







Adversarial Attack on Deep Cross-Modal Hamming Retrieval ICCV-2021
1 Introduction
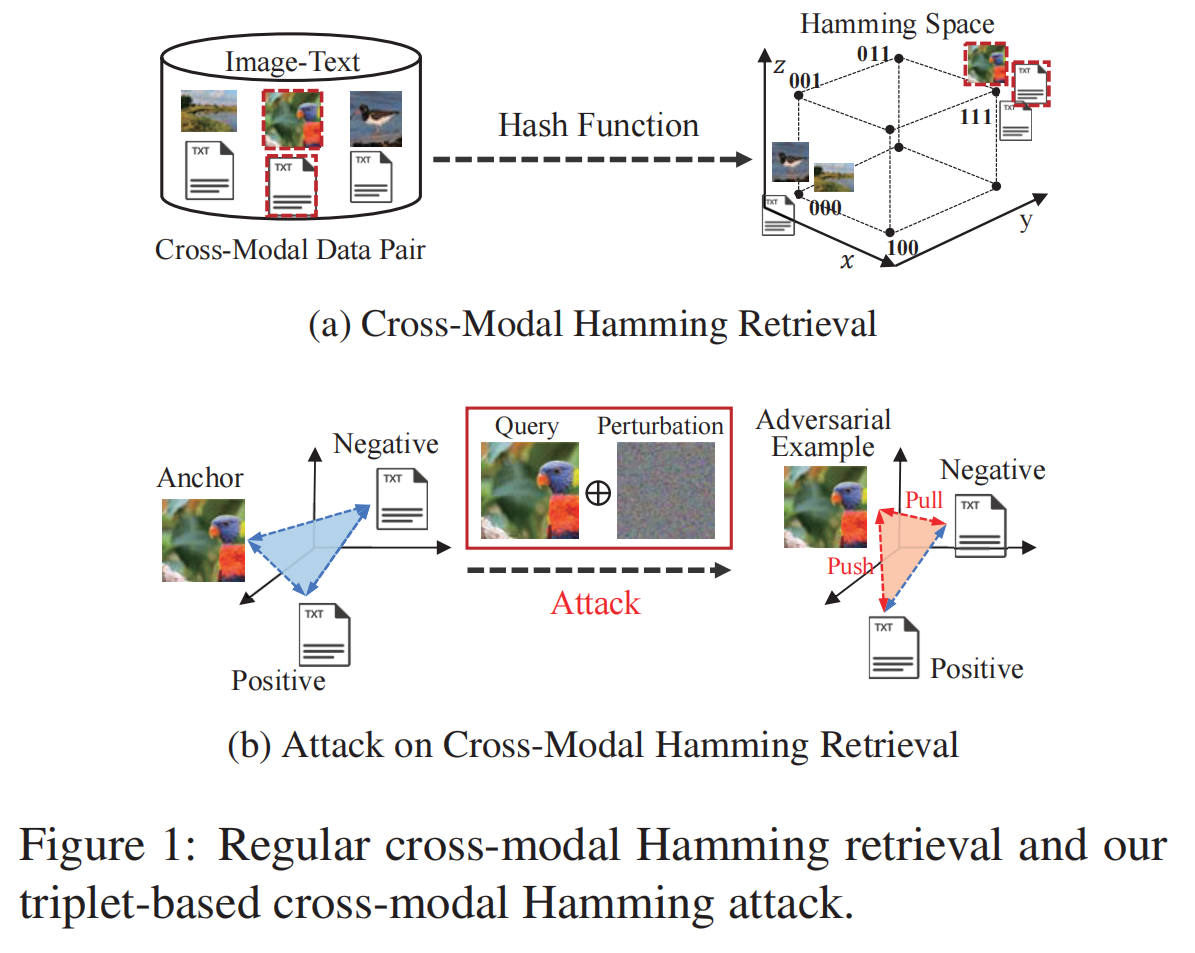
近来,汉明空间的跨模态检索(Cross Modal Hamming Retrieval,CMHR)又到越来越多的关注,这主要得益于深度神经网络出色的表示能力。另一方面,深度网络的脆弱性使深度跨模态检索系统暴露于各种安全风险之下。然而,攻击深度跨模态汉明检索仍未得到充分的探索。所以本文中提出了一种有效的对深度交叉模态汉明检索的对抗性攻击(Adversarial Attack on Deep Cross-Modal Hamming Retrieval,AACH),它在黑盒设置中欺骗了目标深度CMHR模型。具体来说,给定一个目标模型,首先构造它的替代模型来利用汉明空间内的跨模态相关性,通过从目标模型中有限查询来创建对抗的例子。此外,为了提高对抗性攻击的效率,本文设计了一个三重构造模块来利用跨模态的正负实例。通过这种方式,可以通过将扰动实例拉离正实例而推向负实例来欺骗目标模型。
2 Method
常规的跨模态检索任务是尽量使得一个实例与正样本的距离更小,和负样本的距离更大:

而对于跨模态汉明攻击任务而言,其谜底是学习跨模态对抗扰动 δ v \delta^v δv来欺骗目标网络:

2.1 AACH
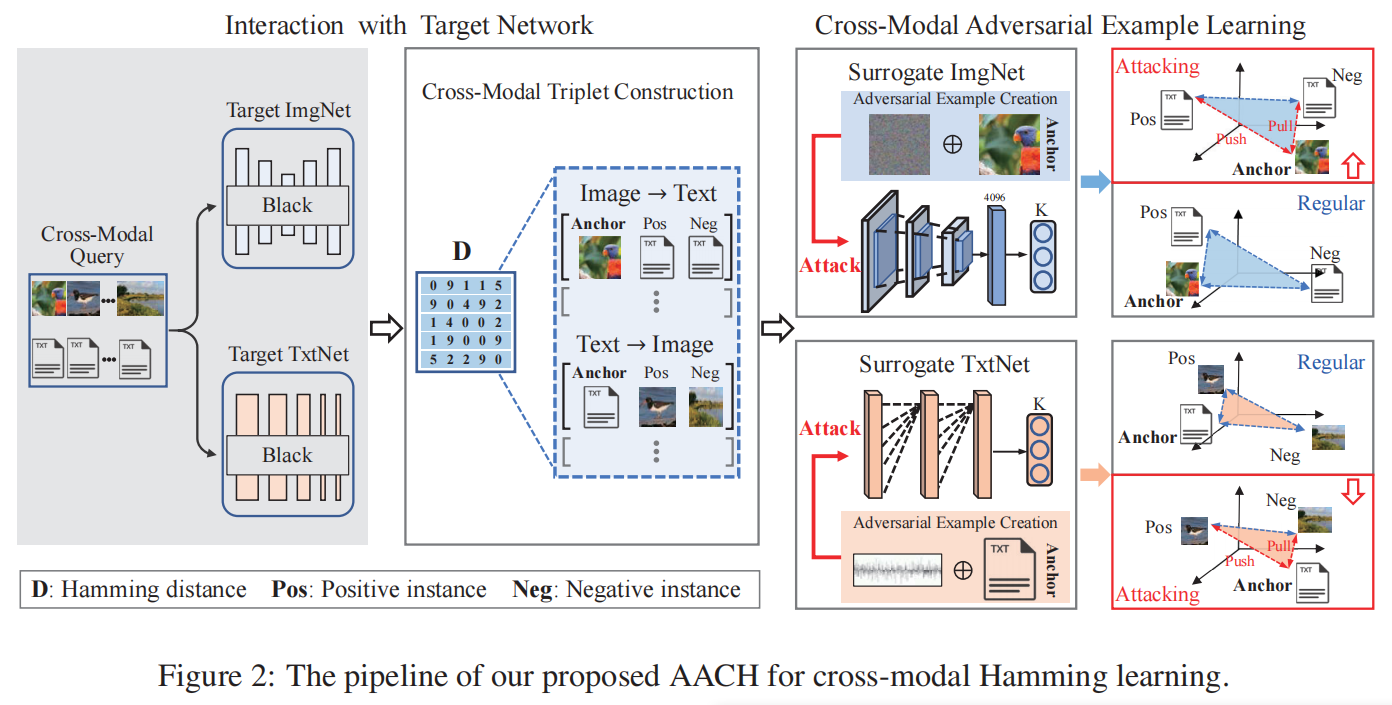
在黑盒攻击中,通常只能利用输入的M个数据对 { o v , o t } M \{o^v,o^t\}^M {ov,ot}M与目标玩过进行交互,M往往是被严格限制的。然后使用二进制编码 { B v , B t } \{B^v,B^t\} {Bv,Bt}来计算汉明距离 D ( B v , B t ) D(B^v,B^t) D(Bv,Bt)。
随后选择单个模态的实例 o A v ( o A t ) o_A^v(o_A^t) oAv(oAt)最为锚点来分别选择对应的另一模态具有更小距离的正实例 o P t ( o P v ) o_P^t(o_P^v) oPt(oPv),和具有更大距离的负实例 o N t ( o N v ) o_N^t(o_N^v) oNt(oNv),构造出了跨模态三元组 { o A v , o P t , o N t } ( { o A t , o P v , o N v } ) \{o_A^v,o_P^t,o_N^t\}(\{o_A^t,o_P^v,o_N^v\}) {oAv,oPt,oNt}({oAt,oPv,oNv}),将用来训练代理跨模态网络来学习跨模态对抗样例。
以图像-查询-文本任务为例,为了训练代理的深度跨模态网络,本文设计了如下三元组损失:

