







线性模型是机器学习中最基础的模型,在中学学过的最小二乘法其实就是机器学习中的一种线性模型。我们先来回忆一下最小二乘法是什么
最小二乘法与基本线性回归
假设有如下所示的5个数据
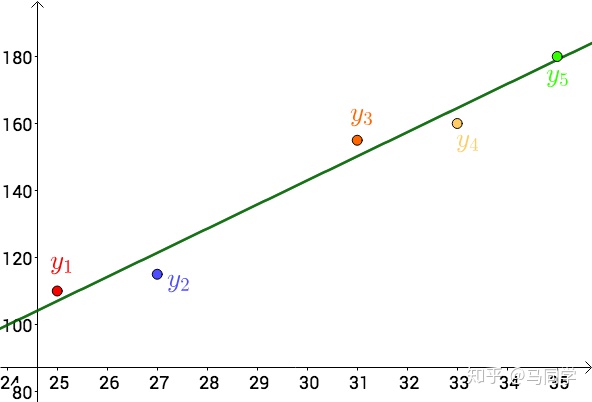
似乎这5个数据是在这条绿线上下浮动,我们的目的就是找到这条绿线的函数表达式。我们先假设这条绿线的函数表达式是
y
^
=
a
x
+
b
\hat y=ax+b
y^=ax+b
现在我们的问题就转换成了找到
a
a
a和
b
b
b的值。我们希望数据点尽可能多地落在函数图像上,即数据的误差和拟合直线的误差越小越好。由此得到以下式子
(
a
,
b
)
=
a
r
g
m
i
n
∑
i
=
1
5
∣
y
i
−
y
^
∣
(a,b)=argmin\sum_{i=1}^{5}|y_i-\hat y|
(a,b)=argmini=1∑5∣yi−y^∣
其中
∑
i
=
1
5
∣
y
i
−
y
^
∣
\sum_{i=1}^{5}|y_i-\hat y|
∑i=15∣yi−y^∣被称为代价函数(cost function)
由于计算机处理绝对值很麻烦,我们常常将这类问题转换成
(
a
,
b
)
=
a
r
g
m
i
n
∑
i
=
1
5
(
y
i
−
y
^
)
2
(a,b)=argmin\sum_{i=1}^{5}(y_i-\hat y)^2
(a,b)=argmini=1∑5(yi−y^)2
在中学阶段,我们通过猜测来推断出
a
a
a和
b
b
b的值,而到了大学阶段,我们很容易地看出这是一个二元函数求极值的问题。
在机器学习中,我们遇到的问题常常有多个维度,于是我们要拟合的函数表达式就变成了
f
(
x
)
=
w
1
x
1
+
w
2
x
2
+
.
.
.
w
d
x
d
+
b
f(x)=w_1x_1+w_2x_2+...w_dx_d+b
f(x)=w1x1+w2x2+...wdxd+b
写成向量形式
f
(
x
)
=
w
T
x
+
b
f(x)=w^Tx+b
f(x)=wTx+b
*注意:之后的式子若无特别说明均为向量形式
为了方便,我们把
b
b
b和
w
w
w写成一个向量
w
^
=
(
w
;
b
)
\hat w=(w;b)
w^=(w;b)
相应的,在
x
x
x最后一列恒置1(
b
b
b被吸收后空出的)
X
=
[
x
11
x
12
⋯
x
1
d
1
x
21
x
22
⋯
x
2
d
1
⋮
⋮
⋱
⋮
⋮
x
m
1
x
m
2
⋯
x
m
d
1
]
X= \begin{bmatrix} x_{11}& x_{12}& \cdots & x_{1d} & 1\\ x_{21}& x_{22}& \cdots & x_{2d} & 1\\ \vdots & \vdots & \ddots & \vdots & \vdots \\ x_{m1}& x_{m2}& \cdots & x_{md} & 1 \end{bmatrix}
X=⎣⎢⎢⎢⎡x11x21⋮xm1x12x22⋮xm2⋯⋯⋱⋯x1dx2d⋮xmd11⋮1⎦⎥⎥⎥⎤
于是整个式子就变成了
f
(
x
)
=
X
w
^
f(x)=X\hat w
f(x)=Xw^
根据上面最小二乘法的思路,我们的问题也就转换成了
w
^
∗
=
a
r
g
m
i
n
w
^
(
y
−
X
w
^
)
2
\hat w^*=\underset{\hat w}{argmin}(y-X\hat w)^2
w^∗=w^argmin(y−Xw^)2
在线性代数中,矩阵的平方常常表示成该矩阵的转置与其相乘的形式,于是
(
9
)
(9)
(9)式就变成了
w
^
∗
=
a
r
g
m
i
n
w
^
(
y
−
