







先说一下结论:哪个索引区分度大,筛选更快就使用哪个
验证一下
来一张测试表
建表语句
CREATE TABLE `a` (
`id` int(255) DEFAULT NULL,
`index1` varchar(255) DEFAULT NULL,
`index2` varchar(255) DEFAULT NULL,
KEY `index1` (`index1`),
KEY `index2` (`index2`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
-- ----------------------------
-- Records of a
-- ----------------------------
INSERT INTO `a` VALUES ('1', 'aaa', 'ddd');
INSERT INTO `a` VALUES ('1', 'a', 'ddd');
INSERT INTO `a` VALUES ('0', 'aaa', 'dd');
INSERT INTO `a` VALUES ('0', 'aaa', 'ddd');
INSERT INTO `a` VALUES ('1', 'aa', 'ddd');
INSERT INTO `a` VALUES ('1', 'aa', 'dd');现在测试一下sql语句
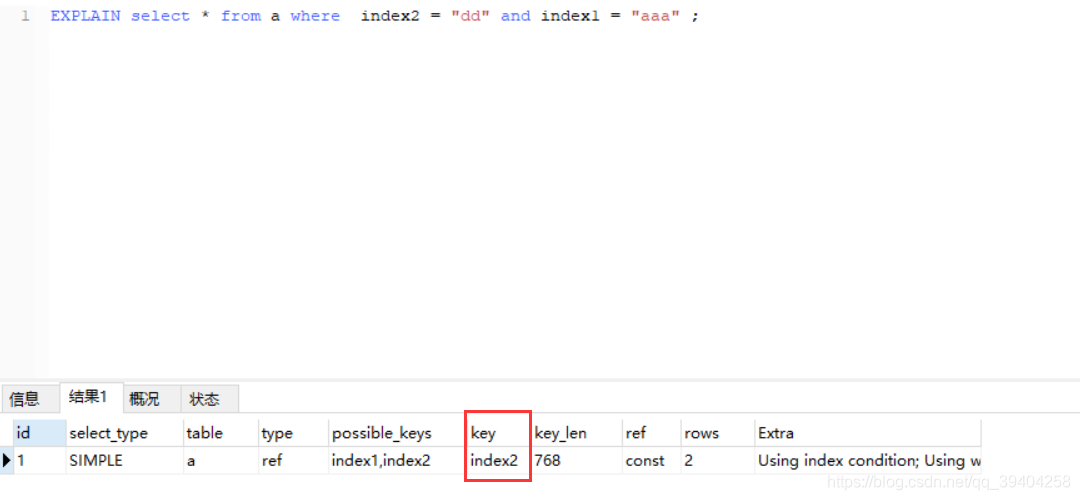
测试1:EXPLAIN select * from a where index2 = "dd" and index1 = "aaa" ;
结果:使用的是index2索引
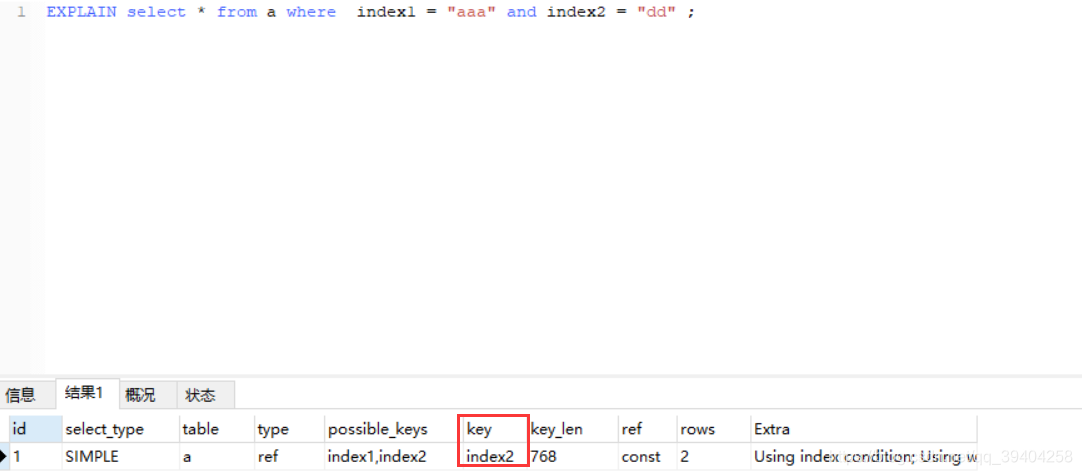
测试2:将查询条件的顺序换一下
