







Scipy常用函数
Scipy统计相关函数介绍
Scipy是一个用于科学计算和技术计算的Python库,它提供了许多高效的数值算法,包括线性代数、优化、积分、插值、信号处理等。在本文中,我们主要关注Scipy的统计模块,即scipy.stats,它包含了多种概率分布的随机变量,以及一些常用的统计函数和测试方法。
一、描述性统计
-
均值、方差、标准差、偏度、峰度等基本统计量:stats.describe()
stats.describe(X).mean ``` array([6.41853125e+03, 3.02343750e+00, 2.44531250e+00, 1.06216875e+04, 5.23437500e-01]) ``` -
频数分布和直方图:stats.relfreq() stats.cumfreq() stats.histogram()
(1)stats.relfreq()是一个用来计算相对频率直方图的函数,它使用histogram函数来实现。相对频率直方图是一种显示每个区间内观测值占总观测值比例的图形。它有四个参数:a(输入数组),numbins(直方图的区间数),defaultreallimits(直方图的范围),weights(每个数组元素的权重)。例如:
import numpy as np from scipy import stats # 生成一些随机数据 data = np.random.randint(1, 11, size=20) # 使用5个区间计算相对频率直方图 result = stats.relfreq(data, numbins=5) # 打印结果 print(result.frequency) ``` [0.2 , 0.15, 0.25, 0.2 , 0.2 ] ```这意味着20%的数据在1和3之间,15%的数据在3和5之间,依此类推。
(2)stats.cumfreq()是一个用来计算累积频率直方图的函数,它使用histogram函数来实现。累积频率直方图是一种显示每个区间内观测值的累积数量的图形。它有四个参数:a(输入数组),numbins(直方图的区间数),defaultreallimits(直方图的范围),weights(每个数组元素的权重)。例如:
import numpy as np from scipy import stats import matplotlib.pyplot as plt # 生成一些随机数据 data = np.random.randint(1, 11, size=20) # 使用5个区间计算累积频率直方图 result = stats.cumfreq(data, numbins=5) # 打印结果 print(result)输出:
CumfreqResult(cumcount=array([ 4., 7., 12., 16., 20.]), lowerlimit=1.0,binsize=2.0, extrapoints=0)这意味着有4个数据在1和3之间,7个数据在1和5之间,依此类推。
如果想要绘制累积频率直方图,可以使用matplotlib.pyplot模块,例如:
# 绘制累积频率直方图 plt.bar(result.lowerlimit + np.arange(result.binsize, result.binsize * result.cumcount.size + 1, result.binsize), result.cumcount, width=result.binsize) -
分位数和百分位数:stats.scoreatpercentile() stats.percentileofscore()
stats.scoreatpercentile()是一个用于计算数据的百分位数的函数1。百分位数是一种用于表示数据位置的统计量,它表示在数据中有多少比例的数据小于或等于某个值2。
stats.scoreatpercentile()函数提供了四种插值方法3:
- ‘fraction’:按比例插值,即在两个最近的数据点之间按照百分位数的比例取一个中间值
- ‘lower’:取较小的数据点,即在两个最近的数据点之间取较小的那个
- ‘higher’:取较大的数据点,即在两个最近的数据点之间取较大的那个
- ‘nearest’:取最近的数据点,即在两个最近的数据点之间取距离百分位数更近的那个
不同的插值方法会影响百分位数的精度和稳定性,一般来说,'fraction’是比较常用和合理的选择4
