







本系列
- 本地缓存库分析(一):golang-lru
- 本地缓存库分析(二):bigcache
- 本地缓存库分析(三):freecache
- 本地缓存库分析(四):fastcache
- 本地缓存库分析(五):groupcache(本文)
前言
groupcache是一个分布式本地缓存库,根据 一致性hash 算法决定某个key由自己负责,还是别的节点负责
存在本地的缓存用 LRU 管理内存淘汰
这个库只暴露了 Get 接口(传一个fn进去,缓存中Get不到时调fn从其他地方获取数据,放入缓存),而 不支持 Set/Update/Delete 操作。因此适用场景有限,适合那种对于给定key来说,value不会变的数据
例如静态文件,拿md5当key,value是文件内容
这么做的好处是不会有更新导致的缓存一致性问题,因为就更新不了
下面对一些关键设计进行分析
本文走读源码:https://github.com/golang/groupcache,2024.11.2时刻的版本
一致性hash
当get请求到来时,groupcache根据一致性hash算法计算key由哪个节点负责。如果是自己负责,就调fn获取数据(一般从db查),否则就请求其他节点拿数据
groupcache提供了一版非常易于理解的,标准一致性hash实现,结构如下:
type Map struct {
hash Hash
// 每个节点有多少个副本
replicas int
// 表示hash环
keys []int
// 根据环上的hash值找节点
hashMap map[int]string
}
初始化方法设置每个虚拟节点数和hash方法
func New(replicas int, fn Hash) *Map {
m := &Map{
replicas: replicas,
hash: fn,
hashMap: make(map[int]string),
}
if m.hash == nil {
m.hash = crc32.ChecksumIEEE
}
return m
}
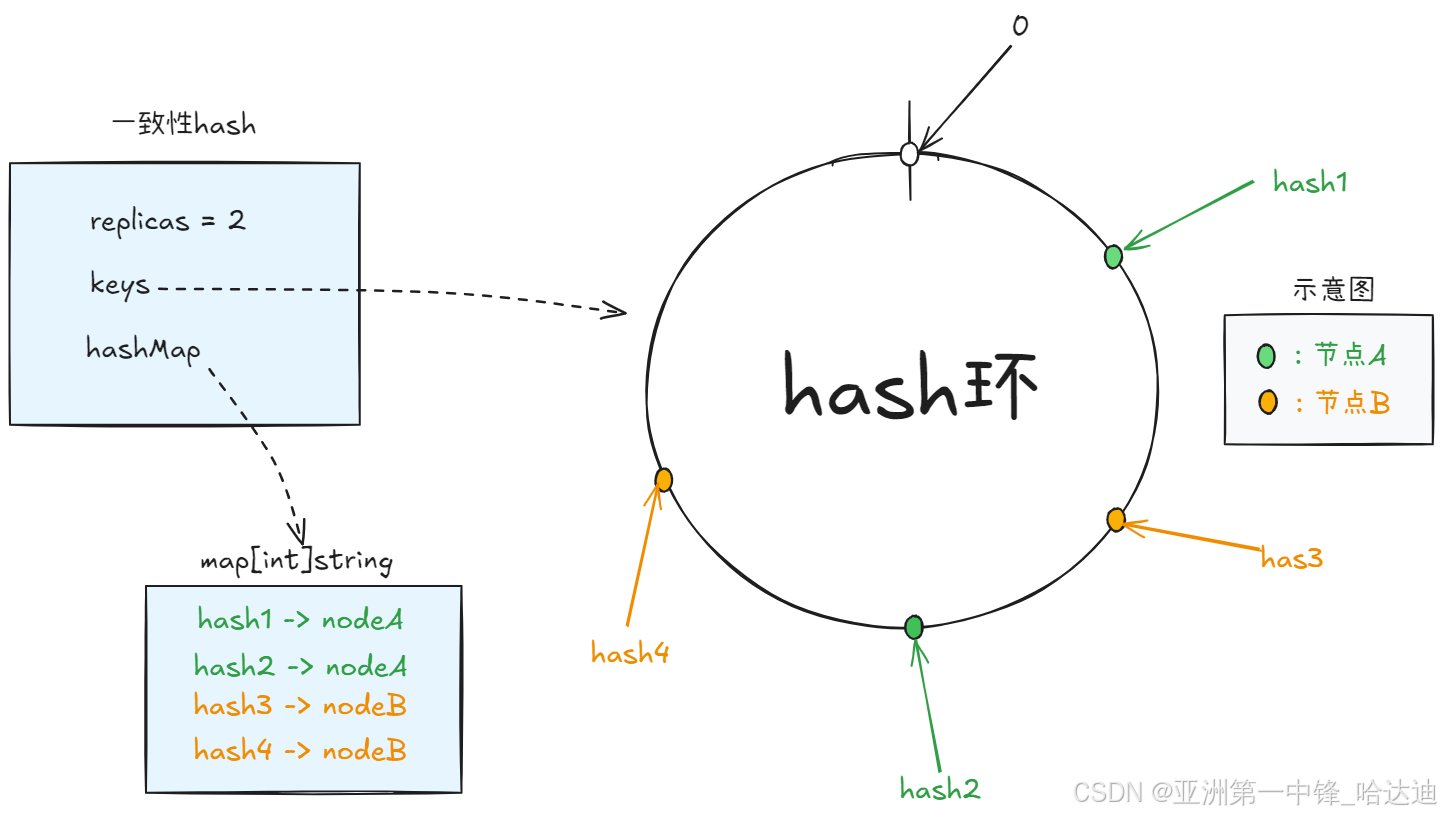
接下来需要添加节点到hash环上:
-
对每个节点创建m.replicas个虚拟节点,加入环中
- 每个虚拟节点的hash值通过
hash(key + 编号)得到
- 每个虚拟节点的hash值通过
-
保存hash值到key的映射
- 如果出现hash冲突,保留相同hash值的最后一个节点。这个对一致性hash算法的影响非常低,因为基本不可能出现hash冲突
-
将环排序,方便后面查找使用
