来自元宇宙大厂 Meta 的相似度检索技术 Faiss - 苏洋的文章 - 知乎
向量搜索应用
向量检索技术,其主要的应用领域如人脸识别、推荐系统、图片搜索、视频指纹、语音处理、自然语言处理、文件搜索

背景
向量检索需要用到向量数据库,而普通的关系型数据库(如 MySQL、PostgreSQL)通常不适合处理向量检索任务。这是因为**【向量检索有其特殊的需求和性能要求】**。
原因如下:
1、向量检索的特性
- 高维度数据:向量通常是高维数据,可能有数百到数千个维度。处理高维数据需要特殊的数据结构和算法,以确保检索的效率。
- 相似性度量:向量检索基于相似性度量(如欧氏距离、余弦相似度等)来查找相似向量。计算高维向量之间的相似性需要高效的算法,而普通数据库没有优化这些操作。
- 近似最近邻搜索(ANN):在大规模数据集上,精确最近邻搜索的计算开销非常大,因此通常使用近似最近邻搜索算法(如 LSH、HNSW、IVF 等)来提高检索效率。向量数据库通常内置了这些算法。
2、普通数据库的限制
- 索引结构:普通数据库的索引(如 B 树、哈希索引等)设计用于处理标量数据(如整数、字符串等),而不是高维向量。它们无法有效地支持高维相似性检索。
- 查询优化:普通数据库的查询优化器针对 SQL 查询进行了优化,但对高维向量相似性检索的优化有限,可能导致查询性能低下。
- 扩展性:处理大规模向量数据需要分布式存储和计算能力,普通数据库在这方面的支持不如专门设计的向量数据库。
3、向量数据库的优势
向量数据库(如 FAISS、Milvus、Annoy、Weaviate 等)专门为向量检索设计,具备以下优势:
- 高效的索引结构:支持多种高效的索引结构(如 HNSW、IVF、PQ 等),能够快速处理高维向量的相似性检索。
- 优化的相似性计算:针对高维向量的相似性计算进行了优化,能够在大规模数据集上高效执行最近邻搜索。
- 扩展性和分布式支持:许多向量数据库支持分布式存储和计算,能够处理海量向量数据,并在多个节点之间均衡负载。
4、结论
向量数据库通过专门的索引结构、优化的相似性计算以及分布式支持,显著提高了高维向量相似性检索的效率和扩展性。因此,对于需要处理大规模向量数据的应用场景(如推荐系统、图像搜索、自然语言处理等),使用向量数据库是更好的选择。
索引类型
| 索引类型 | 原理 | 特点 | 适用场景 | 优点 | 缺点 |
|---|---|---|---|---|---|
| FLAT | 线性扫描: 直接对所有向量进行线性扫描,计算每个向量与查询向量之间的距离。 | 精确度高,速度较慢。 | 小规模数据集或对精度要求非常高的场景。 | 精度高,因为计算了每个可能的距离。 | 对于大数据集,速度非常慢。 |
| IVF | 簇划分: 将向量数据集分为多个簇(clusters),然后在这些簇内搜索。 【Inverted File Index】 |
通过缩小搜索范围加速查询。搜索分两步:先找到最相关的簇,再在簇内搜索。 | 中大规模数据集,平衡速度和精度。 | 加速搜索速度,平衡速度和精度。 | 精度稍低于 FLAT。 |
| PQ | 子空间划分: 将向量分成多个子空间 量化: 每个子空间独立量化,减少存储和计算复杂度。 【Product Quantization】 |
存储效率高,查询速度快。精度有损,但通常可接受。 | 大规模数据集,对存储和查询速度要求高的场景。 | 存储效率高,查询速度快。 | 量化带来精度损失。 |
| HNSW | 多层图结构: 构建一个包含多个层次的小世界图 导航搜索: 从高层次开始,逐层向下搜索,直到找到最近邻。 【Hierarchical Navigable Small World】 |
高查询效率和精度,支持动态更新。 | 高效查询,动态更新的大规模数据集。 | 高效的查询速度和高精度。 | 构建和维护图结构复杂,内存消耗较大。 |
| LSH | 哈希映射: 将相似的向量映射到相同的哈希桶。 【Locality-Sensitive Hashing】 |
适用于高维数据,但精度相对较低。 | 高维数据的近似最近邻搜索。 | 适用于高维数据,查询速度快。 | 精度相对较低。 |
| ANNOY | 随机投影树: 构建多棵树,每棵树基于不同的随机投影。 【Approximate Nearest Neighbors Oh Yeah】 |
平衡了搜索速度和精度。 | 大规模数据集。 | 平衡速度和精度。 | 构建时间较长。 |
| IVF-PQ | 簇划分和量化: 结合 IVF 和 PQ,将向量数据集分为多个簇,并在每个簇内进行量化。 【Inverted File with Product Quantization】 |
进一步优化存储和查询效率。 | 大规模数据集,需要存储和查询效率优化的场景。 | 存储和查询效率进一步优化。 | 构建和维护较复杂。 |
| ScaNN | 结合量化和排序: 结合矢量量化和距离排序等技术。 【Scalable Nearest Neighbors】 |
在处理大规模数据集时表现出色。 | 大规模数据集。 | 在大规模数据集上表现出色。 | 算法复杂度较高。 |
——from ChatGPT
相似度指标
- Euclidean distance (L2): This metric is generally used in the field of computer vision (CV).
