








目录
目标:我要提取 发件人(From)、收件人(To)、邮件主题(Subject)、邮件正文(zhengwen) 作为邮件特征,然后输入到线性分类模型中进行训练
~~~~~~~~~~~待更新~~~~~~~~~~~~~~~~~~~~~~~~~~~
数据集是这样的
data里是数据文件
full里是index文件,存放哪个路径的文件是什么类型
index文件 (类型--文件路径 对照表)
目标:我要提取 发件人(From)、收件人(To)、邮件主题(Subject)、邮件正文(zhengwen) 作为邮件特征,然后输入到线性分类模型中进行训练
首先是这四个特征提取的部分
发件人
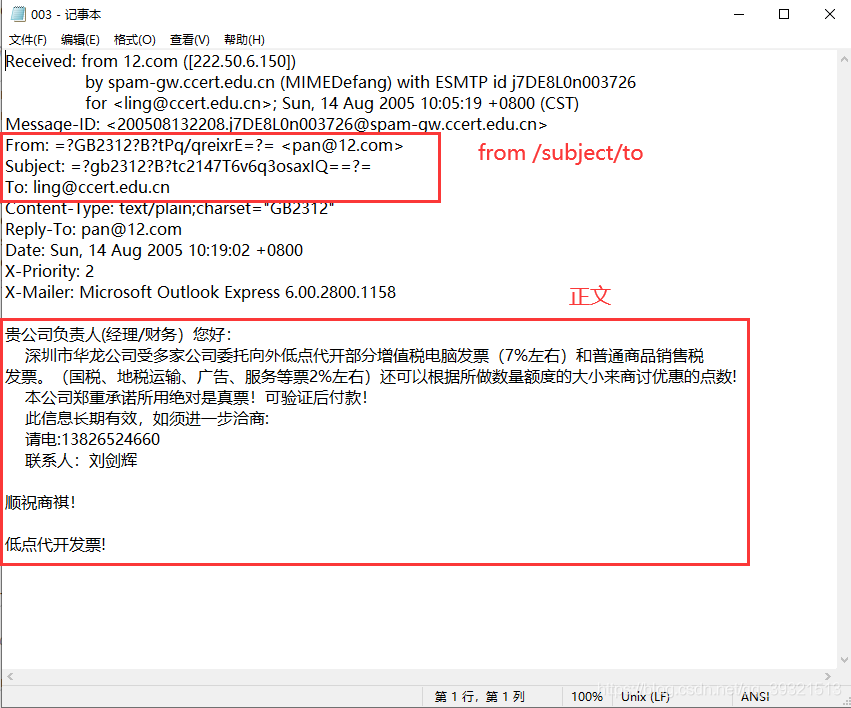
通过上面的邮件的图,可以看到From、Subject中有用gb2312和base64编码的部分,需要进行解码
另外 如果多打开几个文件可以观察到 From字段的情况比较复杂,我观察到了这四种(列在下面),其实可能不止这四种格式
From: wei@13.com
From: "yan"<(8月27-28,上海)培训课程>
From: ke@163.com" <chunyang-sz@163.com>
From: =?GB2312?B?zuLmw+bD?= <hou@163.com>
我做的处理步骤大体如下:
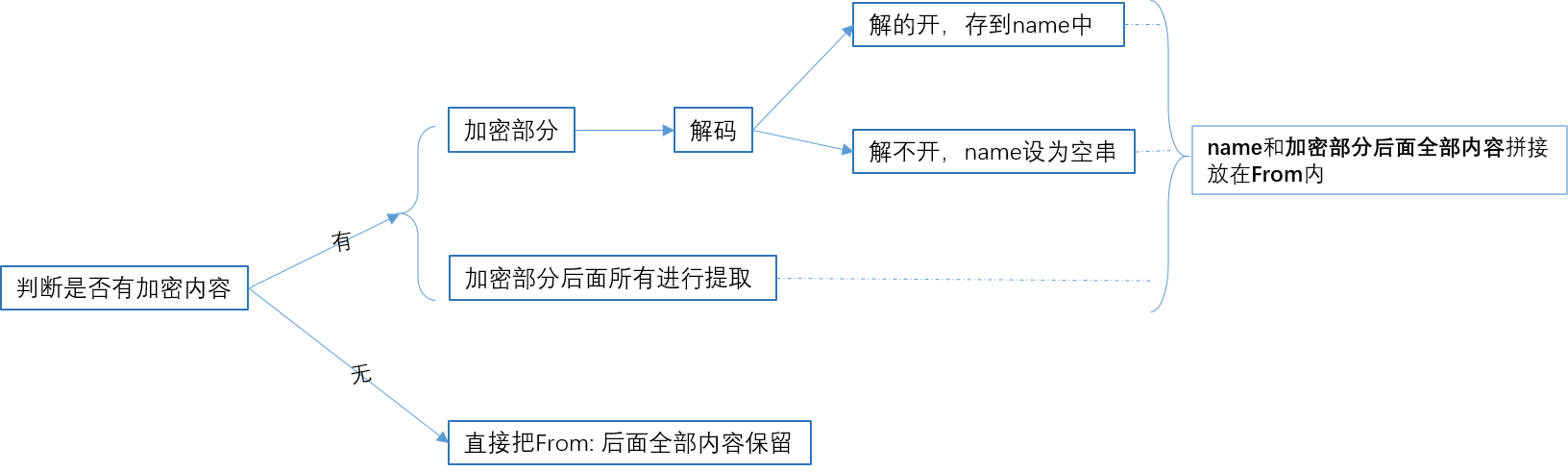
解码部分优先用gb2312解 ,如果报异常 就在用gbk解,如果还是报异常,就直接赋空串
def From_email(email): # email是整封邮件的内容字符串
# 发件人
# 先提取From后的所有内容
try:
From_raw = re.search(r'From: (.*)', email).group(1)
except:
From_raw = ''
From = ''
# 先看看有没有加密部分 有加密部分就给他解密
name = re.search(r'=\?GB2312\?B\?(.*)\?=', From_raw, re.I) # name保存加密部分
if name is None: # 没有加密部分
name = ''
# 没有加密部分 就保留串的所有内容
From = From_raw
else: # 有加密部分
name = name.group(1)
try:
name = base64.b64decode(name).decode('gb2312')
except:
try:
name = base64.b64decode(name).decode('gbk')
except:
name = ''
From = name + re.search(r'\?=(.*)', From_raw).group(1)
# print('From: ', From)
return From收件人
存在以TO: 开头的情况,加个re.I 就不区分大小写了
def To_email(email):
# 收件人
To = re.search(r'^To: (.*)', email, re.M | re.I).group(1) # re.M 从每行文本开头的位置开始匹配
# print('To: ', To)
return To邮件主题
处理这个字段的流程基本和From字段一样,Subject的格式比较统一,基本都是加密形式
def Subject_email(email):
# 主题
Subject = re.search(r'=\?gb2312\?B\?(.*)\?=', email)
if Subject is None:
Subject = ''
else: # subject 有内容
Subject = Subject.group(1)
Subject = base64.b64decode(Subject) # 解密
try:
Subject = Subject.decode('gb2312') # 解码
except:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 9894
9894

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