还有量化损失:

所以 ,
, 。
。
在训练了代理深度跨模态网络后,开始创建跨模态对抗性的例子。同样,以图像查询文本任务为例,希望设计对抗图像样例
o
A
v
^
\hat{o_A^v}
oAv^来学习扰动
δ
v
\delta^v
δv加到原图片上:
o
A
v
^
=
o
A
v
+
δ
v
\hat{o_A^v}=o_A^v+\delta^v
oAv^=oAv+δv。此对抗样例应该远离正文本实例,但接近负文本实例:
量化损失:
所以学习对抗样本的损失为: ,
, 。
。
为了优化AACH,首先从目标模型中获得查询的二进制码,并构造跨模态三元组。然后对代理深度网络进行优化如下:

最后,将 θ s u r v , θ s u r t \theta_{sur}^v,\theta_{sur}^t θsurv,θsurt固定,学习跨模态对抗性扰动,如下所示:

3 Conclusion
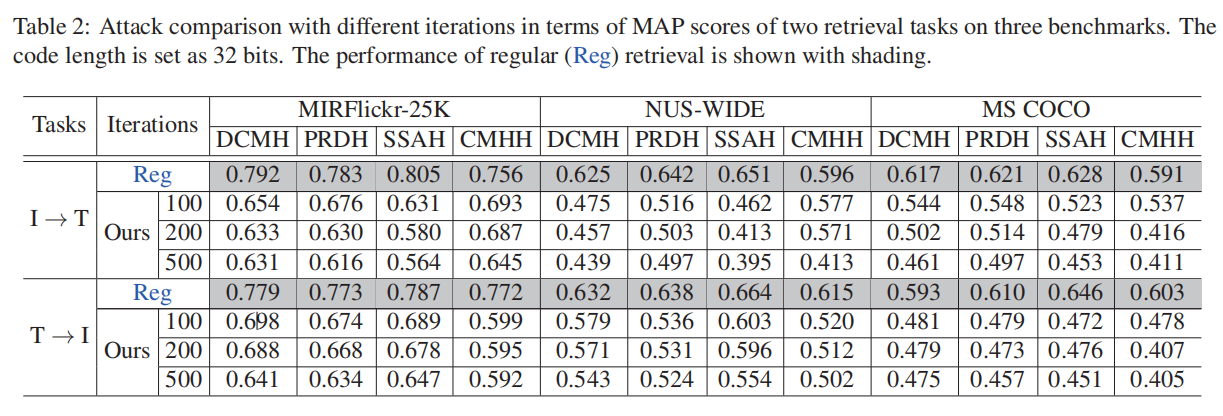
本文提出的AACH通过查询目标网络来构建一个代理模型与目标网络交互,而不需要任何关于目标网络的先验知识。在某种程度上,与最先进的方法相比,AACH在现实应用中更实用。此外,本文提出了一种新的三元组构造模块来,提高了负实例的学习效率,比较有现实意义。















 7673
7673











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









