







本文研究了对抗扰动在不同模式下的可迁移性,即利用白盒图像模型上生成的对抗扰动来攻击黑盒模型。具体来说,由于观察到图像和视频帧之间的低级特征空间相似,本文提出了一种简单而有效的跨模态攻击方法,称为图像到视频攻击(I2V),I2V通过最小化来自对抗性和良性样本的预训练图像模型的特征之间的余弦相似性来生成对抗帧,然后结合生成的对抗帧对视频识别模型执行黑盒攻击。本文实验结果也证明了跨模态对抗攻击的可行性。
由于没有用于生成视频对抗样本的白盒视频模型,在将图像模型上生成的对抗性扰动转换为攻击视频模型时,有两个主要障碍:
- 首先:除了图像和视频数据之间的域间隙之外,视频数据还包含额外的时间信息,这导致图像模型和视频模型之间的学习特征存在差异,这种差异使得很难将对抗性的干扰从图像传输到视频
- 第二,现有的基于同态模型(如图像模型)的传输攻击不适用于跨模式攻击场景。与现有的基于传输的图像攻击不同,在对抗扰动生成过程中,图像标签可用于优化特定于任务的损失函数(例如,交叉熵损失),在跨模式图像到视频攻击中,视频帧没有标签可用。
主要贡献:
- 我们研究了对抗性扰动在图像模型和视频模型之间的可传递性。特别地,我们提出了一种I2V攻击,以提高图像模型生成的视频对抗样本在不同视频识别模型之间的可传输性。据我们所知,这是针对视频识别模型的基于跨模式传输的黑盒攻击的首次工作。
- 我们对图像和视频模型之间的特征映射的相关性进行了深入分析。基于这一观察,I2V在图像模型的扰动特征图上优化对抗帧,以提高不同视频识别模型之间的可转移性。
- 我们使用六个视频识别模型进行了实证评估,这些模型是用Kinetic-400数据集和UCF-101数据集训练的。大量实验表明,我们提出的I2V有助于提高从图像模型生成的视频对抗示例的可传输性。
方法:
g:ImageNet预处理图像模型
f:视频识别模型
f(x):输入视频的视频识别模型的预测
I2V旨在通过g生成对抗样本,该样本可以在不了解f的情况下,将视频模型f愚弄为
在白盒设置中,无目标对抗攻击的目标的可以表示为:
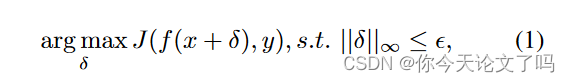
J:视频模型f的损失函数
在本文中,对手无法访问有关视频模型的知识,I2V利用了从图像模型生成的对抗样本来在黑盒模型中攻击视频模型。
视频模型与图像模型的相关性分析:
利用余弦相似性分析图像模型和视频模型之间的良性帧和对抗帧的中间特征的相似性,从良性样本和对抗样本中获得的余弦相似性非常相似。
I2V攻击:
流程:
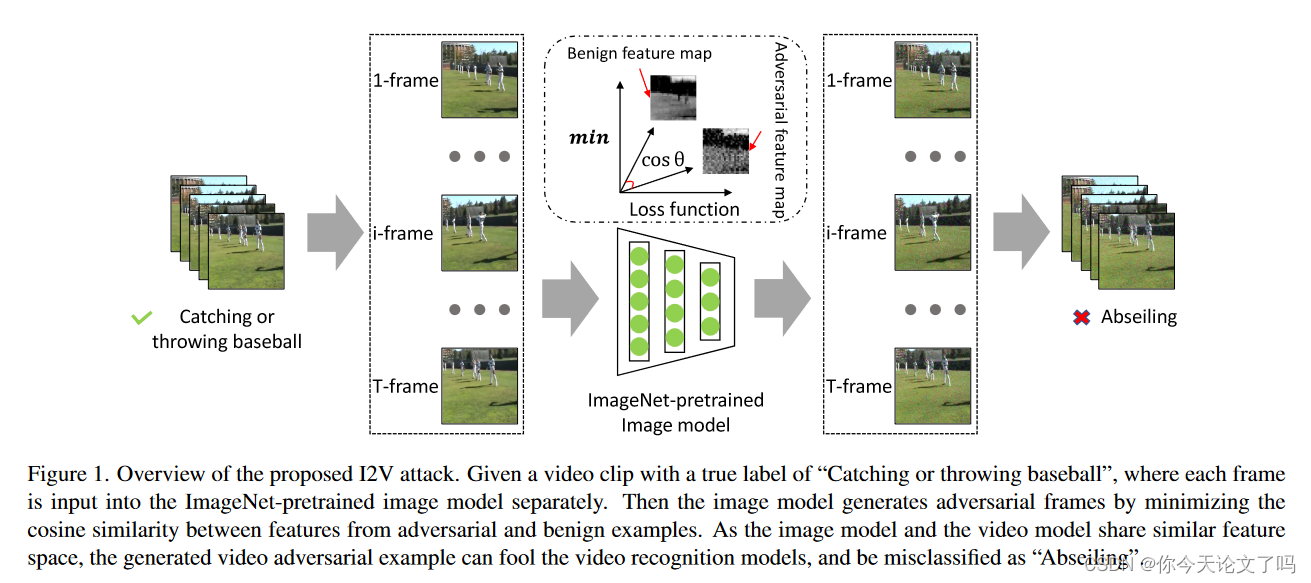
本文提出了图像到视频(I2V)攻击,该攻击从ImageNet预处理图像模型生成视频对抗示例,以提高异构模式模型和黑盒环境中攻击视频模型的可移植性。通过扰动图像模型的中间特征,I2V生成对抗样本,以高概率扰动黑盒视频模型的中间特性。
I2V通过以下方式优化第i个对抗帧:
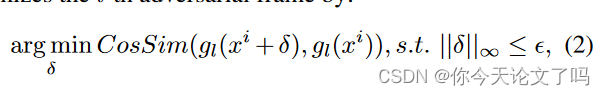
:图像模型中第l层相对于
的中间特征图
:x中的第i帧
CosSim函数计算之间的余弦相似性。
如果是倒数第二层的输出,
表示分类层的权重,因此
具有高度一致性来进行真实预测。
通过最小化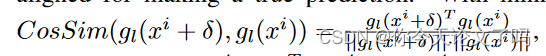
如果 具有单位长度,那么就可以得到最小化
![]()
由于之间具有高度一致性,余弦相似性的最小化导致
的值大大降低,从而使的g预测错误。
整个算法的流程可以理解为:
用一个较小的常量0.01/255 初始化对抗扰动----->Adam优化器求解公式(2)更新
------->
将投影到
附近-------->将所有生成的对抗帧
合并为视频对抗样本

攻击集合模型ENS-I2V攻击
使用多个ImageNet预处理图像模型来执行名为ENS-I2V攻击,该攻击通过以下方式优化第i个对抗帧
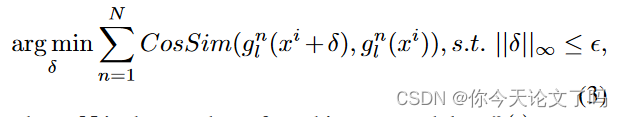
ENS-I2V生成的对抗帧的中间特征与良性示例的特征集合正交,因此ENSI2V允许生成高度可转移的对抗示例

















 269
269

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









