







如果直接取groupby后的数据会得到一个地址,类似于这样<pandas.core.groupby.groupby.DataFrameGroupBy object at 0x000001F35C0BAB00>,看不到里面的数据
完整展示
# 统计每个班级的实验课课表
data.groupby('班级').apply(lambda x:x)
输出结果是

每组输出前几行看结果
data.groupby('班级').head(2)
输出结果是
看起来更方便一点
data.groupby('班级').apply(lambda x:x[:])
输出结果是这样的

如果原始的那列不想要了,看着更方便点的话
data.groupby('班级').apply(lambda x:x[:]).drop(axis=1, columns='班级', inplace=False)
输出结果

groupby后的结果还可以用for循环提取(当然这种麻烦一些)
直接上代码说明
import numpy as np
import pandas as pd
#定义一个数据框
df = pd.DataFrame({
'user_id': [1, 2, 3, 4, 1, 2, 3],
'class_type': ['Krav Maga', 'Yoga', 'Ju-jitsu', 'Krav Maga',
'Ju-jitsu','Krav Maga', 'Karate'],
'instructor': ['Bob', 'Alice','Bob', 'Alice','Alice', 'Alice','Bob']})
df长这样:
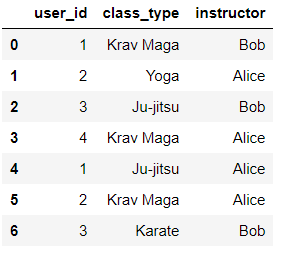
groupOj = df.groupby('user_id')
for key, value in groupOj:
print(key)
print(value)
输出结果:

所以哪里是键(key)?哪里是值(value)呢?
然后就尝试了一下
groupOj = df.groupby('user_id')
for key, value in groupOj:
print('###########################')
print(key)
print('###########################')
print(value)
发现

然后我还看了一下key和value的类型
value是一个DataFrame

欢迎 : 转发 + 评论 + 点赞~
转发请注明出处~
谢谢您的支持!!~















 1934
1934











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









