







专栏介绍:本栏目为 “2021秋季中国科学院大学周晓飞老师的机器学习” 课程记录,不仅仅是课程笔记噢~ 如果感兴趣的话,就和我一起入门Machine Learning吧🥰
这一小节内容刚好NLP课上也讲过,所以结合机器学习和NLP两位老师的课件进行整理。前向算法是NLP老师强调过会考计算题的内容。
定义
频率派发展为统计机器学习,贝叶斯派发展为概率图模型,它围绕着怎么求后验概率展开讨论。

- 在上一篇博文中我们有介绍到概率图分为有向贝叶斯模型和无向马尔科夫随机场。当概率模型增加了time之后有了动态模型,Xi之间不是独立同分布的,具体有三种,
- HMM:隐变量取值离散
- Kalman Filter:隐变量是线性连续的
- Particle Filter:隐变量是非线性连续的
- 隐马尔可夫模型HMM是关于时序的概率模型,是最简单的动态贝叶斯网络模型,它的本质是通过可见的事物的变化揭示深藏其后的内在的本质规律。
模型参数
隐马尔可夫模型由 A,B,π 唯一确定,A,B,π 称为隐马尔可夫模型的三要素。下面我们来举例说明:

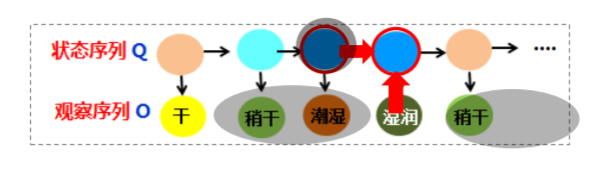
前文说到隐马尔可夫研究两件事情变化规律互相影响的问题,在这个例子中,天气的变化会影响海藻的状态(天气晴朗时海藻变得干燥)。
- 状态序列Q:表示起决定的后台本质(晴天,雨天…)
- 观察序列O:表示观察到的前台表象(潮湿,干燥…)
- π :表示初始状态,也就是状态序列的起始值
- 转移矩阵A:描述前后时刻状态变化的概率。比如,当前时刻是雨,下一个时刻是云的概率是0.3,当前时刻是云,下一个时刻是晴的概率是0.8
- 观测概率矩阵B:描述同一时刻从某一状态推出某一个表象的概率。比如,当前晴推出海藻干燥的概率是0.6,阴天推出海藻干燥的概率是0.25。
上述五元组构成了HMM的基本结构
两个假设
- 观测变量仅依赖于当前时刻的状态变量。(绿色箭头)
- 当前状态仅依赖于前一时刻的状态。(红色箭头)

三个问题
隐马尔可夫模型有三个研究重点:
1️⃣概率计算问题/评估问题
对于给定观察序列 O=O1,O2,…OT, 以及模型λ(A,B,π),求观察序列的概率P(O|λ)。比如说:模型的转移矩阵,观测矩阵以及初始状态给出,请求出海藻(从干->稍干->潮湿)这一观察序列出现的概率。

那么如何求解这个P(O|λ)呢?首先将它展开为所有所有状态序列和观测序列的联合分布之和:

继续考虑如何求解:P(O,Q |λ) ,可以将它理解为给定模型,状态序列为Q,观测序列为O的概率:

π是初始状态,a和b分别是上文提到的转移矩阵和观测矩阵中的概率,将a和b整理到一起得到:

其实刚好对应横向的概率与纵向的概率

整理得到了这个公式之后,推广到所有的状态序列,就能整理出一个概率公式了:

可以看到,我们需要对状态序列做累加的操作,但是状态序列随着状态数目的增加,它将会有很多选择,那么我们如何才能将这个累加结果计算出来呢?一共有三种方法
1. 穷举法:
找到每一个可能的隐藏状态的序列,这里有 27种,可观察序列的概率就是这27种可能的和。 很显然,这种计算的效率非常低,尤其是当模型中的状态非常多或者序列很长的时候。所以下文只重点介绍后两个方法:
- 前向算法(后向算法):利用动态规划使用递归来降低计算复杂度
2. 🌷前向算法

看到上面这些公式可能会有一点晦涩,但是其实计算过程就是:向下一步,向右一步 还是按照上面的例子,做一个例题就明白了。

3. 后向算法
后向算法和前向算法思想是一致的,只是从后往前算,需要注意一下几点:
- 初始化是把i时刻设置为1
- 计算结束之后要再乘初始状态以及观测概率

下图是某个例题的中间步骤:

可以参考期末练习题加深理解:https://blog.csdn.net/qq_39328436/article/details/122161663
2️⃣预测问题/解码问题
对于给定观察序列 O=O1,O2,…OT, 以及模型 如何选择一个对应的状态序列 S = S1,S2,…ST,使得S能够最为合理的解释观察序列O。由观测序列求状态序列。