X
w
^
)
T
(
y
−
X
w
^
)
\hat w^*=\underset{\hat w}{argmin}(y-X\hat w)^T(y-X\hat w)
w^∗=w^argmin(y−Xw^)T(y−Xw^)
按照常规思路,令
w
^
=
(
y
−
X
w
^
)
T
(
y
−
X
w
^
)
\hat w=(y-X\hat w)^T(y-X\hat w)
w^=(y−Xw^)T(y−Xw^),对
w
^
\hat w
w^进行求导得
∂
w
^
∂
w
^
=
2
(
X
w
^
−
y
)
X
\frac{\partial \hat w}{\partial \hat w} =2(X\hat w-y)X
∂w^∂w^=2(Xw^−y)X
与西瓜书上不同是因为书上采用的是分母布局,本质是一个式子。将上式等于0,求解
w
^
∗
\hat w^*
w^∗带入
(
8
)
(8)
(8)式,即可得出结果
在
X
T
X
X^TX
XTX为满佚矩阵时
w
^
∗
=
(
X
T
X
)
−
1
X
T
y
\hat w^*=(X^TX)^{-1}X^Ty
w^∗=(XTX)−1XTy
对数几率回归(logistic回归)
对于一个线性回归问题,上面的方法可以很好地解决。但是对于分类问题,一个直线就很难拟合数据的分布特点,下面我们以二分类问题为例,研究logistics回归。
对于一个二分类问题,最好的拟合函数是“单位阶跃函数”
y
=
{
0
,
z
<
0
;
0.5
,
z
=
0
;
1
,
z
>
0
y=\left\{\begin{matrix} 0,&z<0; \\ 0.5,&z=0; \\ 1,&z>0 \end{matrix}\right.
y=⎩⎨⎧0,0.5,1,z<0;z=0;z>0
但是这个函数不可导,难以以最小二乘法的思想求拟合曲线,我们可以另选一个函数。希望
z
<
0
z<0
z<0时函数尽量为0,
z
>
0
z>0
z>0时函数尽量为1。sigmoid函数就是这么一个函数
y
=
1
1
+
e
−
z
y=\frac{1}{1+e^{-z}}
y=1+e−z1
图像如下
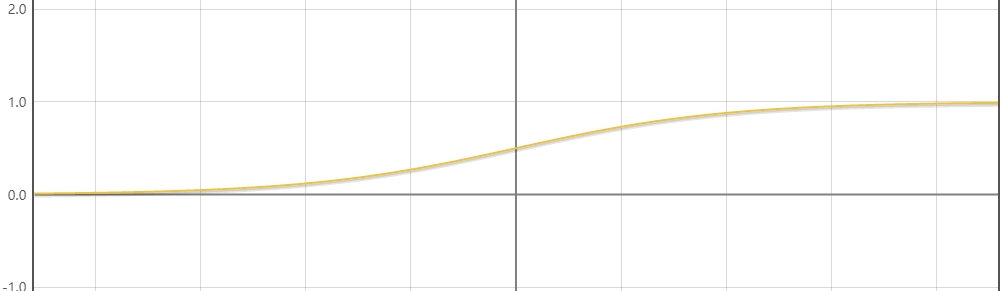
现在看来这个图像并不好,但当我们把
z
z
z之前的系数变成-100的时候图像如下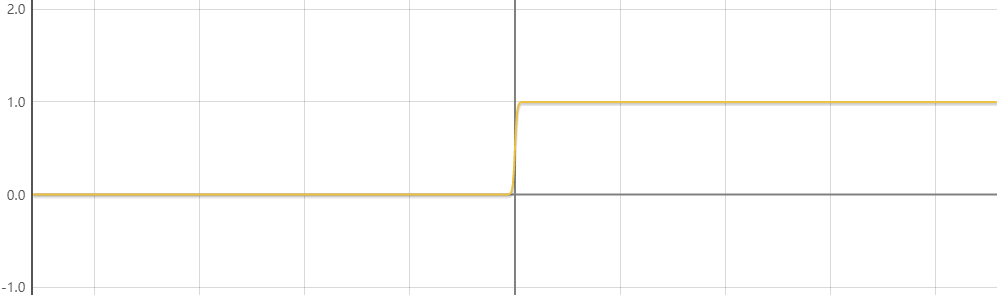
这样看来图像就像是我们所需要的样子了。事实上
z
z
z完全可以作为一个隐函数,这样我们的目标就变成了找到一个合适的函数
z
z
z,就可以使用上面最小二乘法的思路了。根据上面的思路,式
(
14
)
(14)
(14)变成了
y
=
1
1
+
e
−
(
w
T
x
+
b
)
y=\frac{1}{1+e^{-(w^Tx+b)}}
y=1+e−(wTx+b)1
如果我们在按照上面的思路MSE(均方误差,mean square error),由于加了一个sigmoid函数,使得整个函数变成非凸函数,可能有多个导数为0的点,很容易落入局部最优中。我们可以从概率的角度来推导logistic回归的代价函数。(说实话,我挺不喜欢这种方法的,但是我又不会其他方法ヽ(ー_ー)ノ)
设
P
(
y
=
0
∣
x
)
=
1
1
+
e
−
(
w
T
x
+
b
)
P(y=0|x)=\frac{1}{1+e^{-(w^Tx+b)}}
P(y=0∣x)=1+e−(wTx+b)1
相应的
P
(
y
∣
x
)
=
{
1
1
+
e
−
(
w
T
x
+
b
)
,
y
=
0
e
−
(
w
T
x
+
b
)
1
+
e
−
(
w
T
x
+
b
)
,
y
=
1
