







(本文只为了阅读论文方便,没有其他意思)
1、Introduction
痛点:光谱波段信息冗余和有限的训练样本
1)早期基于光谱尝试:SVM、多项式逻辑回归 multinomial logistic regression、随机或动态子空间。但是相邻像素可能属于同一类别,基于光谱的方法忽略了HSI的高空间相关性和局部一致性。
2)基于光谱空间特征的分类框架越来越多,设计了两种低级特征,形态轮廓和Gabor特征,表示空间信息。提出了SVM + 形态学核 + 复合核方法,但其高度依赖于手工描述。
3)深度学习在自动提取非线性和分层特征方面显示出强大的能力,大量计算机视觉任务收益于DL,并取得了重大突破,比如异常探测、自然语言处理NLP和图像分类Cv。
前人工作: Chen介绍了用于提取有用特征的堆叠式自动编码器(SAE)。
Tao[22]使用两个稀疏SAE分别捕获光谱和空间信息。
Ma等人[23]提出了一种更新的深度自动编码器(DAE)来提取光谱空间特征,并设计了一种新的协同表示来处理小规模训练集。
Zhang等人[24]使用递归自动编码器(RAE)从目标像素的邻域中提取高级特征,并使用新的加权方案来融合空间信息。
在[25]中,Chen等人提出了一种基于深度信念网络(DBN)和受限玻尔兹曼机(RBM)的分类方法。
在上述方法中,输入是一维的。虽然利用了空间信息,但初始结构被破坏。
由于卷积神经网络(CNN)可以在保留原始结构的同时利用空间特征。Zhao等人[26]在他们的框架中采用了CNN作为特征提取器。
Lee等人[27]提出了一种具有更深和更广网络的上下文深度CNN(CDCNN)。
在[28]中,Chen等人设计了结合正则化的基于3D CNN的特征提取器模型。
尽管DL在HSI分类方面带来了有希望的改进,但DL对训练样本的需求是巨大的,而手动注释的成本对于HSI来说相当昂贵。通常,更深层次的网络可以捕获更精细的特征,但训练更深层次的网会更困难。
残余网络(ResNet)[29]和密集卷积网络(DenseNet)[30]的出现缓解了更深层次网络的训练难度。
受ResNet的启发,Zhong等人[31]提出了一种频谱空间残差网络(SSRN),该网络在有限的训练样本下更有效。
Wang等人[32]将DenseNet引入其快速密集谱空间卷积(FDSSC)算法。
为了优化提取的特征的区分,采用注意力机制来细化特征图。
Fang等人[33]基于DenseNet和注意力机制,设计了一个具有频谱关注机制(MSDN-SA)的三维密集卷积网络。
Ma等人[34]提出了由卷积块注意力模块(CBAM)[35]激励的双分支多注意力机制网络(DBMA),并获得了最佳分类结果。
Mou等人[36]提出了一种用于HSI分类的递归神经网络(RNN)框架,其中通过序列视角分析了高光谱像素。
由于HSI中严重缺乏标记样本,引入了半监督学习(SSL)[37]、生成对抗网络(GAN)[38]和主动学习(AL)[39]来缓解这一问题。
在[40]中,设计了光谱空间胶囊网络(CapsNets),以削弱网络的复杂性并提高分类的准确性。此外,self-pace learning [41], self-taught learning [42], and superpixel-based methods [43] 也值得注意。
创新点:
受最先进的DBMA算法和自适应自注意机制双注意网络(DANet)[44]的启发,我们设计了用于HSI分类的双分支双注意机制网络(DBDA)。所提出的框架包含两个分支,即光谱分支和空间分支,它们分别捕获光谱和空间特征。采用通道式注意机制和空间式注意机制来细化特征图。通过连接两个分支的输出,我们获得了融合的光谱空间特征。最后,使用softmax函数确定分类结果。
2、Related Work
2.1、HSI Classification Framework Based on 3D-Cube
基于像素的方法采用 pixel individual 训练网络,但是基于3D-cube 方法使用目标像素和它相邻像素作为输入。当然,相邻中心像素的标签没有被馈送到网络中,我们只探索目标像素周围丰富的空间信息。基于像素的方法和基于3D-cube的方法的差别是输入数据的尺寸不一样,前者1 x 1 x b,后者 p x p x b。
2.2、3D-CNN with Batch Normalization
输入丰富的标记图像,具有多个非线性层的深度学习模型可以学习分层表示,而多级卷积层使CNN能够更具辨别性地学习稀疏约束下的特征。1D-CNN和2D-CNN仅使用光谱特征或捕捉像素的局部空间特征。当对包含大量空间和频谱信息的HSI进行分类时,应采用3D-CNN来获得合理的结果。
添加BN层以提高数值稳定性。