穷举法
找到每一个可能产生观察序列的状态序列,这里有 27种,计算每种可能情况下观察序列的概率,概率最大的状态序列就是要找的状态序列。 很显然,这种计算的效率非常低,尤其是当模型中的状态非常多或者序列很长的时候。
🌼维特比算法
Viterbi 搜索算法:利用动态规划使用递归来降低计算复杂度

- 如果概率最大路径(或说最短路径)经 i 时刻某个点,一定可以找到S到该点的最短路径(可将i时刻点的最短路径记录)
- 从S到E 的路径必定经过 i时刻的某个点
- 当从状态 i 进入到i+1状态时计算S到i+1 状态时,只考虑 i状态所有节点最短路径和和它们到 i+1状态的距离即可。
维特比算法与前向算法的区别是:将求和操作变为了求max操作,并且用后向指针记录每次选择的最大前向概率。
如果多个前向概率相同,意味着回溯路径时可能有多条路径。

- 第一列最大的是0.6,对应的状态为晴
- 第二列最大的是0.053,对应的状态为雨
- 第三列最大的是0.0166,对应的状态为雨
(晴,雨,雨)就是最可能的天气序列。
3️⃣学习问题
学习问题指的是如何训练隐马尔可夫模型的参数~(略)
隐马尔可夫模型的问题
存在的问题:
- 由于生成模型定义的是联合概率,必须列举所有观察序列的可能值,这对多数领域来说是比较困难的。
- 但是,在自然语言处理中,常知道各种各样但又不完全确定的信息,需要一个统一的模型将这些信息综合起来。
- 输出独立性假设要求序列数据严格相互独立才能保证推导的正确性,导致其不能考虑上下文特征。
- 但是,在自然语言处理中,常常需要考虑上下文关系。
最大熵模型
最大熵模型用来解决HMM不考虑上下文信息的问题

最大熵模型:
- 将多种不同的信息(输入)整合到一个分类(输出)模型
- 可以综合多个不完全信息
- 这些信息可以灵活表示

但是最大熵模型还是会存在一个问题:输出之间独立(输出元素之间没有关系)
🌻条件随机场
CRF是条件随机场,在网上很多关于它的公式详解,所以这一小节只讲一个问题:在序列标注问题中,Bi-LSTM+softmax的模型存在什么问题?为什么需要在这个问题中引入条件随机场?
如果不使用条件随机场,经过softmax之后,会挑选一个概率最大的标签输出,第一列最大的是0.14,那么对应“中”的标签就应该是B-Location(B代表Begin),代表地名的开始;第二列概率中最大的是0.31,其对应的标签仍然为B-Location,很显然,两个挨着的字是不可能都为地名的开始,那么要如何解决问题这个问题呢 这就是条件随机场的工作了

之所以会出现连续的两个B,是因为输出之间没有限制条件,应该告诉模型,如果前一个字是Begin,后一个字的标签就不能是Begin。那么 CRF是如何完成这样的限制的呢? 它是通过一个转移矩阵规定输出序列的概率做到的。

在这个矩阵中,第一行第一列代表前一个字是B-Location,后一个字是B-Location的概率,根据上文的描述,这个概率应该非常小,甚至是0。那么加入了CRF之后的模型结构就应该是下图所示:

以上边解释了为什么条件随机场可以用来进一步解决最大熵模型输出之间独立的问题
- 条件随机场CRF: 输入是特征集合的序列,输出是标签序列。
- 从下图中可以看到,y1,y2,y3之间有虚线连接,代表着输出之间不再是独立的(可以将条条件随机场理解画输出之间的虚线)。

应用
词性标注
- 观察序列O=O1O2…OT: 处理的语言单位,一般为 词
- 状态序列S=S1S2…ST : 与语言单位对应的句法信息,一般为 词类
- 模型参数:初始状态概率、状态转移概率、发射概率 需要学习获得

中文分词
-
观察序列O=O1O2…OT: 北京是种国的首都
-
状态序列S=S1S2…ST : B I E O
-
模型参数:初始状态概率、状态转移概率、发射概率 需要学习获得

-
注意: 分词和词性标注虽均用HMM模型, 但 状态集观察集 不同,训练语料标注不同,模型参数不同
命名实体识别
在NLP一次实验中实现了用CRF进行中文命名实体识别
NLP作业三:用BiLSTM+CRF实现中文命名实体识别(TensorFlow入门)【代码+报告】
完结撒花🌼🌷🌼🌻
本节对应的期末习题可以参见:【一起入门MachineLearning】中科院机器学习-期末题库-【计算题3+计算题4】

















 1424
1424











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