- Inner product (IP): This metric is generally used in the field of natural language processing (NLP). The metrics that are widely used for binary embeddings include:
- Hamming: This metric is generally used in the field of natural language processing (NLP).
- Jaccard: This metric is generally used in the field of molecular similarity search.
- Tanimoto: This metric is generally used in the field of molecular similarity search.
- Superstructure: This metric is generally used to search for similar superstructure of a molecule.
- Substructure: This metric is generally used to search for similar substructure of a molecule.
向量数据库
以下是主流向量数据库的对比:
| 数据库 | 发布者 | 时间 | 功能 | 优点 | 缺点 |
|---|---|---|---|---|---|
| Milvus | Zilliz (阿里巴巴孵化) | 2019 | 多模态检索,分布式架构,数据持久化,查询优化 | 高性能,多模态支持,易用性强 | 部分功能依赖商业支持 |
| FAISS | Facebook AI Research | 2017 | 多种索引类型,内存高效利用,GPU 加速 | 高性能(尤其在 GPU 环境),灵活性强,社区支持丰富 | 持久化和分布式支持较弱,使用门槛较高 |
| Annoy | Spotify | 2014 | 随机投影树,读多写少,支持磁盘持久化 | 简单易用,支持磁盘持久化 | 写操作不高效,扩展性有限 |
| NMSLIB | 非官方开源项目 | 2013 | 多种近似最近邻算法,高性能,多语言绑定 | 性能优秀,灵活性强 | 文档和社区支持较少,缺乏商业支持 |
| Weaviate | SeMI Technologies | 2019 | 分布式搜索,知识图谱,RESTful API 和 GraphQL 支持 | 上下文感知,结合知识图谱提供智能搜索,支持分布式和大规模数据 | 部分功能依赖外部服务和插件,社区生态较新 |
| Pinecone | Pinecone.io | 2020 | 商业化托管服务,多种索引,自动扩展,实时更新 | 全托管服务,高可靠性,良好文档和客户支持 | 使用成本高,部分功能需要付费订阅 |
| Qdrant | Qdrant | 2021 | 高性能搜索,实时更新,分布式架构,数据持久化 | 高性能,实时更新,易用性强,支持分布式和持久化 | 分布式功能较新,社区生态正在发展 |
—— ChatGPT
Milvus 是一个功能强大、支持多模态和分布式架构的向量数据库,适用于需要处理大规模、多样化数据的场景。
FAISS 则以其高性能和灵活性著称,特别适合需要高效向量检索和 GPU 加速的场景。选择合适的向量数据库需要根据具体的应用需求、数据规模和性能要求来决定。
| 向量数据库 | GitHub Star 数量 | GitHub Fork 数量 | 社区活跃度 | 使用情况及活跃度 |
|---|---|---|---|---|
| Milvus | 14k+ | 2k+ | 高 | 使用情况:广泛应用于多模态检索、推荐系统等领域。 社区活跃度:活跃,有定期更新和活跃的社区支持。 |