2.3、ResNet and DenseNet
通常,卷积层越多,网络性能越好。然而,过多的层可能会导致梯度消失和爆炸。ResNet[29]和DenseNet[30]是摆脱这一困境的有效方法。
H是隐藏层,包含卷积层、激活层和BN层,在ResNet中,第L层残差块输出结果如下所示:
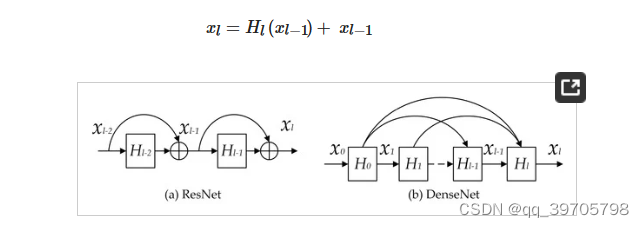
DenseNet直接连接所有层,以确保网络各层之间的最大信息流。DenseNet不像ResNet那样通过求和来组合特征,而是通过在信道维度中串联这些特征来组合特征。
![]()
其中,x0,x1...是特征图

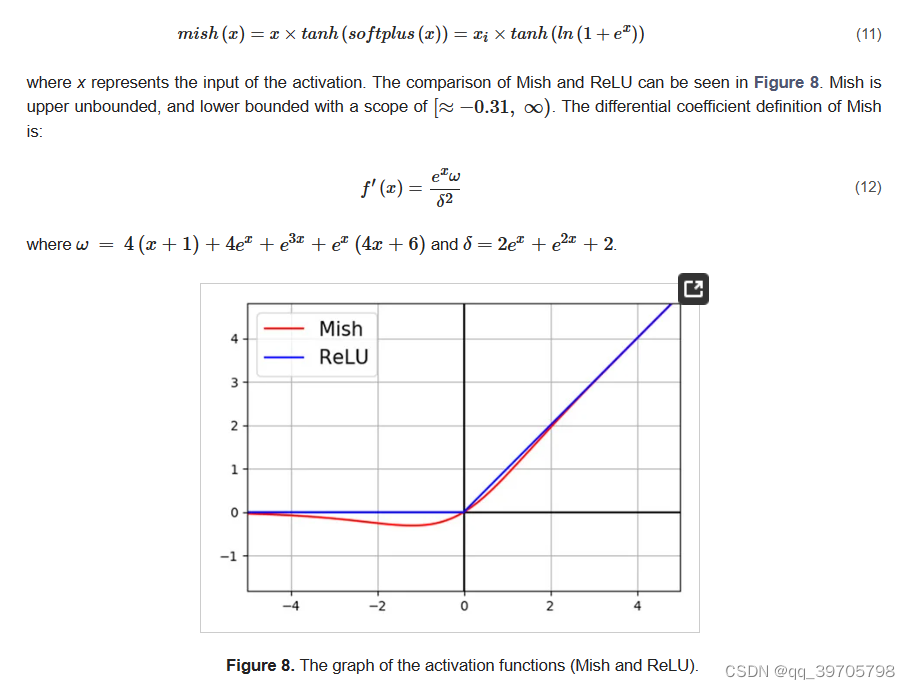
Mish是激活函数

2.4、Attention Mechanism
3D-CNN的一个缺点是,所有空间像素和光谱带在空间域和光谱域中具有相同的权重。显然,不同的光谱带和空间像素对提取特征有不同的贡献。注意力机制是处理这个问题的一种强有力的技术。
注意力机制已用于图像分类[47],后来被证明在其他领域表现突出,包括图像字幕[48]、文本到图像合成[49]和场景分割[44]等。在DANet[44]中,可以采用通道注意力块和空间注意力块来增加引人注目的通道和像素的权重。
2.4.1. Spectral Attention Block

