









文章目录
背景
使用 word 文档时,word 如何判断某个单词是否拼写正确?
网络爬虫程序,怎么让它不去爬相同的 url 页面?
垃圾邮件过滤算法如何设计?
公安办案时,如何判断某嫌疑人是否在网逃名单中?
缓存穿透问题如何解决?
上述问题是的实质归根结底就是判断在海量的数据中查找某一条数据是否存在。
平衡二叉树
增删改查时间复杂度为 log 2^n
log 2^n平衡的目的是增删改后,保证下次搜索能稳定排除一半的数据;
的直观理解:100万个节点,最多比较 20 次;10亿个节点,最多比较 30 次;
总结:通过比较保证有序,通过每次排除一半的元素达到快速索引的目的
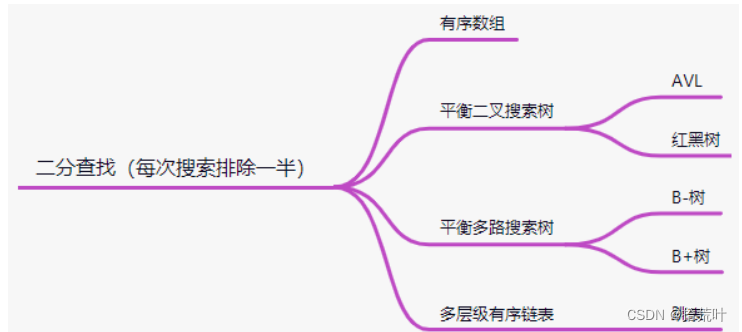
上表中的数据结构都可以做到查找数据的时间复杂度是log2^n;
散列表(hash表)
根据 key 计算 key 在表中的位置的数据结构;是 key 和其所在存储地址的映射关系;
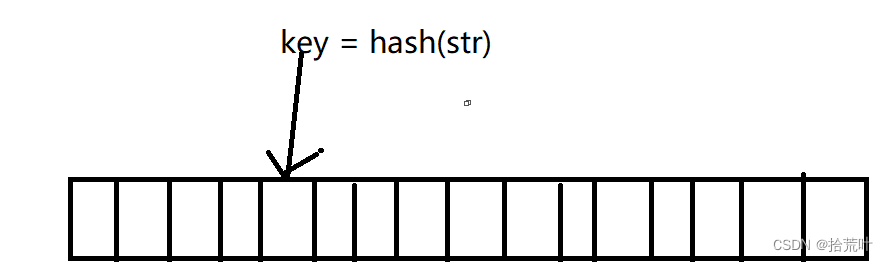
映射函数 Hash(key)=addr ;hash 函数可能会把两个或两个以上的不同 key 映射到同一地址,这
种情况称之为冲突(或者 hash 碰撞);
计算速度快
强随机分布(等概率、均匀地分布在整个地址空间)
当没有hash冲突是,查找的时间复杂度为O(1)
hash冲突的解决办法
链表法:
引用链表来处理哈希冲突;也就是将冲突元素用链表链接起来;这也是常用的处理冲突的⽅式;但是可能出现一种极端情况,冲突元素比较多,该冲突链表过长,这个时候可以将这个链表转换为红黑树;由原来链表时间复杂度 转换为红黑树时间复杂度 ;那么判断该链表过长的依据是多少?可以采⽤超过 256(经验值)个节点的时候将链表结构转换为红黑树结构;
开放寻址法:
将所有的元素都存放在哈希表的数组中,不使用额外的数据结构;一般使用线性探查的思路
解决;
- 当插入新元素的时,使用哈希函数在哈希表中定位元素位置;
- 检查数组中该槽位索引是否存在元素。如果该槽位为空,则插⼊,否则3;
- 在 2 检测的槽位索引上加一定步长接着检查2; 加⼀定步长分为以下几种:
- i+1,i+2,i+3,i+4, … ,i+n
- i- 1^2, i+2 ^2 ,i- 3 ^2 ,i+4 ^2 , 这两种都会导致同类 hash 聚集;也就是近似值它的hash值也近似,那么它的数组槽位也靠近,形成 hash 聚集;第一种同类聚集冲突在前,第二种只是将聚集冲突延后; 另外还可以使用双重哈希来解决上面出现hash聚集现象
布隆过滤器
背景
布隆过滤器是一种概率型数据结构,它的特点是高效地插入和查询,能确定某个字符串一定不存在或者可能存在;布隆过滤器不存储具体数据,所以占用空间小,查询结果存在误差,但是误差可控,同时不支持删除操作;并且在应用布隆过滤器的场景下是允许误差存在的。
构成
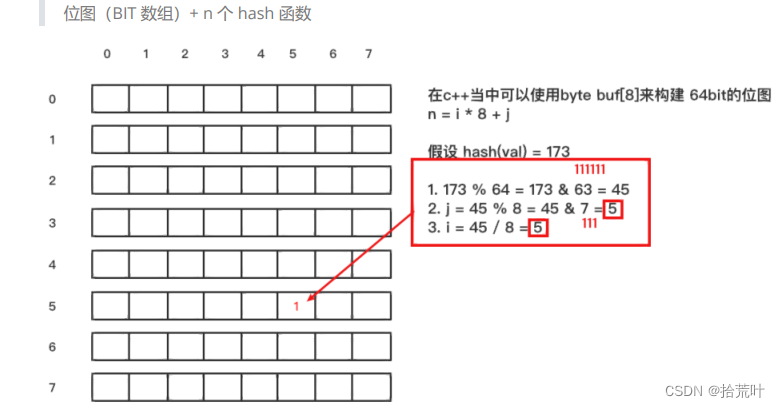
原理
当一个元素加入位图时,通过 k 个 hash 函数将这个元素映射到位图的 k 个点,并把它们置为 1;当检索时,再通过 k 个 hash 函数运算检测位图的 k 个点是否都为 1;如果有不为 1 的点,那么认为该 key 不存在;如果全部为 1,则可能存在;
但是不支持删除操作:
在位图中每个槽位只有两种状态(0 或者 1),一个槽位被设置为 1 状态,但不确定它被设
置了多少次;也就是不知道被多少个 key 哈希映射而来以及是被具体哪个 hash 函数映射而
来;
具体的应用场景
布隆过滤器通常用于判断某个 key 一定不存在的场景,同时允许判断存在时有误差的情况;
常见处理场景:① 缓存穿透的解决;② 热 key 限流;
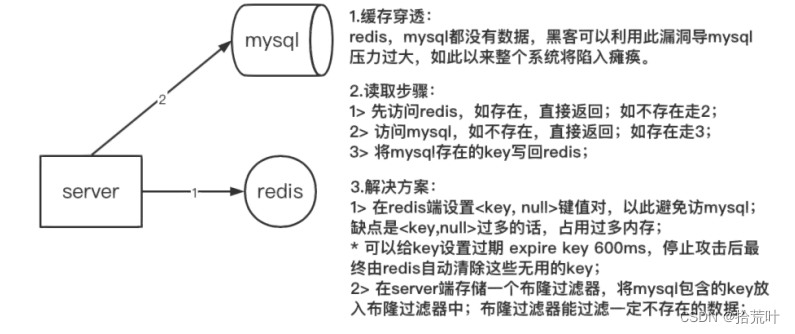
描述缓存场景,为了减轻数据库(mysql)的访问压力,在 server 端与数据库(mysql)之间加入
缓存用来存储热点数据;
描述缓存穿透,server端请求数据时,缓存和数据库都不包含该数据,最终请求压力全部涌向数据库;
数据请求步骤,如上图所示;
发生原因:黑客利用漏洞伪造数据攻击或者内部业务 bug 造成大量重复请求不存在的数据;
解决方案:如上图所示 用布隆过滤器即可解决。
应用分析
在实际应用中,该选择多少个 hash 函数?要分配多少空间的位图?预期存储多少元素?如何控制误差?