| FAISS | 22k+ | 4k+ | 高 | 使用情况:被广泛用于研究和工业界的高性能向量检索任务,尤其在 GPU 环境下。 社区活跃度:非常活跃,有广泛的文档和社区支持。 |
| Annoy | 11k+ | 1k+ | 中 | 使用情况:常用于推荐系统和音乐检索,尤其适合读多写少的场景。 社区活跃度:活跃,维护较好,但更新频率相对较低。 |
| NMSLIB | 3k+ | 800+ | 中 | 使用情况:用于各种高性能向量检索任务,支持多种算法。 社区活跃度:活跃,有一定的用户基础和贡献者,但相对较小。 |
| Weaviate | 2k+ | 300+ | 中 | 使用情况:适用于知识图谱和上下文感知的检索场景。 社区活跃度:活跃,但由于是相对较新的项目,用户基础和生态正在发展中。 |
| Pinecone | 无公开仓库 | 无公开仓库 | 高(商业服务) | 使用情况:被多家企业用于生产环境中的向量检索任务。 社区活跃度:高,通过商业支持和客户服务提供持续的更新和支持。 |
Milvus
【向量数据库】
【支持高效的向量检索】Milvus 采用了高效的算法和数据结构,如倒排索引、HNSW、量化等,优化搜索性能和存储效率,适合于机器学习、人工智能和相似性搜索的应用场景。
【高度可扩展】Milvus 支持容器化部署(如 Kubernetes)
【易用性和灵活性】【强大的社区支持】
官方Doc
https://milvus.io/docs/v2.2.x
背景
Milvus 是由 Zilliz 开发并开源的高性能分布式向量数据库,最初是由阿里巴巴孵化,旨在处理大规模、多模态的向量检索任务。Milvus 是 LF AI & Data 基金会的托管项目之一。
功能
- 多模态向量检索:支持文本、图像、视频、音频等多种数据类型的向量检索。
- 多种索引类型:支持 IVF(Inverted File)、HNSW(Hierarchical Navigable Small World)、ANNOY、PQ(Product Quantization)等。
- 分布式架构:支持横向扩展,能够处理海量数据并提供高并发性能。
- 数据持久化:支持数据持久化和动态加载,确保数据的持久性和可恢复性。(Milvus 使用 RocksDB 作为持久化存储)
- 高级查询:支持复杂查询,如布尔查询、批量查询等。
- 图形化界面:提供 Milvus Insight 图形化管理界面,方便用户管理和监控集群。
- API 支持:提供丰富的 API,包括 RESTful API、Python SDK、Java SDK 等。
【多模态向量检索支持】
- 特征提取:结合预训练模型进行特征提取,将多模态数据(文本、图像、视频等)转化为向量表示。
- 统一接口:所有模态的数据在 Milvus 中统一表示为向量,用户可以通过统一接口进行检索操作。
【分布式架构】
- 集群架构:包括 Coordinator、Proxy、Data Node、Query Node、Index Node 等组件,支持横向扩展和高并发。
- 数据分片和分区:支持数据水平切分(Sharding)和逻辑分区(Partitioning),便于管理和检索。
- 索引管理:支持多种索引类型的分布式构建和维护,提高大规模数据的检索性能。
- 负载均衡和故障恢复:使用负载均衡机制和故障恢复机制,保证系统的高可用性。
- 数据持久化:支持数据持久化和恢复,确保数据在节点故障或重启时不会丢失。
架构
Milvus 的架构主要由以下几个组件组成:
- Coordinator:负责集群管理、元数据管理和任务调度。
- Proxy:处理客户端请求,负责数据路由和负载均衡。
- Data Node:负责数据存储和管理,包括数据持久化和索引构建。
- Query Node:处理查询请求,执行向量检索和结果返回。
- Index Node:负责索引构建和维护,提高查询效率。
