







目录
机器学习是什么?
区分人工智能,机器学习,深度学习三个概念
人工智能:机器-人类智能
机器学习:从数据中找规律(可否用曲线拟合做类比?)
深度学习:机器学习中利用某种算法的一个分支,算法为神经网络
由于深度学习性能太好,秒掉了机器学习中的传统算法,机器学习基本被“一统天下”,所以有时候用深度学习代指机器学习
理解:机器学习是一种算法,人工智能是一门学科,机器学习可作为一种算法解决人工智能领域的问题。
人工智能应用领域
计算机视觉(Computer Vision,CV):计算机视觉
自然语言处理(Natural Language Processing,NLP):计算机拥有语言能力
推荐系统(Recommender System,RS):计算机精确分析人的爱好
机器学习怎么学
- 学的时候可以看懂推导过程即可
- 调scikit-learn库即可,不用自行实现
西瓜书+南瓜书第一章:绪论
基本术语
(之前看到那些术语感觉好高级,现在终于懂了)
- 第一组术语:训练,训练样本,训练集,属性,标记
(特征1,特征2,特征3,...,结果)组成一个训练样本,所有训练样本的集合称为训练集,基于训练集进行规律的寻找(也可称之为模型建立)成为训练。
(特征1,特征2,特征3)称为属性,结果称为标记
- 第二组术语:测试,测试样本,测试集,预测
(特征1,特征2,特征3,...,结果)组成一个测试样本,所有测试样本的集合称为测试集。测试集是用来检查训练效果的。
若某样本只有(特征1,特征2,....),无结果,则可基于训练出的模型对该未知结果的样本进行预测。
理解:训练集和测试集都是已知全部信息的,训练过程试图建立一个从样本的结果的合理映射。训练得好——>泛化能力强
第三组术语:分类,回归
样本值离散:分类。当分类只有两类时,称为“二分类”,称1个为正类,1个为反类
样本值连续:回归
第四组术语:无监督学习,有监督学习
无监督学习:无标记,分类预先未知。代表:聚类
有监督学习:有标记,分类预先已知。代表:分类,回归
第五组术语:模型,假设空间,版本空间,算法

算法:方法(决策树,线性回归....)
模型:函数或抽象函数——>更广泛地说,模型是从输入空间到输出空间的映射
第六组术语:阈值
通过模型运算得出的结果为数字,通过阈值设定输出判断结果
归纳偏好
如果没有归纳偏好,可能出现多个一样好的模型
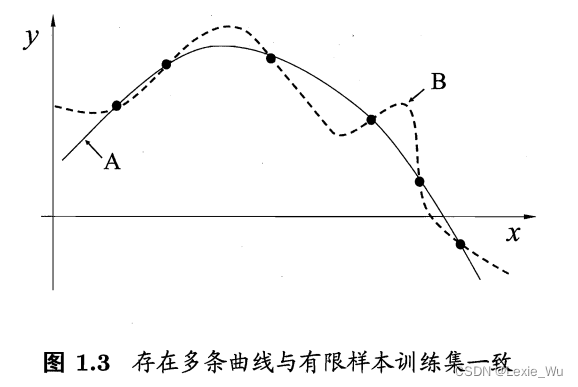
比如在这个图中,要让曲线穿过样本点,如果没有限制,对于计算机来说A,B一样好,但如果有“平滑”的归纳偏好,则显然A更好。
经过推导,我们可以发现,误差与总学习算法无关
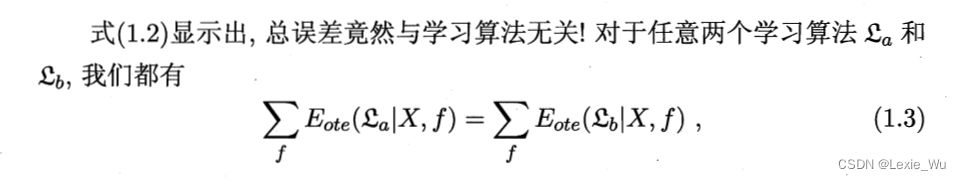
推导:
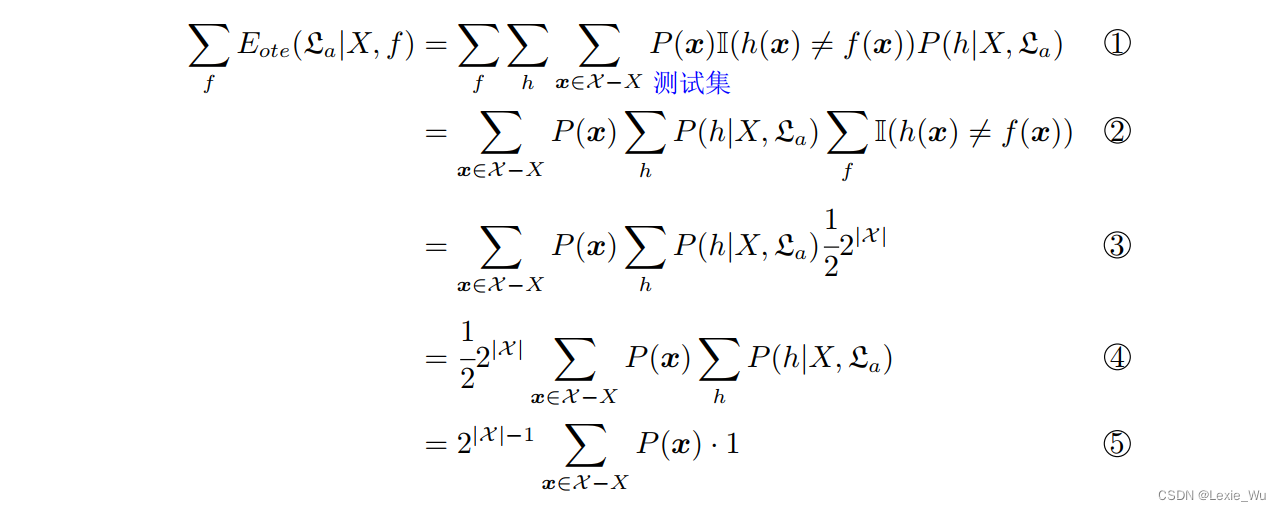
推导的关键:


注意:实际情况是高度拟合数据的函数才是真实目标函数,上述那种4种等概的真实函数是不可能的
理解:归纳偏好决定了一个算法的好坏(对于使用者而言),偏好包括两个维度,一是使用者自己设定的偏好(曲线平滑或不平滑等),另一方面是提供的数据本身有偏好
实际训练中:哪个算法训出来的模型在测试集上表现好,哪个算法就牛逼
疑问:同一类问题的最优算法可能不一致?与提供的数据集有关?
训练完整过程

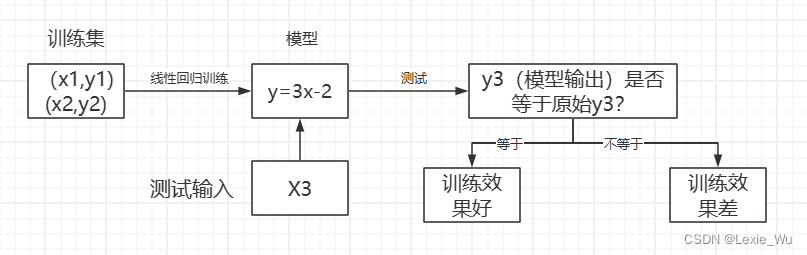
一个重要思想:数据决定模型上限,算法让模型逼近上限
西瓜书+南瓜书第二章:模型评估与选择
过拟合与欠拟合
欠拟合:没找到一般性质——>由于学习能力低下导致
过拟合:把个体特征当成一般性质,泛化能力差——>机器学习的关键障碍,无法避免,只能缓解
一个生动的例子:
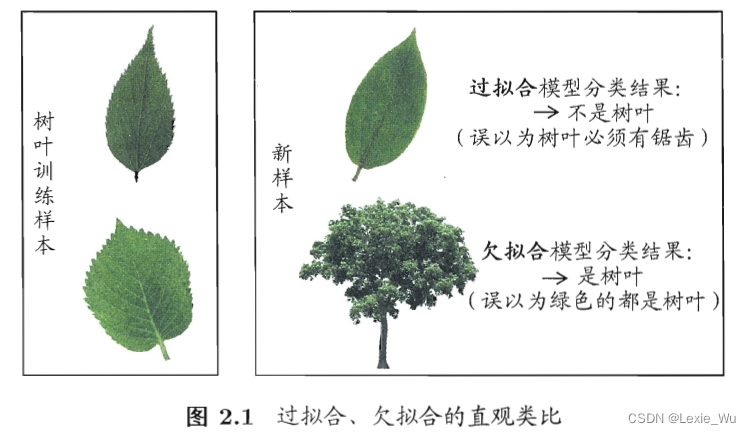
评估方法
1. 留出法:把数据集D划成两个数据集合。
- 不同留出方式可能导致训练结果不同,所以往往进行多次随机留出。
- 每次样本划分比例需一致,以免因数据划分导致额外误差
2. 交叉验证法:把数据集D划分成k个互斥集合,每次取一个集合作为测试集,其他k-1个集合作为训练集。也称为”k折交叉验证“。k一般取10,也常取5,20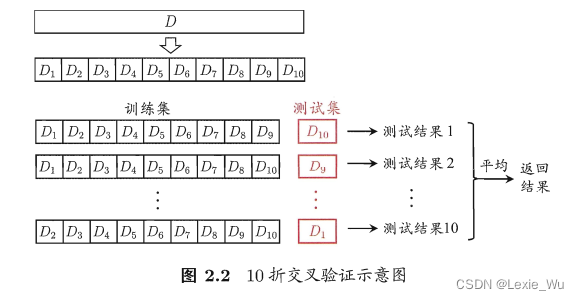
若k等于样本数量——>留一法:数据量大不实用
3. 自助法:通过多次放回采样,从来没被采到的则作为测试集,m次采样中,样本始终不被采到的概率。即约有1/3的数据用于测试
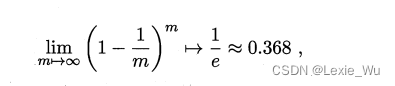
4.调参:每个参数设定范围和变化步长。分为两步,第一步:调参,将数据分为训练集和验证集,用于设定参数。第二步:训练,将全部数据用于训练,得到模型。
性能度量
- 回归任务:均方误差