有一套公用的公式如下:
n -- 布隆过滤器中元素的个数,如上图 只有str1和str2 两个元素 那么 n=2
p -- 假阳率,在0-1之间 0.000000
m -- 位图所占空间
k -- hash函数的个数
公式如下:
n = ceil(m / (-k / log(1 - exp(log(p) / k))))
p = pow(1 - exp(-k / (m / n)), k)
m = ceil((n * log(p)) / log(1 / pow(2, log(2))));
k = round((m / n) * log(2));
通常给出 需要存储在布隆过滤器中的数据个数(n),和允许存在误差的概率(p),通过上面公司求出 位图所占的空间和hash函数的个数。
选择 hash 函数
选择一个 hash 函数,通过给 hash 传递不同的种子偏移值,采用线性探寻的方式构造多个 hash函数;
#define MIX_UINT64(v) ((uint32_t)((v>>32)^(v)))
uint64_t hash1 = MurmurHash2_x64(key, len, Seed);
uint64_t hash2 = MurmurHash2_x64(key, len, MIX_UINT64(hash1));
for (i = 0; i < k; i++) // k 是hash函数的个数
{
Pos[i] = (hash1 + i*hash2) % m; // m 是位图的⼤⼩
}
分布式一致性hash
背景
分布式一致性 hash 算法将哈希空间组织成一个虚拟的圆环,圆环的大小是 ;
算法为: hash(ip) ,最终会得到一个 [0, ] 之间的一个无符号整型,这个整数代表服务器的编号;多个服务器都通过这种方式在 hash 环上映射一个点来标识该服务器的位置;当用户操作某个 key,通过同样的算法生成一个值,沿环顺时针定位某个服务器,那么该 key 就在该服务器中;
应用场景
分布式缓存;将数据均衡地分散在不同的服务器当中,用来分摊缓存服务器的压力;
解决缓存服务器数量变化尽量不影响缓存失效;
hash偏移
hash 算法得到的结果是随机的,不能保证服务器节点均匀分布在哈希环上;分布不均匀造成请求访问不均匀,服务器承受的压力不均匀;
虚拟节点
为了解决哈希偏移的问题,增加了虚拟节点的概念;理论上,哈希环上节点数越多,数据分布越均
衡;
为每个服务节点计算多个哈希节点(虚拟节点);通常做法是, hash(“IP:PORT:seqno”)
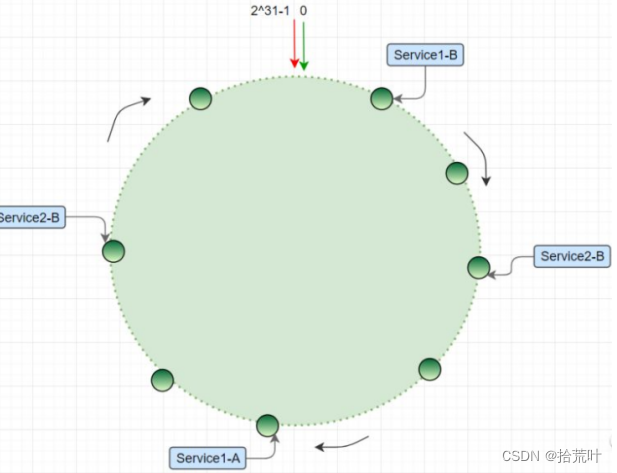
为了解决数据倾斜的问题,我们还需要加入虚拟节点这一策略。
即,将每个数据库都通过定位算法生成几个在 Hash 环上的位置,
每个位置都承担上面节点的功能,
区别在于原来每个数据库对应一个节点,
现在每个数据库会对应若干个节点,
这就是虚拟节点。在添加了虚拟节点的策略之后,
数据倾斜的情况得到了改善。
记住,在实际应用中,几个虚拟节点是不够的,你需要更多的虚拟节点,以保证节点的负载更加均衡。让数据库减少压力的工作
















 313
313











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