// 添加节点
func (m *Map) Add(keys ...string) {
for _, key := range keys {
// 创建replicas个虚拟节点
for i := 0; i < m.replicas; i++ {
hash := int(m.hash([]byte(strconv.Itoa(i) + key)))
// 把hash值加入环中
m.keys = append(m.keys, hash)
// hash到key的映射,如果有hash冲突,映射到最后一个节点
m.hashMap[hash] = key
}
}
// 使环保持有序
sort.Ints(m.keys)
}
来了一个key,怎么定位应该在哪个节点上:
-
计算key的hash值
-
在环上二分查找,找到大于等于key hash值第一个节点,就是负责该key的节点
-
如果没有这样的节点,那就是第一个节点负责
- 此时应该是最后一个节点的下一个节点负责,在数组上看起来没有下一个节点了,但在环的视角看,因为hash环是首尾相连的,下一个节点就是第一个节点
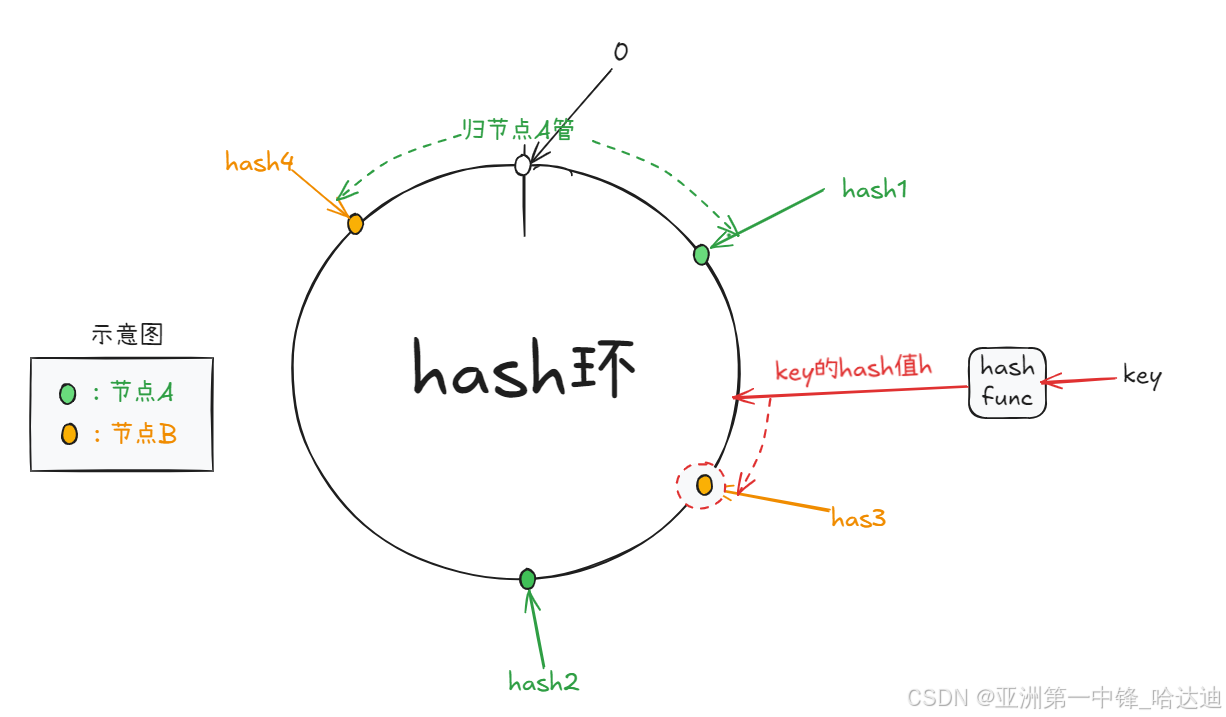
代码如下:
// 计算key在哪个节点上
func (m *Map) Get(key string) string {
if m.IsEmpty() {
return ""
}
hash := int(m.hash([]byte(key)))
// 找到 大于等于hash的第一个节点
idx := sort.Search(len(m.keys), func(i int) bool { return m.keys[i] >= hash })
// 如果都小于,那么就是第0个节点负责该key
if idx == len(m.keys) {
idx = 0
}
return m.hashMap[m.keys[idx]]
}
singleflight
当本地缓存没有,需要请求其他节点,或需要访问db时,用singleflight保证相同key同时只会发出一个请求,这样能最大限度减少对下游的压力,避免缓存击穿
相比标准库的singleflight,这里提供的代码要简洁很多
数据结构如下:
type call struct {
wg sync.WaitGroup
val interface{}
err error
}
type Group struct {
mu sync.Mutex
// m[key]存在,说明该key正在请求
m map[string]*call
}
Do方法传入 key 和 fn,fn代表key不存在时,怎么获取数据
