







整理不易,转发请注明出处,请勿直接剽窃!
点赞、关注、不迷路!
摘要: 数仓的作用、整体架构、建模方法、分层原理。从整体上梳理数仓、理解数仓架构。
目的
数据仓库的核心是展现层和提供优质的服务。ETL 及其规范、分层等所做的一切都是为了一个更清晰易用的展现层。
原则
1.屏蔽底层复杂业务,便于数据分析
2.削弱需求变化对模型的影响
3.高内聚松耦合,主题内数据高内聚、主题间数据松耦合
4.各数据源整合和统一,数仓层次清晰
分层好处
1.清晰数据结构
2.数据血缘追踪
3.减少重复开发
4.数据关系条理化,比如客户关系存在于多个源系统中,数仓会把相同主题的数据统一建模,称为清晰的数据模型。
5.屏蔽原始数据的影响,上层数据是由下层加工而来,原始数据变动在加工应用层的过程中可以消除。
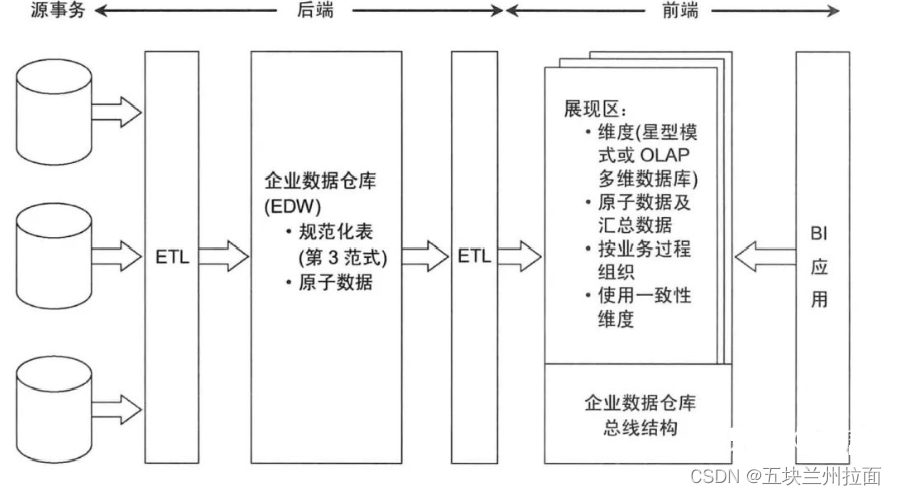
企业数据仓库总线结构
源事务:业务库或者日志等各个方面的数据源,一般不维护历史信息。
第一次ETL:数据源预处理工作(ETL),通常的模型方式是通过E-R模型进行数据整合。目的将各个系统中的数据以整个企业角度按主题进行相似性组合和合并,并进行一致性处理。
第二次ETL:目的是构建和加载数据到展现区的目标维度模型中,划分维度和事实。
模型:围绕业务过程度量事件进行构建,为满足用户无法预估的需求,必须包含详细的原子数据。
建模方法
当前主流建模方法为:ER模型、维度模型
ER模型常用于OLTP数据库建模,应用到构建数仓时更偏重数据整合, 站在企业整体考虑,将各个系统的数据按相似性一致性、合并处理,为数据分析、决策服务,但并不便于直接用来支持分析。缺陷:需要全面梳理企业所有的业务和数据流,周期长,人员要求高。
维度建模是面向OLAP而生,针对分析场景构建数仓模型;重点关注快速、灵活的解决分析需求,同时能够提供大规模数据的快速响应性能。针对性强,主要应用于数据仓库构建和OLAP引擎低层数据模型。优点:不需要完整的梳理企业业务流程和数据,实施周期根据主题边界而定,容易快速实现demo,而且相对来说便于理解、提高查询性能、对称并易扩展。
数仓分层
维度建模理论中,基于事实表和维度表构建数据仓库。在实际操作中,一般会使用ODS(Operational Data Store,运营数据存储)层、DW(Data Warehouse,数据仓库)层、ADS(Application Data Service,应用数据服务)层三级结构。
1、ODS层
ODS层一般作为业务数据库的镜像。在项目中,数仓工程师通常通过数据抽取工具(例如Sqoop、DataX等)将业务库的数据复制到数仓的ODS层,供后续建模使用。ODS层的数据结构和业务数据库保持一致,建立ODS的原因在于,通过复制一份数据到ODS层,可以避免建模过程直接访问业务数据库,从而对业务数据库带来影响,避免影响线上业务。
2、 DW层
