





数据建模分层
Topic modeling is a type of statistical modeling for discovering the abstract “topics” in a collection of documents. LDA (Latent Dirichlet Allocation) is one of the most popular and widely used tools for that. However, I am going to demonstrate an alternative tool BigARTM which provides a huge number of opportunities (e.g. special metrics and regularizers) for topic modeling.
主题建模是一种统计建模,用于发现文档集合中的抽象“主题”。 LDA(潜在狄利克雷分配)是最流行且使用最广泛的工具之一。 但是,我将演示一个替代工具BigARTM,它为主题建模提供了大量机会(例如,特殊指标和规范化程序)。
First of all, let’s formulate our task. Initially, we have a distribution over words in documents, but we need to get topic-word distribution and topic-document distribution. So, it is just a task of stochastic matrix factorization.
首先,让我们制定任务。 最初,我们对文档中的单词进行了分布,但是我们需要进行主题词分布和主题文档分布。 因此,这只是随机矩阵分解的任务。
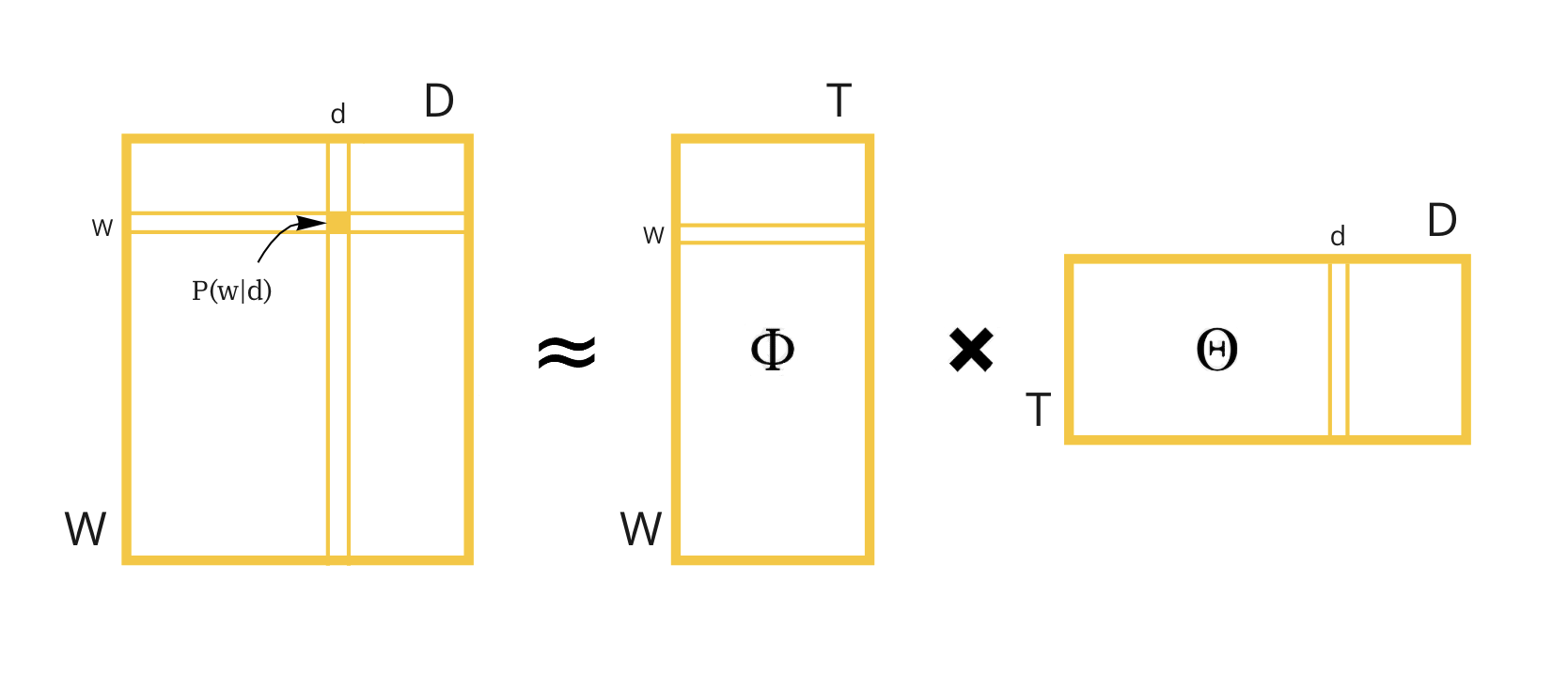
I will use NIPS papers to illustrate principles of the library.