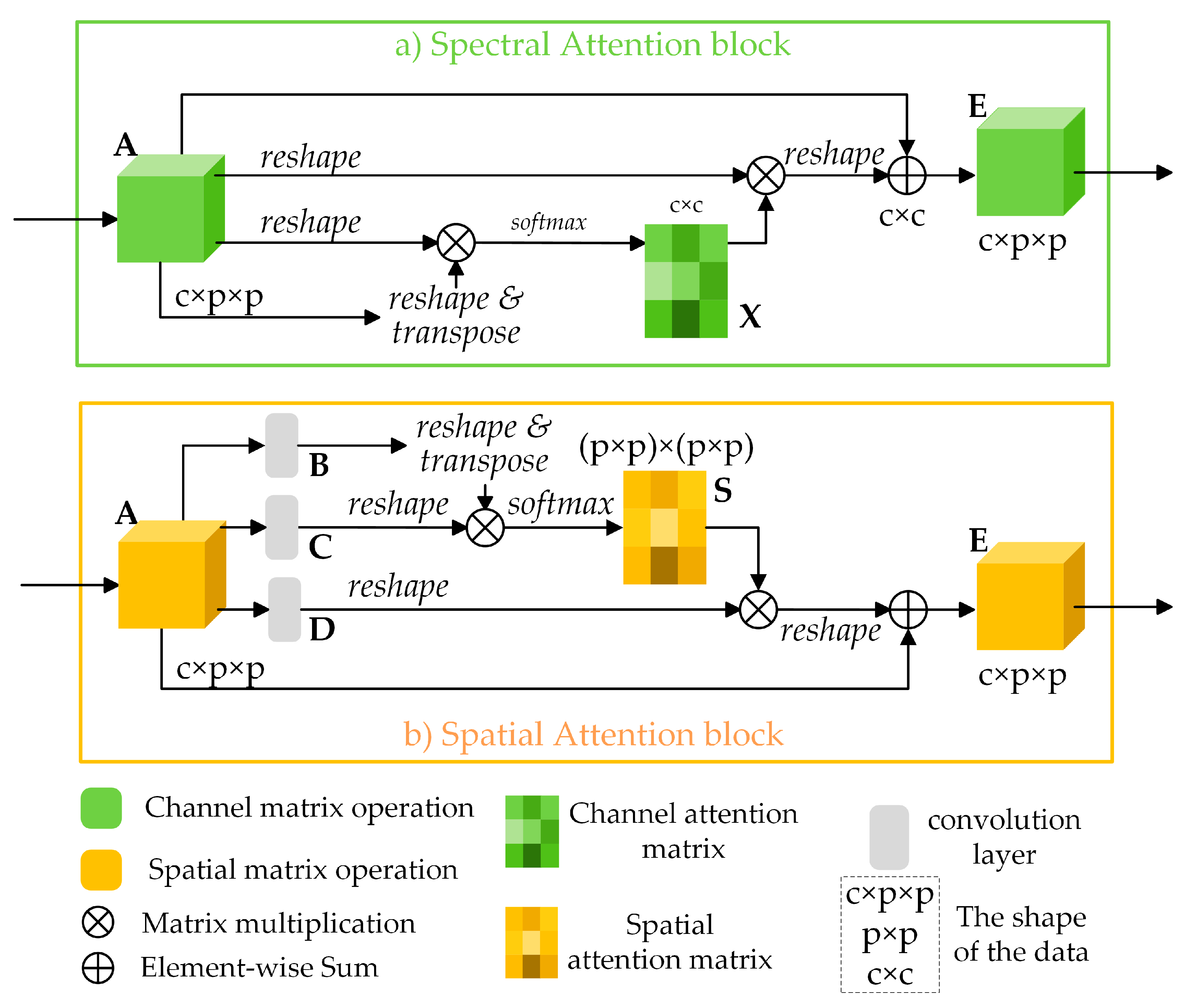
2.4.2. Spatial Attention Block

3. Methodology
训练集用于更新多个时期的参数,而验证集用于监控模型的性能并选择最佳训练模型。
在预测步骤中,选择测试集以验证训练模式的有效性。
采用交叉熵损失函数

3.1. The Framework of the DBDA Network