- Meta Store:存储元数据,如数据表结构、索引信息等。
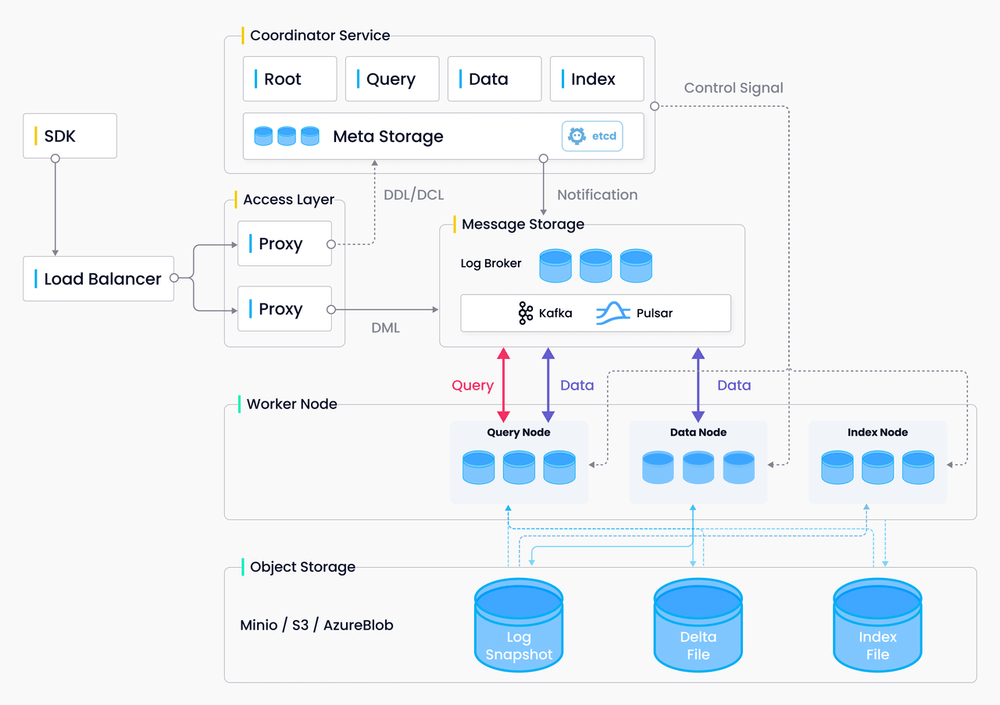
【节点】
query node 负责查询,data node 负责数据写入和持久化、index node负责索引建立和加速查询
the query node is in charge of data query; the data node is responsible for data insertion and data persistence; and the index node mainly deals with index building and query acceleration.
设计原则
The design principles of Milvus 2.0
数据流程
【logs --> log snapshot --> segment】
Both the table and the log are data, In the case of Milvus, it aggregates logs using a processing window from TimeTick. Based on log sequence, multiple logs are aggregated into one small file called log snapshot. Then these log snapshots are combined to form a segment, which can be used individually for load balance.
第三方依赖:MinIO, etcd, and Pulsar.
Milvus cluster includes eight microservice components and three third-party dependencies: MinIO, etcd, and Pulsar.
Storage层有三个部分组成:
Meta store、Log broker、Object storage
数据处理过程
Reference
**数据写入和数据持久化:**https://milvus.io/blog/deep-dive-4-data-insertion-and-data-persistence.md
加载数据到内存(实时查询):https://milvus.io/blog/deep-dive-5-real-time-query.md#Load-data-to-query-node
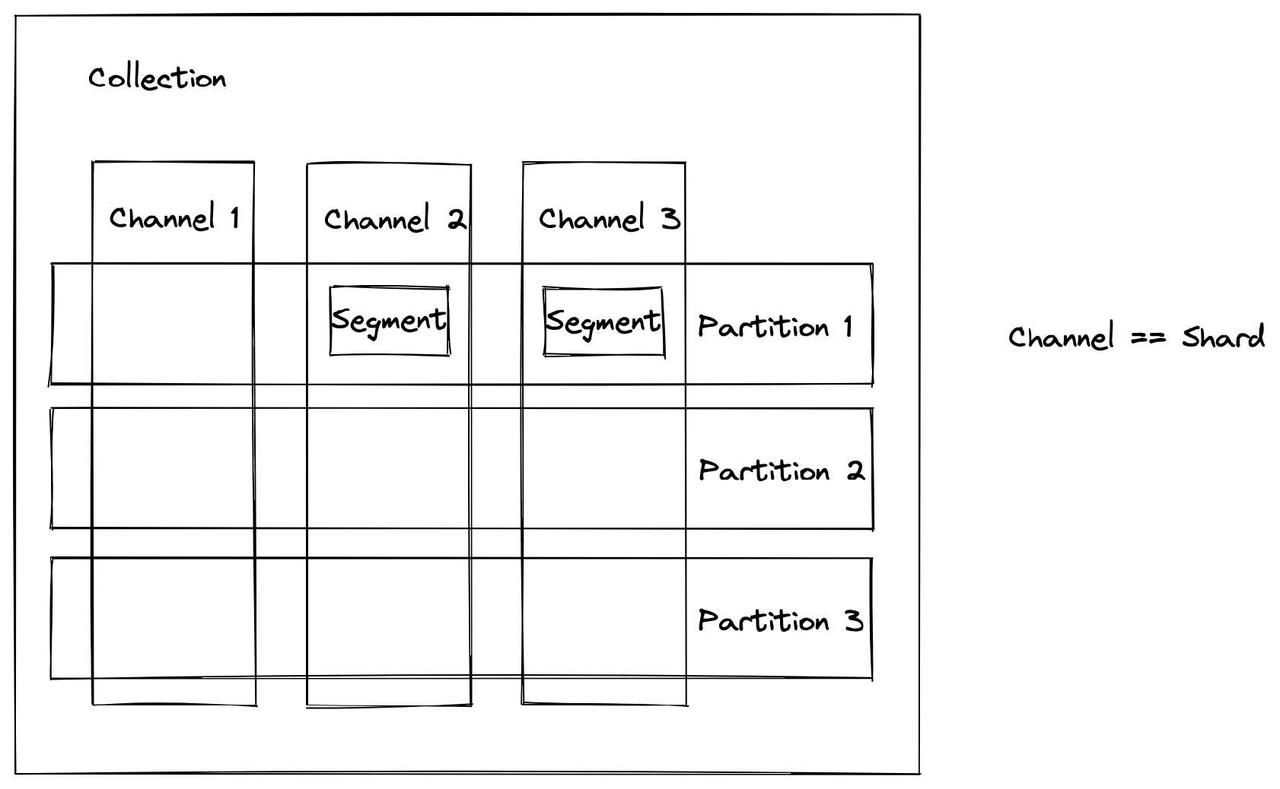
1、数据写入:可以为每个 collection 设置分片数量(每个分片对应一个虚拟通道 vchannel),数据将根据主键的哈希值写入相应的分片。
You can specify a number of shards for each collection in Milvus, each shard corresponding to a virtual channel (vchannel). Any incoming insert/delete request is routed to shards based on the hash value of primary key.
当segment满了,会自动出发data flush (512 MB by default)
- **【segment】**Milvus中用于数据存储的最小单元。
- indexes are built on segments.
- Automatically flush segment data If the segment is full, the data coord automatically triggers data flush.