我将使用NIPS论文来说明该库的原理。
df = pd.read_csv(‘./papers.csv’)
all_texts = df.PaperText
all_texts[111]‘Differentially Private Subspace Clustering\n\nYining Wang, Yu-Xiang Wang and Aarti Singh\nMachine Learning Department…’
“差异化私有子空间聚类\ n \ n王伊宁,王玉香和Aarti Singh \ n机器学习部门…”
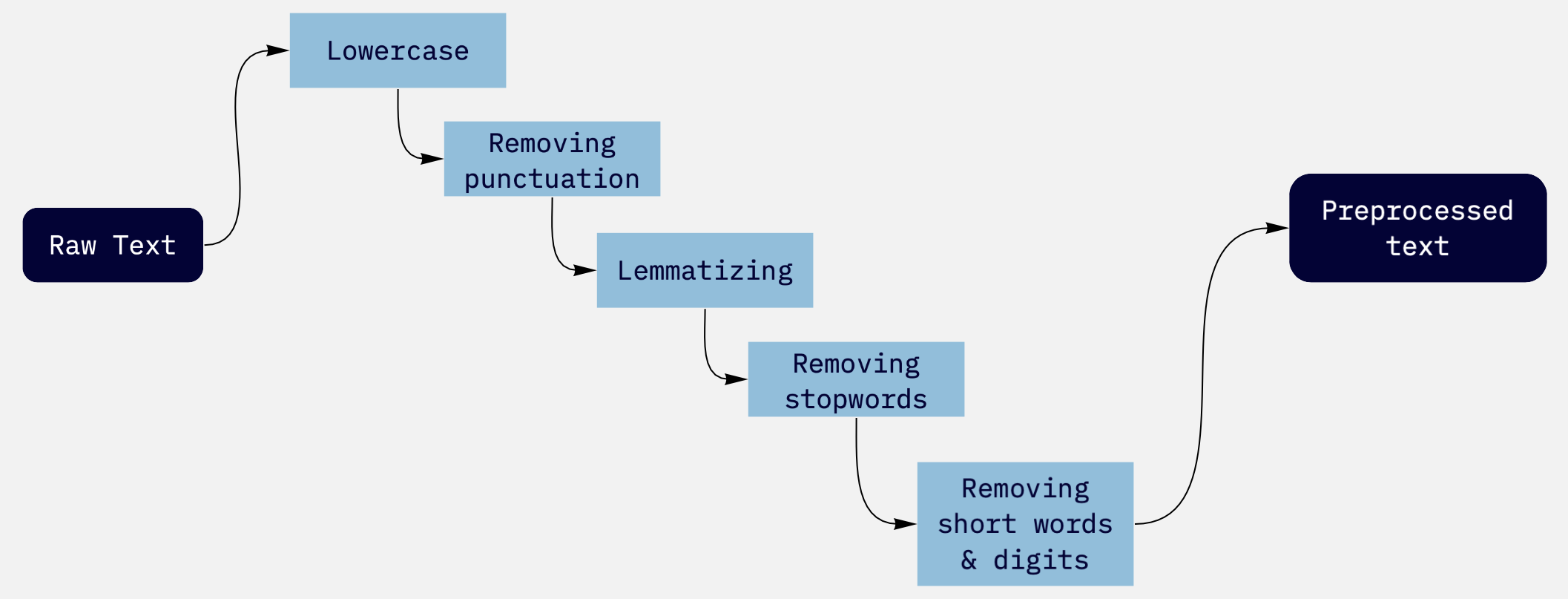
We begin with data preproccesing with a pipeline:
我们首先使用管道进行数据预处理:
‘differentially private subspace clustering yining wang yuxiang wang aarti singh machine learning department…’
“差分私有子空间集群yining wang yuxiang wang aarti singh机器学习部门……”
Now we are ready to tokenize the sentences, obtain a bag of words and perform topic modeling. By the way, n-grams are sometimes very useful for this purpose. They help to extract well-established expressions and understand each topic better. I decided to get only bigrams, however, you can choose any number. We’ll take ones that are the most frequent among the documents.
现在我们准备标记这些句子,获得一袋单词并执行主题建模。 顺便说一句,n-gram有时对此非常有用。 它们有助于提取明确的表达方式并更好地理解每个主题。 我决定只获取二元组,但是,您可以选择任何数字。 我们将采用文档中最常见的文档。
10349
10349
[‘machine learning’, ‘neural network’, ‘lower bound’, ‘international conference’, ‘upper bound’]
[“机器学习”,“神经网络”,“下限”,“国际会议”,“上限”]
Bigrams seem useful, it will help us to distinguish different topics. All preprocessing has been done so we can move to our model. To do this, we have to create a matrix with words over documents which the model uses as an input.
