







2021/8/23 写在前面
若你的应用场景里,对象分布比较稀疏,即不易出现相互重叠率高/拥挤的情况,那么请跳过这里,直接从分割线后看,按本篇 tf1.0.5+keras2.1.6 配置即可 ( •̀ ω •́ )y
若存在拥挤检测,则请看一下下面这段:
拥挤检测可能需要将 nms 改进为 soft-nms
本篇只是使用 tf1.0.5 + keras2.1.6 组合成功运行 maskrcnn 源码(源码本身使用 tf1.x 方法实现)
若需要改用 soft-nms,则需要使用 tf1.15 及以后版本中封装的方法tf.image.non_max_suppression_with_scores,亲测可用组合为 tf2.2.0 + keras2.3.0
因此有需要的朋友,可结合本篇与后来的 tf2.x记录
cpu上使用区别在于tf、keras版本、源码修改部份(tf1.x与2.x在方法上存在差异);
gpu上使用的区别更大,在上面这些修改基础上,还需要改用cuda10.1.243+cudnn7.6.5配置,且安装包是tensorflow-gpu
所以如果使用场景有区别,最好一开始就确认需要的组合,否则后期就 很麻烦orz
总之 祝你顺利 ( •̀ ω •́ )y
关于soft-nms的一点简单介绍
nms为非极大值抑制,当多个候选框存在相互重叠超过一定阈值时,nms原做法是只保留置信度最高的一个框,因此在对象拥挤的时候容易出现漏检
soft-nms的做法更为柔和,降低重叠率高的框的置信度,更适用拥挤场合
以下是tf1.0.5+keras2.1.6 运行源码的记录
这里主要记录最近自己使用maskrcnn训练、检测实例分割的一些内容,可能不是很清晰,如果有需要的可以直接留言补充,互相学习:)
简单梳理一下,Mask_RCNN文件夹下的mrcnn为主要的内容,实际调用的例子在sample文件夹下,直接使用如coco文件夹下的coco.py进行相应修改,即可进行自己需要的训练、检测。
下面是第一次尝试训练成功的记录
1、使用conda创建python3.6环境
最推荐最推荐!使用conda环境
创建python3.6环境,并激活进入环境,接下来的所有动作都是在环境中进行的。
2、使用tensorflow1.5.0、keras2.1.6包
tensorflow(后面简称tf)、keras包之间有版本相关性,具体版本相互对应可以参见一些列举了各个版本关系的整理博文。
这里用的是tf1.5.0+keras2.1.6,绝对稳定且适配,亲测最推荐的组合qwq
tf1.5.0+keras2.1.6组合没有出现任何与kerasAPI相关的错误。之前也有尝试过其他组合,但多少都出现了奇怪的报错提示,查找方法也多是建议修改tf版本,那keras版本也要进行相应修改。最后兜兜转转回到了1.5.0+2.1.6组合。
安装来源:
tf:
pip install不可行,目前下载提示只能安装2.*,需要自己前往网页下载,指路:
https://pypi.org/project/tensorflow/1.5.0/#files
网址上修改版本1.5.0为其他版本号即刻前往不同版本,tensorflow改为tensorflow-gpu即刻前往下载gpu版本。
下载时注意环境的python版本、平台版本,如这里需要的是python3.6、windows上的版本,点击即可下载whl文件。
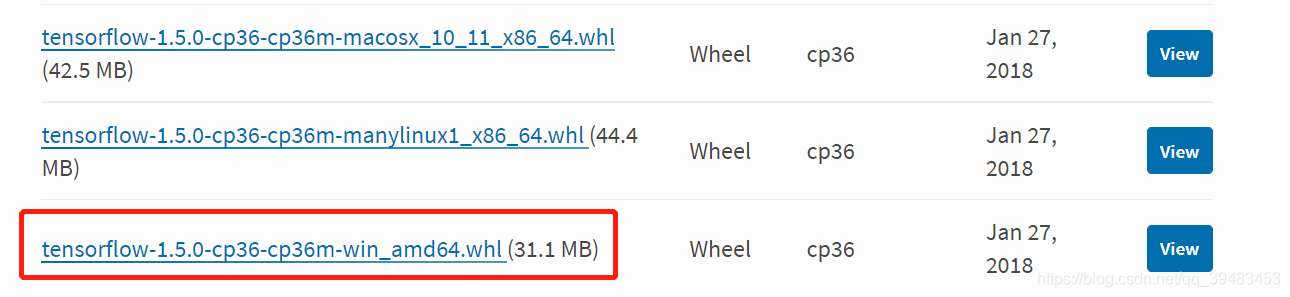
下载好后运行如下命令即可完成 tf1.5.0 安装。
pip install whl文件存放路径
keras:
pip install keras==2.1.6
3、准备数据集
⚠ 这里可能很多人会不一样,尤其是训练的文件夹结构,根据自己的代码安排路径即可
这里使用的是labelme进行的数据集图片标注,得到原图片文件、与原图片同名的标注json文件
lebelme版本4.5.9
在Mask_RCNN文件夹下创建datasets文件夹,在datasets下面再创建train文件夹放训练集文件,val文件夹放验证集文件。
将标注结果的原图、json图片分为两类:做训练的、做验证的,比例可以自己来定,一般做训练占多数。
做训练的放入datasets/train文件夹下,做验证的放入datasets/val文件夹下即可,训练数据集准备完成。
注意点:
1、json文件中的imagePath项内容最好全部写作:图片名称+后缀
也就是说不要保留路径,或者路径中绝对不要出现中文与返回上级目录的相对路径写法../,否则读取时报错