# 生成100个服从正态分布的随机数 a = np.random.randn(100) # 计算第25、50和75百分位数,并指定插值方法和轴参数 p25 = stats.scoreatpercentile(a, 25, interpolation_method='lower') p50 = stats.scoreatpercentile(a, 50) p75 = stats.scoreatpercentile(a, 75, interpolation_method='higher', axis=0)percentofscore就不用讲了吧,见名知意
-
相关系数和协方差矩阵:stats.pearsonr() stats.spearmanr() stats.kendalltau() stats.cov()
这几种方法详情可见:【科创】傅一航:你知道的相关系数有几种? (qq.com)
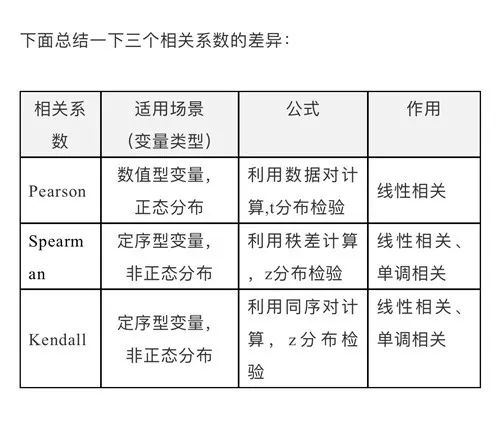
stats.pearsonr(),stats.spearmanr(),stats.kendalltau()和stats.cov()都是用来计算两个数据集之间的相关性的函数,但它们有以下区别:
-
stats.pearsonr()计算皮尔逊相关系数1,它是一种度量两个连续变量之间线性关系强度的参数方法。
-
stats.spearmanr()计算斯皮尔曼秩相关系数23,它是一种度量两个有序变量之间单调关系强度的非参数方法。
斯皮尔曼秩相关系数是一种非参数统计量,用于衡量两个变量之间的单调相关性,即两个变量的值随着等级的变化而同向或反向变化的程度。斯皮尔曼秩相关系数与皮尔逊相关系数类似,但不要求两个变量呈线性关系,也不要求两个变量服从正态分布。斯皮尔曼秩相关系数适用于存在等级变量或者无法用均数和标准差描述其分布特征时的情况。
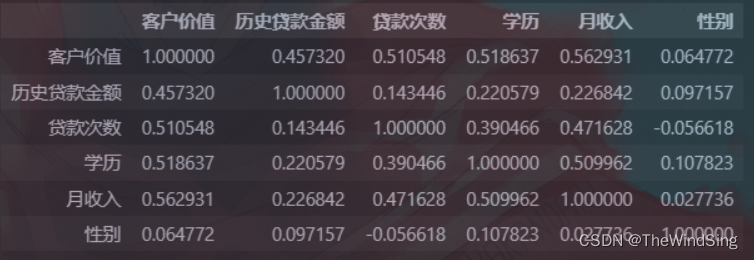
pd.DataFrame(stats.spearmanr(customer_value).correlation, columns=customer_value.columns, index=customer_value.columns)
-
stats.kendalltau()计算肯德尔τ系数456,Kendall Rank相关系数,即肯德尔秩相关系数(KROCC),常用希腊字母τ(tau)表示,也是用于度量定序型变量间的线性相关关系,与Spearman秩相关系数基本类似。但与Spearman相关系数不同的是,Kendallτ相关系数使用秩的同序对(concordant pairs)数目U和异序对(discordant pairs)数目V来计算相关系数。什么叫做同序对?即两个变量的秩同时增大的秩对。
1) 如果两变量具有较强的正相关关系,则同序对数目U应该比较大,而异序对数目V应该比较小。
2) 如果两变量具有较强的负相关关系,则同序对数目U应该比较小,而异序对数目V应该比较大。
3) 如果两变量的相关性较弱,则同序对数目U和异序对数目V应该大致相等,即各占一半。
stats.kendalltau(customer_value['客户价值'], customer_value['贷款次数']).correlationstats.cov()计算协方差矩阵,它是一种描述两个或多个随机变量之间线性依赖程度的参数方法。
-
二、概率分布
-
常见的连续型概率分布:正态分布(stats.norm) 指数分布(stats.expon) 卡方分布(stats.chi2) t分布(stats.t) F分布(stats.f) 等
-
常见的离散型概率分布:伯努利分布(stats.bernoulli) 泊松分布(stats.poisson) 几何分布(stats.geom) 超几何分布(stats.hypergeom) 等
-
概率密度函数、累积密度函数、生存函数等概率函数:pdf() cdf() sf()
pdf和cdf
stats.norm(0, 1).cdf(1.96)
rvs()用于生成给定类型的随机变量12。scipy.stats模块中有许多预定义的连续和离散分布,每个分布都有一个 rvs()方法,可以根据分布的参数生成随机数3。rvs()函数的用法是:
stats.norm(0, 1).rvs()
或者
stats.norm.rvs(0,100,size=10)
三、参数估计和假设检验
-
点估计和区间估计:stats.ttest_1samp() stats.ttest_ind() stats.ttest_rel() stats.chisquare()stats.f_oneway() stats.wilcoxon() 等
- stats.ttest_1samp()是一个用于进行单样本t检验的函数,它可以检验一个样本的均值是否等于某个指定的值1。
- stats.ttest_ind()是一个用于进行独立样本t检验的函数,它可以检验两个独立样本的均值是否相等2。