二元组似乎很有用,它将帮助我们区分不同的主题。 所有预处理都已完成,因此我们可以转到模型。 为此,我们必须创建一个在文档上带有单词的矩阵,该模型用作输入。
ARTM模型 (ARTM model)
ARTM library provides you with a huge functionality to affect the learning process. It allows adding various regularizers to control the learning process and to change phi and theta matrices to be more sparse, for example. In a top level model I added a sparsity regularizer for theta matrix and decorrelator which stimulates phi sparsity.
ARTM库为您提供了影响学习过程的强大功能。 例如,它允许添加各种正则器来控制学习过程,并将phi和theta矩阵更改为更稀疏。 在顶层模型中,我为theta矩阵和去相关器添加了一个稀疏正则化器,以刺激phi稀疏性。
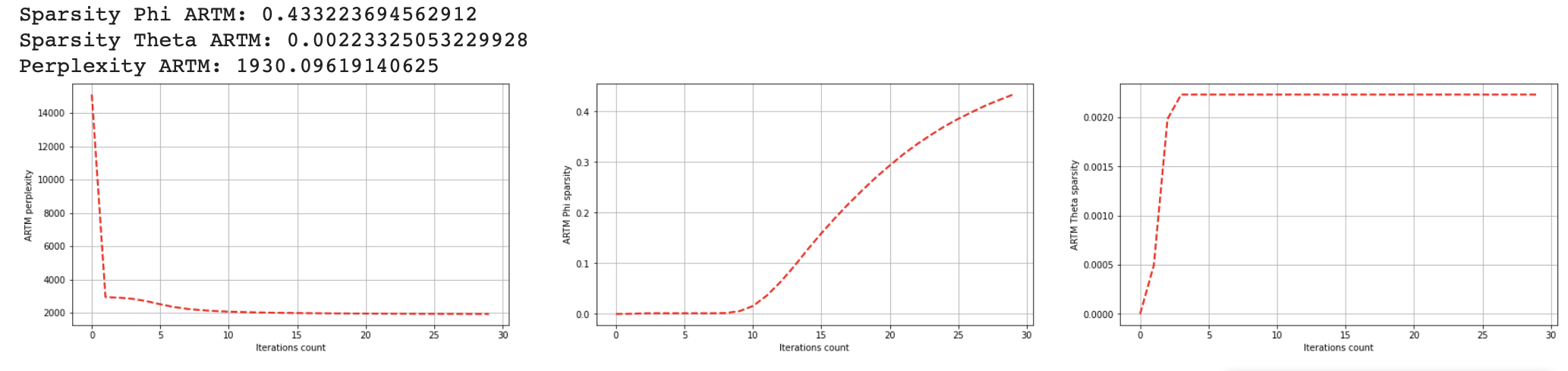
Besides, we can specify metrics that we want to use for evaluation (Here there are Perxplexity and matrices sparstities). We add these regularizers to make topics more interpretable but we have to do that carefully with only a slight decrease of perplexity.
此外,我们可以指定我们要用于评估的指标(此处有Perxplexity和矩阵稀疏性)。 我们添加了这些正则化器以使主题更易于理解,但我们必须谨慎行事,只需要稍微减少一些困惑即可。
Let’s look at the main measures:
让我们看一下主要措施:
We can also now watch the topics that we have obtained
现在我们还可以观看我们获得的主题
for topic_name in model_artm.topic_names:
print(topic_name + ': ' + model_artm.score_tracker['TopTokensScore'].last_tokens[topic_name])
The matrix with topics per documents is rather sparse so we got exactly what we needed.
