







原理
1.K邻近分类法(KNN)
2.用稠密SIFT作为图像特征
3.手势识别
1.K邻近分类法(KNN)
KNN算法我们主要要考虑三个重要的要素 k值的选取,距离度量的方式和分类决策规则。
对于分类决策规则,一般都是使用前面提到的多数表决法。所以我们重点是关注与k值的选择和距离的度量方式。
对于k值的选择,没有一个固定的经验,一般根据样本的分布,选择一个较小的值,可以通过交叉验证选择一个合适的k值。
选择较小的k值,就相当于用较小的领域中的训练实例进行预测,训练误差会减小,只有与输入实例较近或相似的训练实例才会对预测结果起作用,与此同时带来的问题是泛化误差会增大,换句话说,K值的减小就意味着整体模型变得复杂,容易发生过拟合;
选择较大的k值,就相当于用较大领域中的训练实例进行预测,其优点是可以减少泛化误差,但缺点是训练误差会增大。这时候,与输入实例较远(不相似的)训练实例也会对预测器作用,使预测发生错误,且K值的增大就意味着整体的模型变得简单。
。
对于距离的度量,我们有很多的距离度量方式,但是最常用的是欧式距离,即对于两个n维向量x和y,两者的欧式距离定义为: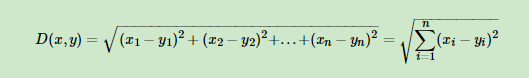
大多数情况下,欧式距离可以满足我们的需求,我们不需要再去操心距离的度量。
2.用稠密SIFT作为图像特征
参考博客:https://blog.csdn.net/langb2014/article/details/48738669
https://blog.csdn.net/weixin_43843780
dense sift即直接指定关键点位置和描述子采样区域,计算sift特征。
主要过程是:
1,用一个patch在图像上以一定步长step滑动,代码中step=1,这个patch就是描述子采样区域,patch size是4bins4bins,bin size可以自己指定,代码中是3pixels3pixels。这里说的bin对应到《sift特征提取》中的第4步就是指子区域area。图中的bounding box是sift特征点的范围。
2,计算每个像素点的梯度(同sparse sift),统计每个bin内的像素点在8个方向上的梯度直方图,这样就生成了448维的sift特征。
3.手势识别

实验代码和实现
1.K邻近分类法(KNN)
2.用稠密SIFT作为图像特征
3.手势识别















 2213
2213











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