P(y|x)=\left\{\begin{matrix} \frac{1}{1+e^{-(w^Tx+b)}}, & y=0 \\ \frac{e^{-(w^Tx+b)}}{1+e^{-(w^Tx+b)}}, & y=1\end{matrix}\right.
P(y∣x)={1+e−(wTx+b)1,1+e−(wTx+b)e−(wTx+b),y=0y=1
将上式融合为一个式子
P
(
y
i
∣
x
i
)
=
p
y
i
(
1
−
p
)
(
1
−
y
i
)
P(y_i|x_i)=p^{y_i}(1-p)^{(1-y_i)}
P(yi∣xi)=pyi(1−p)(1−yi)
其中
p
=
e
w
T
x
+
b
1
+
e
w
T
x
+
b
p=\frac{e^{w^Tx+b}}{1+e^{w^Tx+b}}
p=1+ewTx+bewTx+b
根据最大似然估计,最大似然函数为
P
(
y
i
∣
x
i
;
w
,
b
)
=
∏
i
=
1
m
p
y
i
(
1
−
p
)
(
1
−
y
i
)
=
∑
i
=
1
m
ln
p
y
i
(
1
−
p
)
(
1
−
y
i
)
=
∑
n
=
1
N
(
y
n
ln
(
p
)
+
(
1
−
y
n
)
ln
(
1
−
p
)
)
P(y_i|x_i;w,b)=\prod_{i=1}^{m}p^{y_i}(1-p)^{(1-y_i)}=\sum_{i=1}^{m} \ln p^{y_i}(1-p)^{(1-y_i)}=\sum_{n=1}^{N}\left(y_{n} \ln (p)+\left(1-y_{n}\right) \ln (1-p)\right)
P(yi∣xi;w,b)=i=1∏mpyi(1−p)(1−yi)=i=1∑mlnpyi(1−p)(1−yi)=n=1∑N(ynln(p)+(1−yn)ln(1−p))
由于代价函数一般是求最小值,所以需要在上面式子中添加一个负号,最终的式子为
(
w
∗
,
b
∗
)
=
a
r
g
m
i
n
w
,
b
{
−
∑
n
=
1
N
(
y
n
ln
(
p
)
+
(
1
−
y
n
)
ln
(
1
−
p
)
)
}
(w^*,b^*)=\underset{w,b}{argmin}\left\{ -\sum_{n=1}^{N}\left(y_{n} \ln (p)+\left(1-y_{n}\right) \ln (1-p)\right) \right\}
(w∗,b∗)=w,bargmin{−n=1∑N(ynln(p)+(1−yn)ln(1−p))}
使用梯度下降法或牛顿法即可求得最优解。
线性判别分析
线性判别分析(LDA,linear discriminant analysis)和降维中的PCA非常像。LDA的基本思想是给定训练集,将这样样例投影到一个直线上,使相同样例的投影尽可能近,不同样例的投影点尽可能远离,其实就是“高内聚,低耦合”的思想。
我们假设直线
w
w
w,且
∣
∣
w
∣
∣
=
1
||w||=1
∣∣w∣∣=1,给定数据集
D
=
(
x
i
,
y
i
)
i
=
1
m
,
y
i
∈
{
0
,
1
}
D={(x_i,y_i)}^m_{i=1},y_i∈\{0,1\}
D=(xi,yi)i=1m,yi∈{0,1},易知数据在
w
w
w上的投影为
w
T
x
i
w^Tx_i
wTxi,
z
ˉ
y
i
\bar{z}_{y_i}
zˉyi为投影的均值,即
z
ˉ
y
i
=
1
N
i
∑
i
=
1
N
i
w
T
x
i
\bar{z}_{y_i}=\frac{1}{N_i}\sum^{N_i}_{i=1}w^Tx_i
zˉyi=Ni1i=1∑NiwTxi
设
μ
i
\mu_i
μi为数据的均值向量,即
μ
i
=
1
N
i
∑
i
=
1
N
i