- stats.ttest_rel()是一个用于进行相关样本t检验的函数,它可以检验两个相关样本的均值是否相等3。
- stats.chisquare()是一个用于进行卡方检验的函数,它可以检验一个或多个观察频数是否符合期望频数或者两组观察频数是否有显著差异。
- stats.f_oneway()是一个用于进行单因素方差分析(ANOVA)的函数,它可以检验多个(至少两个)组别之间的均值是否有显著差异。
- stats.wilcoxon()是一个用于进行Wilcoxon符号秩检验或Wilcoxon秩和检验的函数,它可以在不满足正态分布假设时,对两个相关样本或独立样本进行非参数检验
这里举一个例子,其他都差不多
stats.ttest_ind()是一个用于进行独立样本t检验的函数,它可以检验两个样本的均值是否存在显著差异12。它的基本用法是:
scipy.stats.ttest_ind(a, b, axis=0, equal_var=True, nan_policy='propagate', permutations=None, random_state=None, alternative='two-sided', trim=0)其中a和b是两个数组,axis是指定沿哪个维度进行检验,默认为0,equal_var是指定两个样本是否具有相同的方差,默认为True,nan_policy是指定如何处理缺失值,默认为’propagate’,permutations是指定随机排列的次数,默认为None,random_state是指定随机数生成器的种子,默认为None,alternative是指定备择假设的方向,默认为’two-sided’,trim是指定去除两端极端值的比例,默认为03。
该函数会返回一个Ttest_indResult对象,包含两个属性:statistic和pvalue。statistic是t统计量的值,pvalue是对应的p值124。如果p值小于某个显著性水平(比如0.05),则认为两个样本均值存在显著差异2。
在使用stats.ttest_ind()之前,建议先使用stats.levene()函数来检验两个样本是否具有方差齐性4。如果方差不齐,则需要将equal_var参数设置为False5。
当时是两个相关样本,做配对t检验可以用ttest_rel,比如同一组学生在不同考试中的分数,或从相同单元中重复抽样。该测试衡量样本之间的平均分数是否存在显著差异(例如考试)。如果我们观察到一个大的p-value,例如大于 0.05 或 0.1,那么我们不能拒绝相同平均分数的原假设。如果 p-value 小于阈值,例如1%、5% 或 10%,那么我们拒绝均值相等的原假设。小p-values 与大t-statistics 相关联。
统计量计算为
np.mean(a - b)/se,其中se是标准误差。因此,当a - b的样本均值大于零时统计量为正,而当a - b的样本均值小于零时统计量为负。scipy.stats.ttest_rel(a, b, axis=0, nan_policy='propagate', alternative='two-sided')
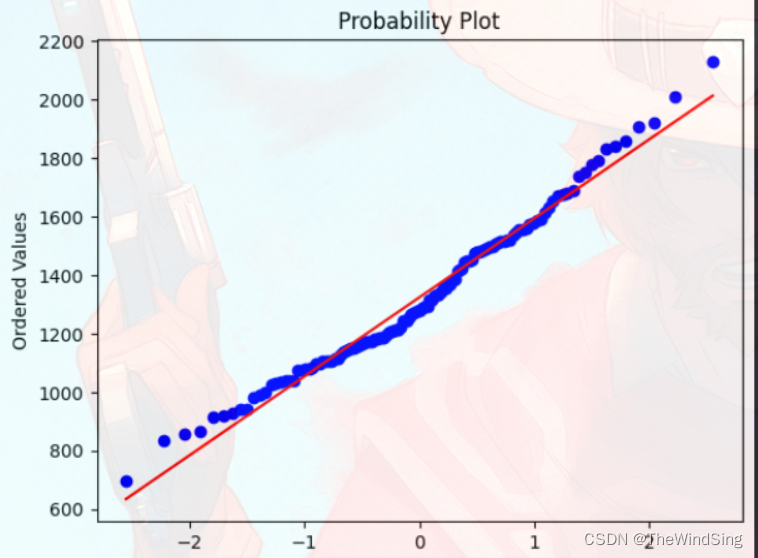
2,scipy.stats.probplot: 生成概率图或QQ图,用于检验数据是否符合某种分布,比如可以用于检测是否来自 一个正态总体
qq图是一种用于比较两个分布是否相似的散点图,它的横坐标是一个分布的分位数,纵坐标是另一个分布的分位数1。如果两个分布相似,那么qq图上的点会近似地在一条直线上12。
qq图常用于检验样本数据是否服从正态分布,即将样本数据和标准正态分布进行比较。如果样本数据近似于正态分布,那么qq图上的点会大致在一条斜率为标准差,截距为均值的直线附近12。如果样本数据偏离正态分布,那么qq图上的点会呈现出弯曲或扭曲的形状3。
要看懂qq图,需要注意以下几点:
- qq图只能反映出两个分布之间的整体相似性,不能反映出具体的差异或异常值。
- qq图不能确定两个分布是否完全相同,只能判断它们是否有相同的形状(如位置、比例和偏度)。
- qq图对于小样本数据可能不够敏感,对于大样本数据可能过于敏感。
- qq图可以用来比较任意两个分布,不一定是正态分布。但是如果要比较非正态分布,需要指定合适的理论或参考分布。
stats.probplot(customer_value["客户价值"], dist="norm", plot=plt)














 6599
6599











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