- 分类任务:
- 错误率和精度

- 查全率和查准率:
查全率:尽量找出所有好西瓜
查准率:好西瓜占比尽量大
-

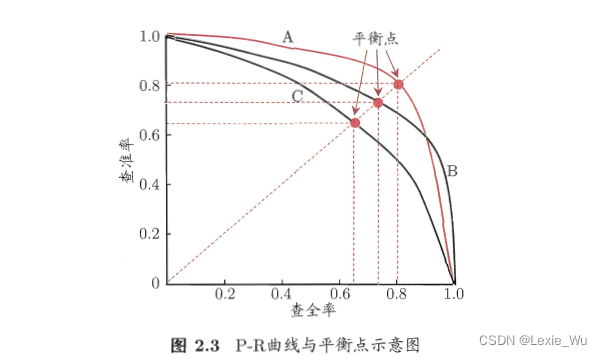
有交叉不方便比较优劣,通过平衡值(BEP),即查全率等于查重率时的值或 度量
若有n个矩阵算查全率和查准率(多个数据集/多次训练)
宏查x率:各矩阵P,R和取平均
微查x率/微 :先把各矩阵对应项加起来再取平均
- ROC与AUC:
ROC:排序后找截断点划分正例反例
AUC:ROC面积,反映排序质量 - 代价曲线:对损失敏感
比较检验
核心:假设检验
应用:单学习器的泛化性能检验—>t检验
双学习器的比较检验——>5x2交叉验证,McNemar检验(卡方分布)
多学习器的比较检验——>Step1:Friedman检验平均序值(检验算法是否性能相同)
Step2:Nemenyi检验两个算法是否有显著差别
偏差与方差——解释泛化性能
偏差与方差对学习期望的泛化错误率进行拆解
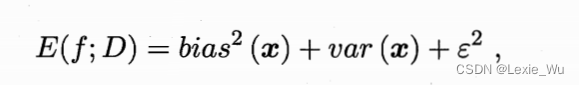
重要理解:


偏差:算法拟合能力,方差:数据扰动(算法鲁棒性?),噪声:任务难度
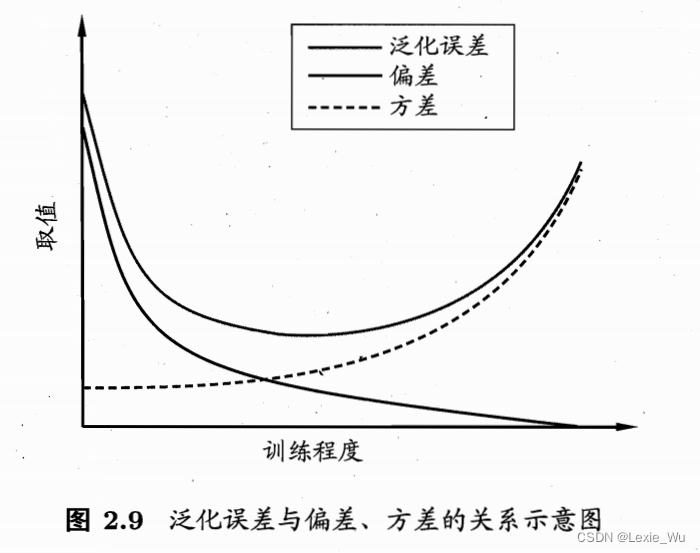
欠拟合:偏差主导,过拟合:方差主导
心得
1-2章主要是机器学习的基本概念,完成了整个流程的术语描述。从训练——预测——性能评估三个环节进行了大致的描述,估计后面几章会开始学习不同的算法走这套流程















 275
275











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









