







1 设置测试数据集
df_test = pd.DataFrame({
'sex':['man','man','woman','man','woman','man'],
'name':['Alice','Bob','Cindy','Eric','Helen','Grace '],
'where':['bj','bj','sh','bj','cd','cd'],
'play':['game','game','ball','game','game','ball']
})
df_test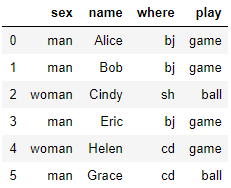
2 方法
2.1 Label encoding
将列中每种取值对应成一个数字,有多少种取值就有多少种数字
缺点:会出现等级差,比如 1<3
from sklearn.preprocessing import LabelEncoder
X = df_test.copy()
label = LabelEncoder()
for c in X.columns:
if (X[c].dtype == 'object'):
X[c]=label.fit_transform(X[c])
X
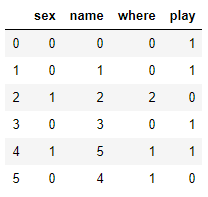
2.2 One Hot Encoder
将分类特征的每个元素转化为一个可以用来计算的值
优点:解决2.1问题
缺点:出现稀疏矩阵
from sklearn.preprocessing import OneHotEncoder
X = df_test.copy()
one=OneHotEncoder()
one.fit(X)
X = one.transform(X)
print(X.toarray())

2.3 get_dummies
将每列的所有属性取值设成一列,取0或1
优点:解决2.1问题,效果通2.2,但代码简单
缺点:出现稀疏矩阵
X = df_test.copy()
X = pd.get_dummies(X)
X
2.4 FeatureHasher
X = df_test.copy()
for c in X.columns:
X[c] = X[c].astype('str')
hashing = FeatureHasher(input_type='string')
X = hashing.transform(X.values)
X.data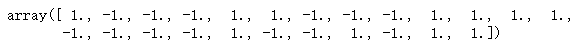















 3482
3482











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