x
i
\mu_i=\frac{1}{N_i}\sum^{N_i}_{i=1}x_i
μi=Ni1i=1∑Nixi
设
S
y
i
S_{y_i}
Syi为投影方差,即
S
y
i
=
1
N
i
∑
i
=
1
N
i
(
w
T
x
i
−
z
ˉ
i
)
(
w
T
x
i
−
z
ˉ
i
)
T
S_{y_i}=\frac{1}{N_i}\sum^{N_i}_{i=1}(w^Tx_i-\bar{z}_i)(w^Tx_i-\bar{z}_i)^T
Syi=Ni1i=1∑Ni(wTxi−zˉi)(wTxi−zˉi)T
其实
S
i
S_i
Si是个标量,我这么写其实是为了方便看。根据LDA的基本思想,我们便很容易的找到了目标函数。
J
=
(
z
ˉ
1
−
z
ˉ
2
)
2
S
1
+
S
2
J=\frac{(\bar{z}_1-\bar{z}_2)^2}{S_1+S_2}
J=S1+S2(zˉ1−zˉ2)2
我们的目标就是找到一个
w
w
w使分子尽量大,分母尽量小,即函数
J
J
J取得最大值,即
w
∗
=
a
r
g
m
a
x
(
z
ˉ
1
−
z
ˉ
2
)
2
S
1
+
S
2
w^*=argmax\frac{(\bar{z}_1-\bar{z}_2)^2}{S_1+S_2}
w∗=argmaxS1+S2(zˉ1−zˉ2)2
设类间散度矩阵
S
b
=
(
μ
1
−
μ
2
)
(
μ
1
−
μ
2
)
T
S_b=(\mu_1-\mu_2)(\mu_1-\mu_2)^T
Sb=(μ1−μ2)(μ1−μ2)T
设类内方差矩阵
S
c
1
=
1
N
1
∑
i
=
1
N
1
[
(
x
i
−
μ
1
)
(
x
i
−
μ
1
)
T
]
S_{c1}=\frac{1}{N_{1}} \sum_{i=1}^{N_{1}}\left[\left(x_{i}-{\mu_1}\right)\left(x_{i}-{\mu_1}\right)^{T}\right]
Sc1=N11i=1∑N1[(xi−μ1)(xi−μ1)T]
S c 2 = 1 N 2 ∑ i = 1 N 2 [ ( x i − μ 2 ) ( x i − μ 2 ) T ] S_{c2}=\frac{1}{N_{2}} \sum_{i=1}^{N_{2}}\left[\left(x_{i}-{\mu_2}\right)\left(x_{i}-{\mu_2}\right)^{T}\right] Sc2=N21i=1∑N2[(xi−μ2)(xi−μ2)T]
首先看分子
(
z
ˉ
1
−
z
ˉ
2
)
2
=
(
1
N
1
∑
i
=
1
N
1
w
T
x
1
−
1
N
2
∑
i
=
1
N
2
w
T
x
2
)
2
=
(
w
T
(
μ
1
−
μ
2
)
)
2
=
w
T
(
μ
1
−
μ
2
)
(
μ
1
−
μ
2
)
T
w
=
w
T
S
b
w
(\bar{z}_1-\bar{z}_2)^2 =(\frac{1}{N_1}\sum^{N_1}_{i=1}w^Tx_1-\frac{1}{N_2}\sum^{N_2}_{i=1}w^Tx_2)^2 =(w^T(\mu_1-\mu_2))^2 =w^T(\mu_1-\mu_2)(\mu_1-\mu_2)^Tw\\ =w^TS_bw
(zˉ1−zˉ2)2=(N11i=1∑N1wTx1−N21i=1∑N2wTx2)2=(wT(μ1−μ2))2=wT(μ1−μ2)(μ1−μ2)Tw=wTSbw
在看分母
S
1
+
S
2
=
1
N
1
∑
i
=
1
N
1
(
w
T
x
i
−
z
ˉ
1
)
(
w
T
x
i
−
z
ˉ
1
)
T
+
1
N
2
∑
i
=
1
N
2
(
w
T
x
i
−
z