每个文档的主题矩阵都很稀疏,因此我们可以准确地获得所需的东西。
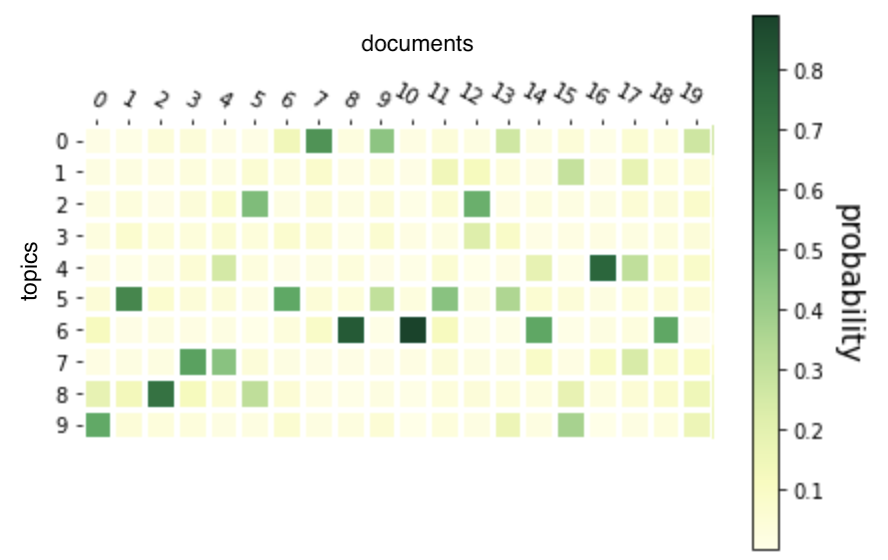
It will be convenient to read the articles which relate to the particular topic. So here we can obtain a list of articles sorted on topic probability.
阅读与特定主题相关的文章将很方便。 因此,在这里我们可以获得按主题概率排序的文章列表。

建筑层次(Building hierarchy)
The topics that we have got seem rather vague, although we can see differences between them. If we are interested in a particular topic, we might want to look at the subtopics of this one and to narrow down the search area. For such purposes, we can build a hierarchy of models that looks like a tree. We will use only one additional level with 50 topics
尽管我们可以看到它们之间的差异,但我们所讨论的主题似乎相当模糊。 如果我们对特定主题感兴趣,则可能需要查看该主题的子主题并缩小搜索范围。 为此,我们可以构建看起来像树的模型层次结构。 我们将仅使用一个附加级别的50个主题

Some examples of words in subtopics:
子主题中的单词示例:
[‘risk’, ‘empirical’, ‘measure’, ‘class’, ‘generalization’, ‘hypothesis’, ‘distance’, ‘estimator’, ‘property’, ‘proof’, ‘bounded’, ‘expected’],
[“风险”,“经验”,“量度”,“类”,“概括”,“假设”,“距离”,“估计量”,“属性”,“证明”,“有界”,“预期”),
[‘activity’, ‘trial’, ‘neuron’, ‘spike’, ‘stimulus’, ‘firing’, ‘neuroscience’, ‘context’, ‘latent’, ‘response’, ‘subunit’, ‘firing rate’],
[“活动”,“试验”,“神经元”,“尖峰”,“刺激”,“射击”,“神经科学”,“上下文”,“潜伏”,“响应”,“亚基”,“射击率”] ,
[‘training’, ‘feature’, ‘label’, ‘object’, ‘loss’, ‘output’, ‘classification’, ‘map’, ‘proposal’, ‘dataset’, ‘input’, ‘region’]
[“培训”,“功能”,“标签”,“对象”,“损失”,“输出”,“分类”,“地图”,“建议”,“数据集”,“输入”,“区域”]
Looks better! Topics began more concrete. Thus, we can look at the most related subtopics to a topic we are interested in.
看起来更好! 话题开始更加具体。 因此,我们可以查看与我们感兴趣的主题最相关的子主题。
def subtopics_wrt_topic(topic_number, matrix_dist):
return matrix_dist.iloc[:, topic_number].sort_values(ascending = False)[:5]subtopics_wrt_topic(0, subt)subtopic_7 0.403652
subtopic_7 0.403652
subtopic_58 0.182160
subtopic_58 0.182160
subtopic_56 0.156272
subtopic_56 0.156272
subtopic_13 0.118234
subtopic_13 0.118234
subtopic_47 0.015440
subtopic_47 0.015440
We can choose documents on subtopics as we did it previously.
我们可以像以前一样选择有关子主题的文档。
Thanks for reading. I hope I introduced briefly the functionality of the library, but if you want to go into detail, there is documentation with lots of additional information and useful tricks (modalities, regularizers, input formats, etc.).
谢谢阅读。 我希望我简要介绍了该库的功能,但是如果您想详细介绍它,则可以找到包含大量其他信息和有用技巧(模式,正则化程序,输入格式等)的文档。
Looking forward to hearing any questions.
期待听到任何问题。
翻译自: https://towardsdatascience.com/hierarchical-topic-modeling-with-bigartm-library-6f2ff730689f
数据建模分层















 1908
1908











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