EXPLAIN select * from a where index2 = "dd" and index1 = "aaa" ;
结果:还是使用的是index2索引
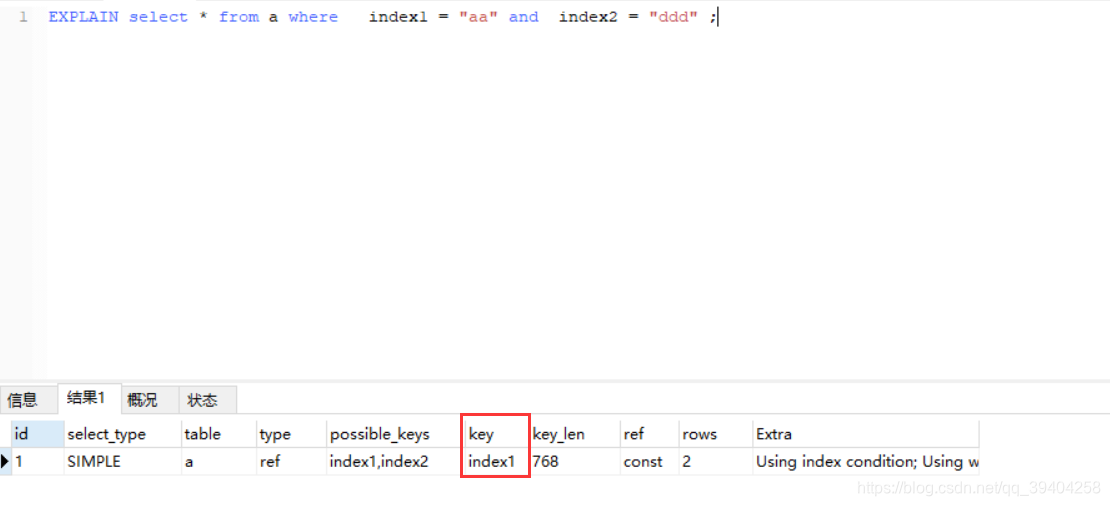
接着我们看测试3:EXPLAIN select * from a where index1 = "aa" and index2 = "ddd" ;
结果:发现使用的是index1索引,我换了一下条件内容怎么就变成index1索引了
接着我们看测试4,将查询条件顺序换一下:EXPLAIN select * from a where index2 = "ddd" and index1 = "aa" ;
结果:发现还是使用的是index1索引

那么mysql到底怎么选该使用哪个索引呢?
我们看一下表里的数据,测试1和2的sql查询的是 index2 = "dd" and index1 = "aaa"
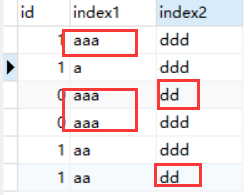
表里面只有两个index2=dd的数据,而index1=aaa的数据有三个,使用index2索引会直接将表里的数据筛选剩2个,而index1索引会将表里的数据谁选到3个。
这样看哪个索引区分度大,筛选更快就使用哪个。
我们再看测试3和4,index1 = "aa" and index2 = "ddd"
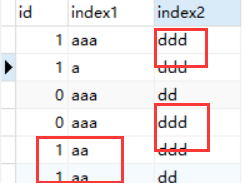
aa有两个,而ddd有四个,所有使用index1索引。
而当数据量相同时,按表中顺序使用第一个索引

















 1190
1190

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