ˉ
2
)
(
w
T
x
i
−
z
ˉ
2
)
T
=
1
N
1
∑
i
=
1
N
1
(
w
T
x
i
−
1
N
1
∑
i
=
1
N
1
w
T
x
i
)
(
w
T
x
i
−
1
N
1
∑
i
=
1
N
1
w
T
x
i
)
T
+
1
N
2
∑
i
=
1
N
2
(
w
T
x
i
−
1
N
2
∑
i
=
1
N
2
w
T
x
i
)
(
w
T
x
i
−
1
N
2
∑
i
=
1
N
2
w
T
x
i
)
T
=
w
T
1
N
1
∑
i
=
1
N
1
[
(
x
i
−
μ
1
)
(
x
i
−
μ
1
)
T
]
w
+
w
T
1
N
2
∑
i
=
1
N
2
[
(
x
i
−
μ
2
)
(
x
i
−
μ
2
)
T
]
w
=
w
T
(
S
c
1
+
S
c
2
)
w
S_1+S_2=\frac{1}{N_1}\sum^{N_1}_{i=1}(w^Tx_i-\bar{z}_1)(w^Tx_i-\bar{z}_1)^T+\frac{1}{N_2}\sum^{N_2}_{i=1}(w^Tx_i-\bar{z}_2)(w^Tx_i-\bar{z}_2)^T\\ =\frac{1}{N_1}\sum^{N_1}_{i=1}(w^Tx_i-\frac{1}{N_1}\sum^{N_1}_{i=1}w^Tx_i)(w^Tx_i-\frac{1}{N_1}\sum^{N_1}_{i=1}w^Tx_i)^T+\frac{1}{N_2}\sum^{N_2}_{i=1}(w^Tx_i-\frac{1}{N_2}\sum^{N_2}_{i=1}w^Tx_i)(w^Tx_i-\frac{1}{N_2}\sum^{N_2}_{i=1}w^Tx_i)^T\\ =w^{T} \frac{1}{N_{1}} \sum_{i=1}^{N_{1}}\left[\left(x_{i}-{\mu_1}\right)\left(x_{i}-{\mu_1}\right)^{T}\right] w+w^{T} \frac{1}{N_{2}} \sum_{i=1}^{N_{2}}\left[\left(x_{i}-{\mu_2}\right)\left(x_{i}-{\mu_2}\right)^{T}\right]w\\ =w^T(S_{c1}+S_{c2})w
S1+S2=N11i=1∑N1(wTxi−zˉ1)(wTxi−zˉ1)T+N21i=1∑N2(wTxi−zˉ2)(wTxi−zˉ2)T=N11i=1∑N1(wTxi−N11i=1∑N1wTxi)(wTxi−N11i=1∑N1wTxi)T+N21i=1∑N2(wTxi−N21i=1∑N2wTxi)(wTxi−N21i=1∑N2wTxi)T=wTN11i=1∑N1[(xi−μ1)(xi−μ1)T]w+wTN21i=1∑N2[(xi−μ2)(xi−μ2)T]w=wT(Sc1+Sc2)w
令
S
w
=
S
c
1
+
S
c
2
S_w=S_{c1}+S_{c2}
Sw=Sc1+Sc2
由以上式子可得
J
=
w
T
S
b
w
w
T
S
w
w
J=\frac{w^TS_bw}{w^TS_ww}
J=wTSwwwTSbw
对上式求导,并令导数为0
∂
J
(
w
)
∂
w
=
2
S
b
w
⋅
(
w
T
S
w
w
)
−
1
+
(
w
T
S
b
w
)
⋅
(
−
1
)
(
w
T
S
w
w
)
−
2
⋅
2
S
w
w
=
0
S
b
w
−
(
w
T
S
b
w
)
⋅
(
w
T
S
w
w
)
−
1
⋅
S
w
w
=
0
S
b
w
=
w
T
S
b
w
w
T
S
w
w
S
w
w
w
=
w
T
S
w
w
w
T
S
b
w
S
w
−
1
S