三种类型的segment
- There are three types of segments with different status in Milvus: growing, sealed, and flushed segment.
- growing:可以插入数据
- sealed:不再插入数据 A sealed segment is a closed segment
- flushed :已经被写入磁盘 A flushed segment is a segment that has already been written into disk. A segment can only be flushed when the allocated space in a sealed segment expires.
2、索引建立:index node 从segmeng中将数据加载到内存,建立索引后再写回 object storage
The index node loads the log snapshots to index from a segment (which is in object storage) to memory , deserializes the corresponding data and metadata to build index, serializes the index when index building completes, and writes it back to object storage.
向量检索维度太高,传统基于树的索引不再适应,取而代之的有基于聚类和基于图的索引。
Vectors cannot be efficiently indexed with traditional tree-based indexes due to their high-dimensional nature, but can be indexed with techniques that are more mature in this subject, such as cluster- or graph-based indexes.
3、查询:query node在加载到内存的segment中执行查询
A collection in Milvus is split into multiple segments, and the query nodes loads indexes by segment.
每个query 节点只负责两个任务:按照 query coord 的指令加载或释放段;在本地段中进行搜索。
Each node is responsible only for two tasks: Load or release segments following the instructions from query coord; conduct a search within the local segments.
有两种类型的segment: growing segments 和sealed segments
There are two types of segments, growing segments (for incremental data), and sealed segments (for historical data). Query nodes subscribe to vchannel to receive recent updates (incremental data) as growing segments.
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 811
811

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