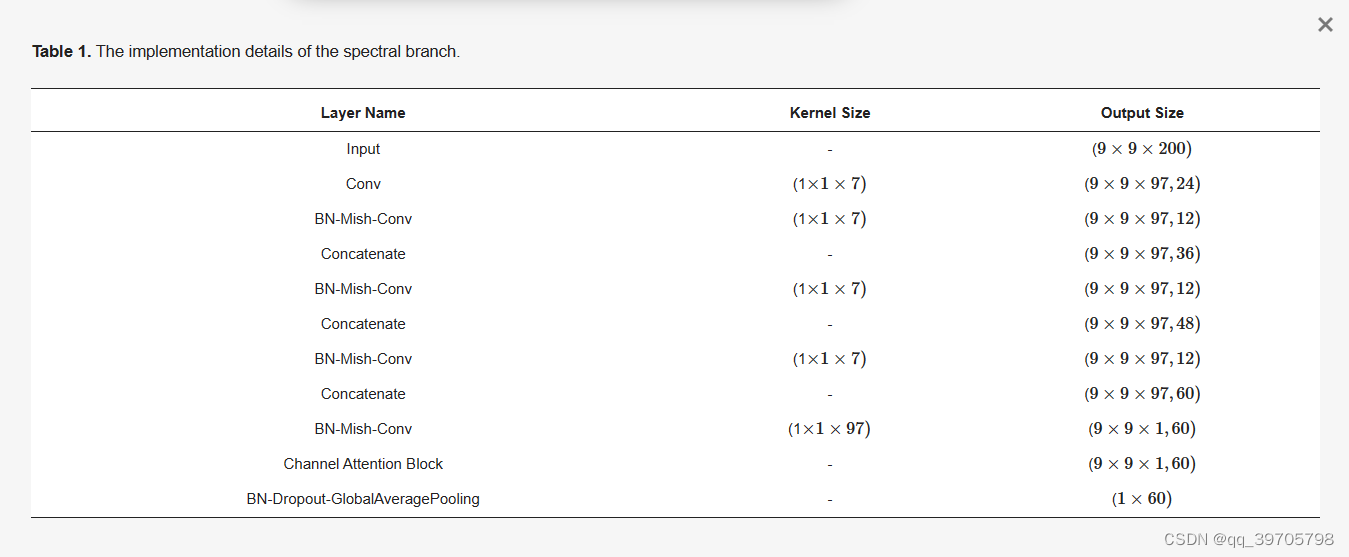
适当的激活函数可以加速网络的反向传播和收敛速度。
ReLU是一个分段线性函数,它修剪所有负输入。因此,如果输入是非阳性的,那么神经元将“死亡”,不能再被激活,即使负输入可能包含有用的信息。相反,Mish将负输入保留为负输出,从而更好地交换输入信息和网络稀疏性。
cosine annealing method 可以动态调整学习率

