







题目:Self-Supervised Learning via Conditional Motion Propagation
DOI:10.1109/CVPR.2019.00198
时间:2019-03-27上传于arxiv
会议:2019-CVPR
机构:香港中文大学、南洋理工大学
论文链接:https://arxiv.org/abs/1903.11412
代码链接:https://github.com/XiaohangZhan/conditional-motion-propagation
工程链接:Self-Supervised Learning via Conditional Motion Propagati
关键词:条件运动传播、稀疏引导、光流
提出问题:
各种自监督算法利用运动线索来学习有效的视觉表示。但是,运动既模糊又复杂,使得学习效率下降,要么对物体运动采用强烈的假设。
创新点/方法:
1、从以稀疏运动引导为条件的静态图像中恢复完整的图像运动。(不是显式地运动概率建模)
2、设计了一种基于“分水岭”的抽样策略,以期抽样点尽量落在运动物体上,并且足够稀疏。
属性+指令=运动
观测:单张图片和抽象指令。预测:运动。而“内在规律”即为物体属性。
物体属性是我们希望学到的信息,而运动可以用已有的光流来描述,那么我们只需要有“指令”就可以了。
网络模型:
该框架包含三个模块:图像编码器、稀疏运动编码器和密集运动解码器。
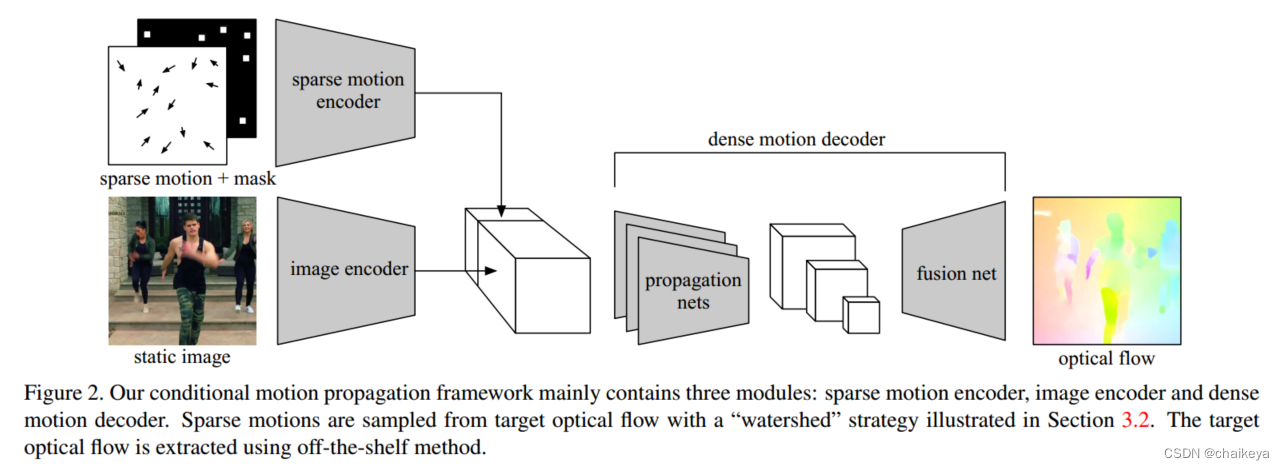
对图像进行编码,期望得到物体属性相关特征,然后从运动场中抽样出稀疏运动代表“指令”(条件),将两者输入到运动解码器中预测出完整运动场。
1、图像编码器:(属性)
预训练模型,是一个标准的主干卷积神经网络(CNN)。主干是AlexNet或ResNet-50,这取决于不同的目标任务。
2、稀疏运动编码器:(指令)
是一种浅层的CNN,旨在将稀疏运动编码为紧凑的特征。它包含两个堆叠的Conv-BN-ReLU池块,并将稀疏运动编码为16个通道。空间步长取决于图像编码器的步长。
3、密集运动解码器:(运动)
设计用于根据编码的运动学特性将运动传播到整个图像。解码器包含多个传播网络和一个融合网络。传播网络是具有不同空间步长的CNN。空间步长越大,感受野越大,因此传播距离越长。而那些空间步长较小的则专注于较短的距离,从而产生细粒度的结果。每个传播网络由一个具有各自步幅的最大池层和两个堆叠的Conv-BN-ReLU块组成。我们将传播网络设计得相当浅,以迫使图像编码器学习更多有意义的信息。最后,将传播网络的输出上采样到相同的空间分辨率,并连接到融合网络(单个卷积层)中,以生成预测。
从目标光流中采样稀疏运动引导:(获取指令)
为了有效传播,应将这些引导向量放置在运动具有代表性的一些关键点上。我们采用基于分水岭的方法对这些关键点进行采样。如图3所示,给定图像的光流,
首先,使用Sobel滤波器提取运动边缘。
然后,为每个像素指定一个值作为到其最近边的距离,从而生成拓扑距离分水岭地图。
最后,在分水岭地图上应用核大小为K的非最大值抑制(NMS)[5]来获得关键点。可以调整K来控制采样点的平均数量。K越大,样本越稀疏。