2、json中imagePath的后缀,注意与图片对应(.jpg/.JPG/.png)
3、如果图片大小过大,需要等比例缩放图片+json里记录的坐标。
否则如4000*6000这样过大的图片在读入时会报错,建议统一宽度为1080,高度等比缩放,json中所有(点坐标、图片信息、图片高度、宽度等)都要修改
4、注意检查点标注是否有超出图像像素范围的。
这里不知道前面人在做标注时出了什么情况,有这种问题,超出边界有1像素~30像素不等。将超出数值统一为边界值后再使用labelme查看框明显变形且偏移,所以舍弃了这部分
5、注意是否有点数=1的框,可能是标注时的错误,需要舍弃
中途有查到另一种训练集制备方法,提到了四个文件夹结构,如果这里提出的这种方法不适合的话可能那种会是适合的。
指个路:mask rcnn训练自己的数据集
4、准备coco权重文件(可选)
这一步也可以不做准备,第五步尝试训练时可以直接实从网络上进行下载。
文件名为mask_rcnn_coco.h5
权重文件名均以.h5为后缀,自己训练生成的权重文件也会是.h5后缀。
该权重文件下载可前往各处获取,原作者也有给出,另外还有针对balloon等的权重文件。
获取后放在Mask_RCNN目录下即可
5、尝试训练
5.1、主代码文件修改,如balloon.py
各个路径修改“
- 根目录路径(即Mask_RCNN目录路径,可以使用从当前文件开始的相对路径)
- 权重文件路径
- log文件夹路径(可能需要自己创建在Mask_RCNN目录下)
重写的Config类内,如balloon.py中的BalloonConfig类:
-
NAME修改;
-
NUM_CLASSES修改为目标检测种类数量+背景1类,如这里只检测一类物品,就设为 1+1
Dataset类是继承utils而来,需要修改load_shape(这里方法名可能不一样,如balloon.py中是load_balloon方法)里的self.add_class,改为自己需要检测的种类。(这里不需要背景类background)
5.2、运行、可能存在的报错的处理方法
根据如下命令,按需修改中文文本部分为个人需要即可运行
python 你的主文件.py train --dataset=前面创建的datasets文件夹路径 --weights=coco
命令解读:
python 文件.py时运行指定文件,如气球的测试样例那就是python balloon.py,这个大家肯定都知道 : )
train是指定当前为训练模式,具体的前往查看代码过程就很清楚了;
–datasets是指定存放了训练集、验证集图片文件的目录位置;
–weight为权重文件,可以直接改为权重文件位置或 last,训练时会对权重文件进行修正,得到新的权重文件存放在log目录下。
像此处指定为coco,代码中也指定了一个coco所在的文件路径,若此处没有权重文件,就会根据传入的是coco而直接从网上进行权重文件下载,一般挺快的,所以第四步不做准备也是可以的。
指定为 last 适用于以前进行过训练且想要在此基础上进行训练的情况。
5.2.1、若提示无法找到 mrcnn
mrcnn是在Mask_RCNN文件夹下自带的,并不需要pip Install mrcnn,若已经运行了pip install的可以直接使用pip uninstall mrcnn来卸载。
在代码最前面引入包的地方加入如下代码进行mrcnn目录的引入:
import sys
sys.path.append("这里需要改成你的Mask_RCNN目录路径")
如,这里是在win10下的路径,linux上从/home开始即可:
import sys
sys.path.append(“F:\pig\code\Mask_RCNN”)
5.2.2、其他的包引入问题
根据提示进行相应的pip install即可
特殊一个提示skimage的,需要使用如下命令,且需要0.16.2版本,否则训练过程会出现如https://blog.csdn.net/qq_39483453/article/details/118598535?spm=1001.2014.3001.5501这样的报错。
pip install scikit-image==0.16.2
这里特意将mrcnn的报错写在前面,避免大家多走一步没用的owo
5.2.3、提示一个说str类型没有decode('utf-8)相关的错误
根据错误提示的decode所在语句位置,在decode('utf-8)前面加上.encode(‘utf-8’),即改为.encode(‘utf-8’).decode(‘utf8’)即可。