func (g *Group) Do(key string, fn func() (interface{}, error)) (interface{}, error) {
g.mu.Lock()
if g.m == nil {
g.m = make(map[string]*call)
}
// 该key正在请求下游,自己等待就好
if c, ok := g.m[key]; ok {
g.mu.Unlock()
c.wg.Wait()
return c.val, c.err
}
// 自己准备发起请求
c := new(call)
c.wg.Add(1)
g.m[key] = c
g.mu.Unlock()
// 注意这里的顺序,先设置结果,再通知其他goroutine数据已准备好
c.val, c.err = fn()
c.wg.Done()
g.mu.Lock()
delete(g.m, key)
g.mu.Unlock()
return c.val, c.err
}
LRU
把数据从其他节点或自己的db拿到后,会保存在本地缓存中,但本地缓存空间不是无限的,需要用LRU算法管理内存淘汰
LRU的双向链表使用了 标准库container的list,其他的实现就是标准LRU,下面简单走读源码
结构如下:
type Cache struct {
// 最大容量,如果为0表示没限制
MaxEntries int
// 删除回调
OnEvicted func(key Key, value interface{})
ll *list.List
cache map[interface{}]*list.Element
}
type Key interface{}
type entry struct {
key Key
value interface{}
}
func New(maxEntries int) *Cache {
return &Cache{
MaxEntries: maxEntries,
ll: list.New(),
cache: make(map[interface{}]*list.Element),
}
}
Get方法:
func (c *Cache) Get(key Key) (value interface{}, ok bool) {
if c.cache == nil {
return
}
// 缓存中有该key,将节点移动到头部,返回
if ele, hit := c.cache[key]; hit {
c.ll.MoveToFront(ele)
return ele.Value.(*entry).value, true