将数据导入ODS层后,即可对ODS层的数据进行清洗、建模,最终生成DW层的数据。其中生成DW层的本质即为本章提到的逆规范化的过程。由于ODS中的数据本质上是业务数据库的副本,因此ODS中的数据是高范式的数据,不适合进行OLAP分析。这也导致了在进行OLAP分析前需要将高范式的ODS数据通过一些手段逆规范化到低范式的数据(降范)。低范式的数据作为DW层的数据,对外提供分析服务。
在逆规范化时,可能会产生一些中间结果,这些中间结果也可以存储于DW层中,因此在DW中有时会再次进行细分,划分成DWD(Data Warehouse Details,数据仓库明细)层、DWM(Data Warehouse Middle,数据仓库中间)层、DWS(Data Warehouse Service,数据仓库服务)层三个更细分的层次。
ODS层的数据通过清洗后存储到DWD层,DWD层(原子粒度)本质上是一个去除了脏数据的高质量的低范式的数据层。DWD层的数据通过聚合,形成宽表并保存到DWM层中。DWM层已经是低范式的数据层了,可以用于OLAP分析。在某些场景中,可以对DWM层的数据进行业务重新聚合,以支持更复杂的业务,此时需要生成的数据保存到DWS层中。
在这3个细分的DW层中,并不是所有场景下都需要齐备的。DW层的本质就是对高范式的数据进行逆规范化,生成低范式数据的过程。读者只需要把握住这个核心即可,在实际的维度建模过程中,根据业务的实际需求进行建模,不需要在所有的场景下都机械地遵循DWD层、DWM层、DWS层的三层架构。
3、ADS层
ADS层数据本质上面向业务的,高度业务化的数据。可以认为是基于DW层分析的结果,很多情况下是指标、标签等计算结果。
我认为的数仓分层架构
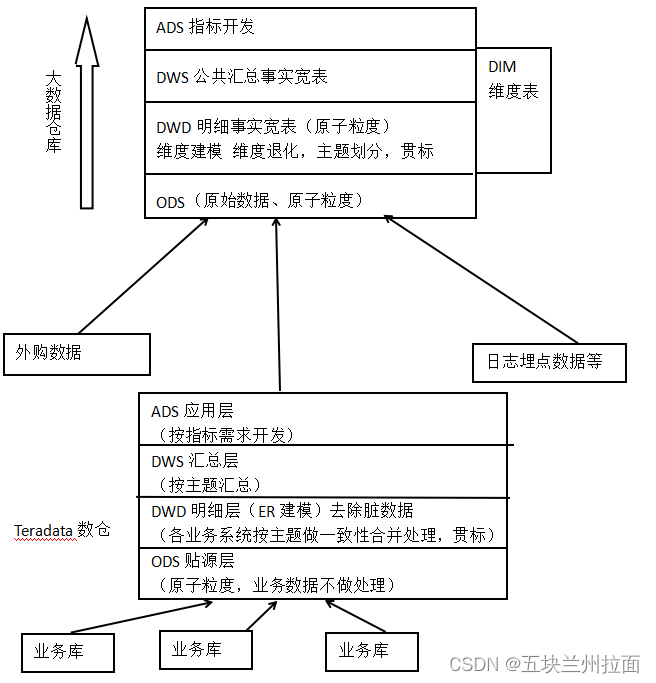
1.数仓分层不是固定的,但原理都是相同(各业务数据做一致性处理和降范)。目前我所在的金融行业都采用ER建模,使用的td数据库承担了数仓的职责和分层,虽然cdh大数据数仓按维度建模分层,但日常开发中几乎没有用到,削弱或者跳过维度建模,直接主题聚合(合并)或者进入数仓的就是上游加工好的数据,在ods缓冲一下直接做ads指标开发。
2.维度退化:维度存储到事实表中,减少关联,可加快查询。
3.DW层(DWS\DWD\DIM)应该积极了解应用层数据需求,将公用数据沉淀到公共层,为上层提供数据服务。
4.有针对性的建设DWS层,避免应用层过度引用和依赖DWD明细数据。
5.DWD存在的意义是做数据的标准化、为上层提供干净、统一、标准的数据。
补充:指标系统
主要分为:原子指标和派生指标
原子指标指的最细粒度,是业务定义中不可再拆分的指标,如支付金额。
派生指标是更高粒度的,比如店铺近1天订单支付金额。
派生指标=维度+原子指标+修饰词
店铺是维度,近1天是时间类型的修饰词,支付金额是原子指标。















 1148
1148











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