印象里就topology.py文件里的3个地方需要修改,也可以直接运行、报错、ctrl+点击报错位置、加上encode即可。
6、win10上运行训练可能会在Epoch 1/这一出输出卡住一会儿,稍微等待即可。keras2.1.6不会出现持续卡住的情况,请放心。
7、Ubuntu18.04、16.04服务器上想要运行gpu版本
强烈强烈建议直接搞一个带显卡驱动、cuda9.0配driver384以上(这里用了440.64.00)配cucnn7.0.5的操作系统组合进行
这里有一堆的版本对应关系qwq
tf1.5.0/tf-gpu1.5.0+keras2.1.6需要cuda9,cuda9需要cucnn7+gcc4.8,cuda9只支持Ubuntu16.04、17.04(但也有说将Ubuntu18.04gcc降为4.8就可以用了)
gcc降级:可以通过版本控制update-alternatives选择gcc4.8为自动模式来实现,指路:https://blog.csdn.net/qq_39483453/article/details/118355784?spm=1001.2014.3001.5501
总之这里最推荐这个组合
8、自测可用的配置
说一下这里成功运行起来的配置:
gpu:Tesla P4
deriver:440.64.00
cuda:9.0.176
cudnn:7.0.5
tf-gpu:1.5.0
keras:2.1.6
以及其他运行提示缺失的包
更多配置GPU运行的记录在另一篇里,关于查看cuda版本的nvcc -V的坑:指路
9、gpu上运行的语句
如:
CUDA_VISIBLE_DEVICES=0 python3 你的文件.py splash --weights=权重文件路径 --image=要检测的图片路径
大致的意思就是:在序号为0的GPU上,指定权重文件与待检测图片路径,以检测模式运行你的文件
开头的CUDA_VISIBLE_DEVICES=0指的是使用GPU序号,这个可以在nvidia-smi命令的输出中看到你的gpu序号,也可以先人为设置序号,这里可以百度相关方法
splash是检测模式,这个根据你的文件里匹配的字符串可以自己更改;如果要训练那就改为train
权重和前面一样可以直接用coco、last这样的,也可以指定权重h5文件路径
权重文件、图片文件路径都可以使用从运行文件路径的相对路径
其他的问题目前没遇上,之前倒是浪费了很多的时间在tf、keras版本问题、尝试搞gpu运行问题、整理数据集格式按照其他人的教程处理16位->8位代码最后发现原来自己的就是8位,再到现在发现其实只需要原图片+json文件即可,走了一堆弯路。
另外需要注意json文件里的imagePath字段与图片文件名称、后缀一致,之前由于数据标注回收经手了太多人导致当时出现了很多数据集的问题,如前文描述需要多方面检查。
2021/7/20
目前进行了在4核/8核CPU、8gGPU上的训练、检测等
这里再记录一些tips:
1、能搞gpu就搞gpu,gpu处理速度明显快于cpu:
直观对比感受:(4核效率低于8核不做记录)
一个epoch:gpu需要1min40s左右,8核cpu需要1h40min左右
同一张图检测:gpu低于1s,8核cpu需要10s左右
2、实际感受耗时中可能有一大部分花费在加载权重文件上
如果只检测一张图可能感受差异不大,这是由于在检测初始,需要进行权重文件导入消耗较长时间。这里gpu上大概需要60s左右,cpu上速度快一些,导致两边跑出来gpu耗时110s、cpu耗时80s,仿佛cpu来的快。但只要进行实际检测步骤耗时记录就能看出来实际检测速度的差异,在处理多图时更加明显。只有在开始时需要耗时进行权重导入处理第一张图,后续轮询文件夹进行其他图片处理就相当快了。
3、对于遮挡导致目标分割为多块情况的标注方法:
这里的结论是:尽量不要把一个物体分割成多块进行标注,这样会导致各部分被检测为单个物体,导致检测结果中目标物体数目多于实际物体数目
对于遮挡分割为多块的情况,将遮挡物作为目标上可能出现的图案标注在一起来教给模型,测试结果要好于分割开标注教给模型的结果
所以还需要酌情考虑,但一个标准需要遵守:一次学习材料要统一标准,比如统一将遮挡物框入,或统一不框入,或框入哪一类的遮挡,避免歧义
…














 1543
1543











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