}
return
}
Add方法:
func (c *Cache) Add(key Key, value interface{}) {
if c.cache == nil {
c.cache = make(map[interface{}]*list.Element)
c.ll = list.New()
}
// 缓存中存在,将其移动到队头
if ee, ok := c.cache[key]; ok {
c.ll.MoveToFront(ee)
ee.Value.(*entry).value = value
return
}
// 缓存中不存在该key,添加到头部
ele := c.ll.PushFront(&entry{key, value})
c.cache[key] = ele
if c.MaxEntries != 0 && c.ll.Len() > c.MaxEntries {
// 如果容量超了,删除最老的KV
c.RemoveOldest()
}
}
热点数据备份
在分布式缓存系统中,一般需要从两个层面考虑均衡问题:
- 从
数据分布层面看是否均衡 - 从
访问频率看是否均衡
针对第一点,只要一致性hash的虚拟节点足够多,hash算法没啥问题,那么数据在每个节点之间的分布就是均衡的
但是针对第二点,如果某些 key 属于热点数据且被大量访问,会导致请求都在少量节点上,造成这些节点压力过大
groupcache 通过热点数据备份的机制用来解决该问题:每个节点除了会缓存本节点存在且大量访问的 key 之外,也会缓存那些不属于当前节点,但是被频繁访问的key
上面是groupcache一些关键特性的分析,下面进行源码走读
Get流程
Group的主要字段如下:
type Group struct {
name string
// 怎么从db获取数据
getter Getter
// 用于计算key应该被哪个节点服务,封装了一致性hash
peers PeerPicker
// 容量限制
cacheBytes int64
// mainCache持有当前节点负责的key
mainCache cache
// 存储不是当前节点负责,但是是热点数据,避免跨节点的网络请求
hotCache cache
// singleflight
loadGroup flightGroup
}
完整的get流程如下:
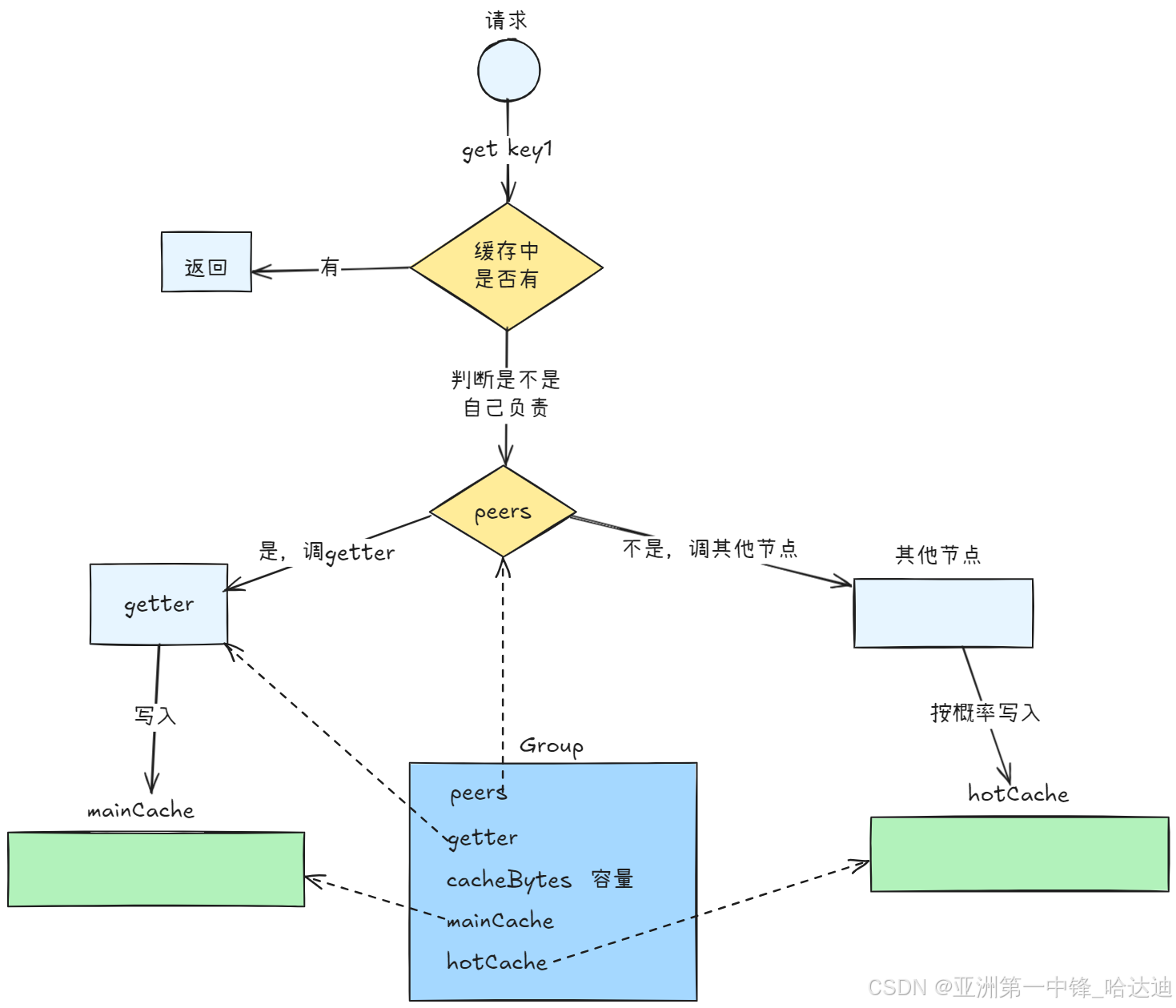
func (g *Group) Get(ctx context.Context, key string, dest Sink) error {
/**
...