4. Experimental Results
评价指标选择OA、AA和Kappa系数
4.1. The Introduction about Datasets
数据集采用IP、UP、SV、Botswana (BS)
对于IP,我们选择3%的样本进行培训,3%的样本用于验证。由于样本对于每类UP和SV都足够,我们只选择0.5%的样本进行训练,0.5%的样本用于验证。对于BS,用于训练和验证的样本比例设置为1.2%。之所以出现小数点是因为BS中的样本数量很少,所以我们将比例设置为1%,并进行上限操作。
4.2. Experimental Setting
1、提出的DBDA,对比分析了CDCNN、SSRN、FDSSC、double-branch multi-attention mechanism network (DBMA)和SVM-RBF
基于pytorch,SVM用sklearn实现。
SVM :SVM-RBF
CDCNN:输入尺寸 5 *5*b
SSRN: 7*7*b
FDCNN: 9*9*b
DBMA: 7*7*b
2、4个数据集的分类结果以及每个类的分类结果
3、评估每个模型下,4个数据集的训练时间、测试时间
5. Discussion
1、分别用 0.5%, 1%, 3%, 5%, and 10% samples as the training sets,结果表明随着训练样本数量的增加,准确度会提高。不同模型之间的性能差距随着训练样本的增加而缩小。
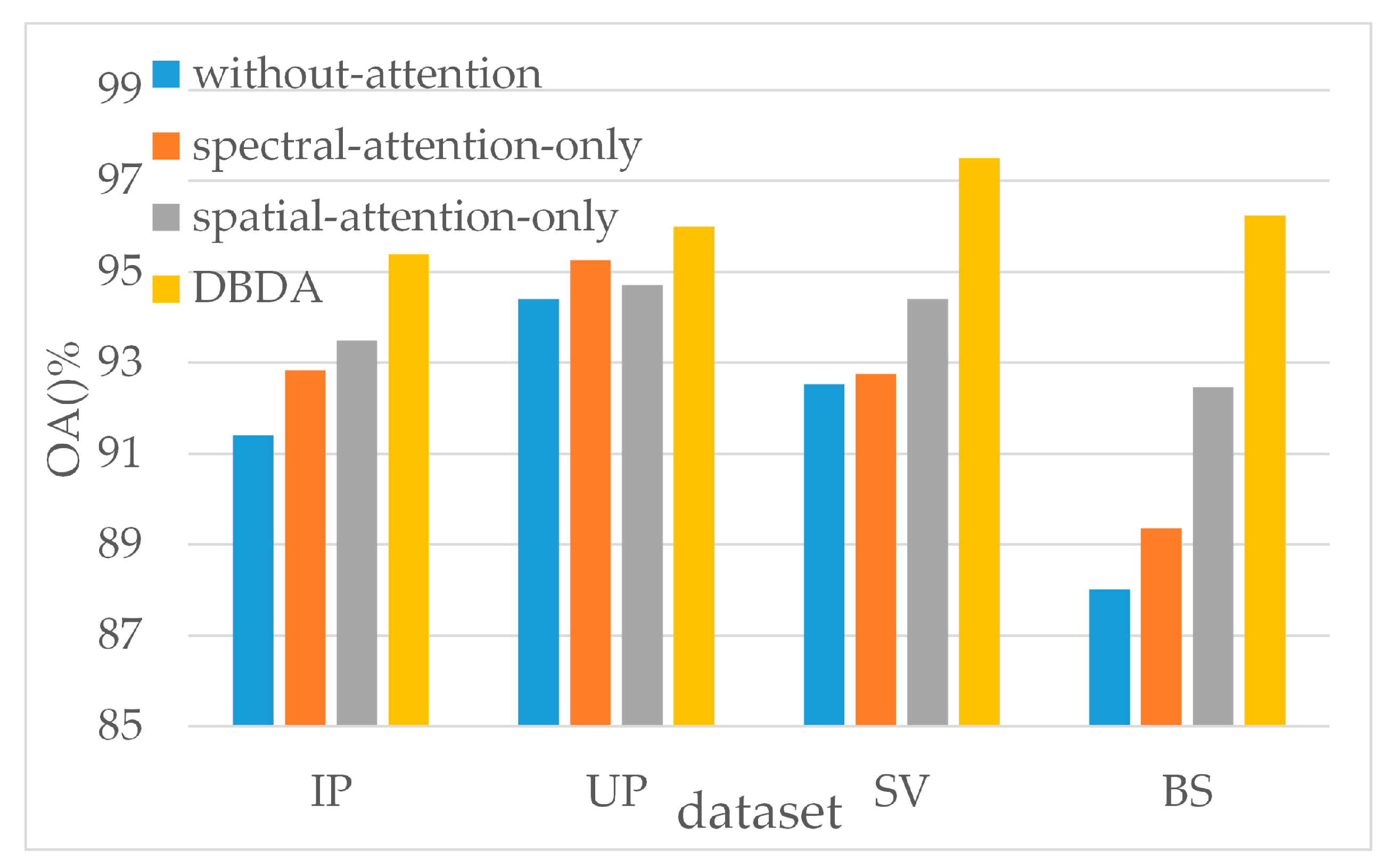
2、评估注意力机制的影响
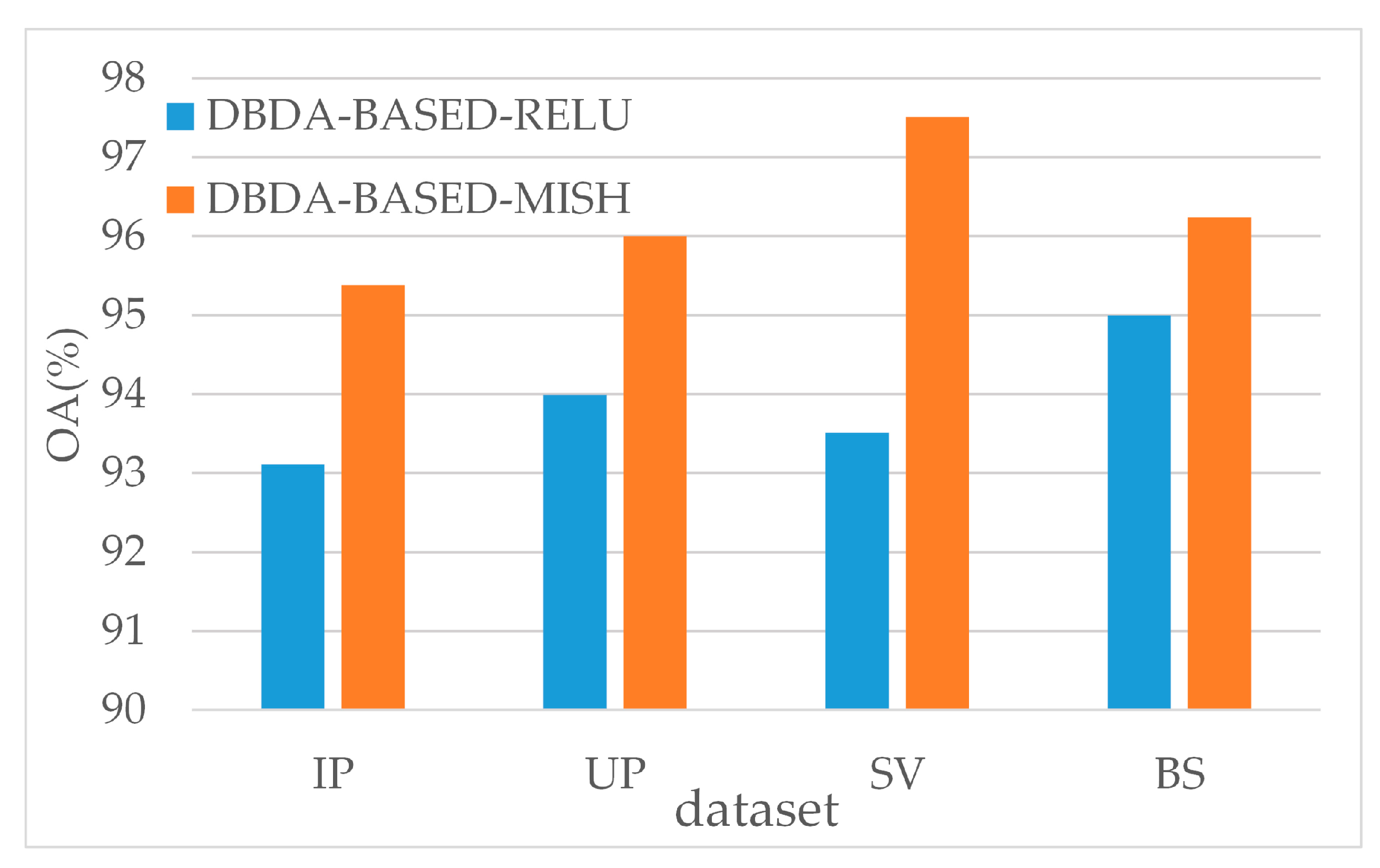
3、评估激活函数的影响















 3765
3765











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