b
w
\begin{aligned} \frac{\partial J(w)}{\partial w}=2 S_{b} w \cdot\left(w^{T} S_{w} w\right)^{-1}+\left(w^{T} S_{b} w\right) \cdot(-1)\left(w^{T} S_{w} w\right)^{-2} \cdot 2 S_{w} w &=0 \\ S_{b} w-\left(w^{T} S_{b} w\right) \cdot\left(w^{T} S_{w} w\right)^{-1} \cdot S_{w} w &=0 \\ S_{b} w &=\frac{w^{T} S_{b} w}{w^{T} S_{w} w} S_{w} w \\ w &=\frac{w^{T} S_{w} w}{w^{T} S_{b} w} S_{w}^{-1} S_{b} w \end{aligned}
∂w∂J(w)=2Sbw⋅(wTSww)−1+(wTSbw)⋅(−1)(wTSww)−2⋅2SwwSbw−(wTSbw)⋅(wTSww)−1⋅SwwSbww=0=0=wTSwwwTSbwSww=wTSbwwTSwwSw−1Sbw
其中,易知
w
T
S
w
w
w
T
S
b
w
\frac{w^{T} S_{w} w}{w^{T} S_{b} w}
wTSbwwTSww为标量,
S
b
w
=
(
μ
1
−
μ
2
)
(
μ
1
−
μ
2
)
T
w
S_{b} w=(\mu_1-\mu_2)(\mu_1-\mu_2)^Tw
Sbw=(μ1−μ2)(μ1−μ2)Tw中的
(
μ
1
−
μ
2
)
T
w
(\mu_1-\mu_2)^Tw
(μ1−μ2)Tw也是标量,所以可以得出
w
∝
S
w
−
1
(
μ
1
−
μ
2
)
w\propto S_{w}^{-1}(\mu_1-\mu_2)
w∝Sw−1(μ1−μ2)
由于我们要求的是一个直线,所以不必在乎结果的大小,而只要关注方向即可,所以
S
w
−
1
(
μ
1
−
μ
2
)
S_{w}^{-1}(\mu_1-\mu_2)
Sw−1(μ1−μ2)的方向即我们所要求的直线的方向。
改LaTeX的代码真是酸爽┭┮﹏┭┮
多分类学习
多分类学习的基本思想是把多分类任务拆解成多个二分类任务,拆解方法有“一对一”(OvO),“一对其余”(OvR),“多对多”(MvM)
OvO将数据集中的所有数据两两配对,产生 N ( N − 1 ) / 2 N(N-1)/2 N(N−1)/2个分类任务,为每一个任务训练一个分类器,测试时将测试样本提交给所有分类器,由所有分类器投票,票数最多的类别作为最终分类结果。
OvR将一个类别作为正例,其余类别作为反例训练分类器,由此产生 N N N个分类器,测试时将测试样本提交给所有分类器,结果为正的则作为最终分类结果,若有过个分类器结果均为正,则选择分类器置信度最大的那个作为最终分类结果。
MvM是将若干类作为正类,其他类作为反类。其中最常用的是“纠错输出码”(error correcting output codes,ECOC)。
编码阶段:对 N N N个类别做 M M M次划分,每次划分将一部分化为正类,另一部分为反类。可以训练除M个分类器。
解码阶段:将测试样本提交给所有分类器,将分类器返回的结果组成编码,与每个类别各自的编码进行比较,其中距离(汉明距离或欧氏距离)最小的类别最为最终分类结果。
书上还有一个类别不平衡问题,其实就是个加权,没什么数学推导,我认为没必要写。















 1840
1840











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