*/
// 先查本地缓存,包括mainCache和hotCache
value, cacheHit := g.lookupCache(key)
if cacheHit {
// 本地缓存有,返回
return setSinkView(dest, value)
}
// 本地没有,从其他节点或db查,然后放到缓存中
value, destPopulated, err := g.load(ctx, key, dest)
if err != nil {
return err
}
return setSinkView(dest, value)
}
查本地缓存比较简单,就是检查key在两个cache中是否存在:
func (g *Group) lookupCache(key string) (value ByteView, ok bool) {
value, ok = g.mainCache.get(key)
if ok {
return
}
value, ok = g.hotCache.get(key)
return
}
本地缓存没有时,主体处理流程如下:
func (g *Group) load(ctx context.Context, key string, dest Sink) (value ByteView, destPopulated bool, err error) {
g.Stats.Loads.Add(1)
viewi, err := g.loadGroup.Do(key, func() (interface{}, error) {
// 再次检查缓存,因为可能有并发请求已经将结果放到缓存了
if value, cacheHit := g.lookupCache(key); cacheHit {
return value, nil
}
var value ByteView
var err error
// 不是自己负责,就从一致性hash环拿到目标节点
if peer, ok := g.peers.PickPeer(key); ok {
// 发送请求,并将结果放到缓存中
value, err = g.getFromPeer(ctx, peer, key)
if err == nil {
return value, nil
}
}
// 到这说明key是自己负责
// 本地缓存没有,那就要从db里查
value, err = g.getLocally(ctx, key, dest)
if err != nil {
return nil, err
}
// 放到缓存中
g.populateCache(key, value, &g.mainCache)
return value, nil
})
if err == nil {
value = viewi.(ByteView)
}
return
}
从其他节点获取数据,并放入 hotcache 缓存,以 1/10的概率 放入
func (g *Group) getFromPeer(ctx context.Context, peer ProtoGetter, key string) (ByteView, error) {
req := &pb.GetRequest{
Group: &g.name,
Key: &key,
}
res := &pb.GetResponse{}
err := peer.Get(ctx, req, res)
if err != nil {
return ByteView{}, err
}
value := ByteView{b: res.Value}
// 1/10的概率加到本地的hotcache中
if rand.Intn(10) == 0 {
g.populateCache(key, value, &g.hotCache)
}
return value, nil
}
在将数据放入缓存时,会进行内存淘汰
保持 hotcache 的占用最多是 maincache 的 1/8,毕竟主要还是缓存自己负责的数据
func (g *Group) populateCache(key string, value ByteView, cache *cache) {
if g.cacheBytes <= 0 {
return
}
cache.add(key, value)
// 如果内存超了,淘汰一些缓存
for {
mainBytes := g.mainCache.bytes()
hotBytes := g.hotCache.bytes()
if mainBytes+hotBytes <= g.cacheBytes {
return
}
victim := &g.mainCache
// 保持hotcache的占用最多是maincache的 1/8
if hotBytes > mainBytes/8 {
victim = &g.hotCache
}
victim.removeOldest()
}
}
总结
最后看看groupcache解决了哪些原生缓存的问题:
| 问题 | 解决 |
|---|---|
| 锁竞争严重 | 未解决,用一个大锁 |
| 大量缓存写入,导致gc标记阶段占用cpu多 | 未解决 |
| 内存占用不可控 | 解决,虽然底层不是字节数组,但用户设置的value需要给出占用字节数,然后groupcache严格按照字节数限制内存 |
| 不支持缓存按时效性淘汰 | 支持,按LRU淘汰 |
| 不支持缓存过期 | 不支持 |
| 缓存数据可以被污染 | 未解决 |
就性能来说,groupcache不如之前介绍的几款缓存库
但其亮点在于,是根据一致性hash实现的 分布式缓存 ,能提供更大的缓存量,且支持singleflight,LRU,热点数据备份的特性

















 201
201

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