异常值处理:
如图3第三行所示。无序的流边会创建断开连接的流域,这会导致选择大量关键点。然而,它并不影响学习。这些图像示例实际上很简单,因为丰富的指导减轻了学习这些无意义动作的压力。换言之,在某种程度上忽略了这些具有塌陷流的示例。因此,我们的框架对光流质量具有鲁棒性。
损失函数:
将目标流量化,并将其表示为分类任务。我们将目标流裁剪在一个松散的边界内,并分别在x和y坐标下将其线性划分为C个单元。然后用两个线性分类器对它们进行分类。我们分别对x和y流使用交叉熵损失。其公式如下:
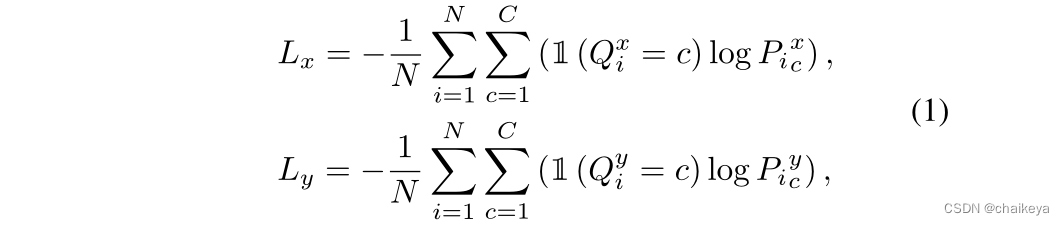
其中,N是像素总数,P是来自SoftMax层的概率,Q是量化标签,ll是一个指示器功能。Lx和Ly应用相同的权重。
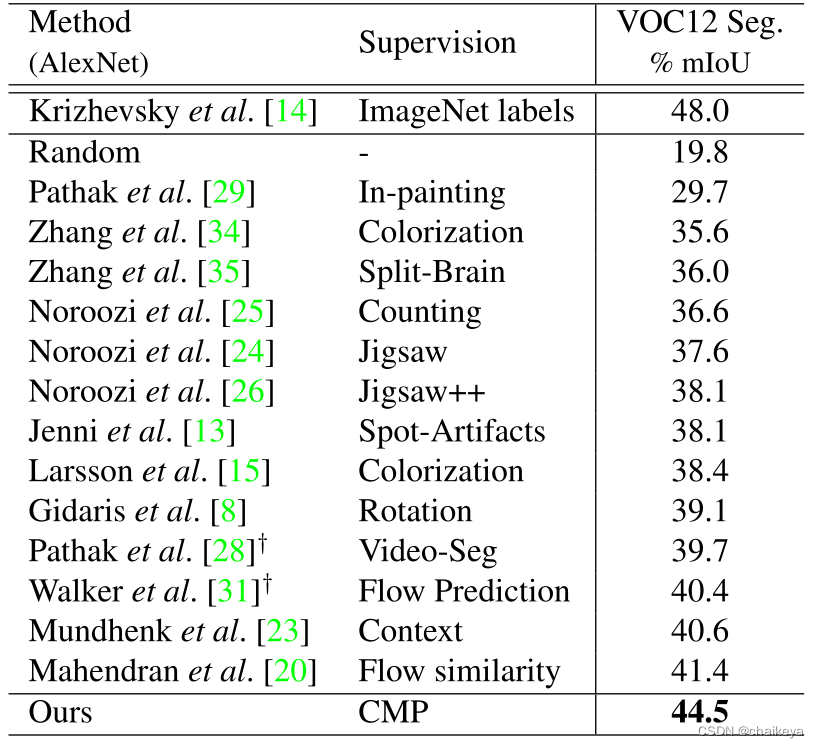
应用1:表征学习能力。
我们将条件运动传播网络中的图像编码器提取出来,用来初始化其它高级任务,包括语意分割、实例分割和人体解析。
我们期望用条件运动传播任务初始化的神经网络参数能为这些更高级的任务提供一个较好的初始化。这也是自监督学习领域的标准评价指标。在这些任务上,条件运动传播相比以往自监督学习方法获得了较大提升。
应用2:在测试时,条件运动传播可以由用户制定“指令”。

图6. 条件运动传播测试时可以由用户制定“指令”
例如在图6第一个例子中,给定舞者一个“抬左脚”的指令(对应脚上的红色箭头),预测出来的运动场中,整个左脚连同小腿绕着膝关节旋转。而给定舞者“身体向前”的指令后,预测出来身体是整体平移。这些观测大致符合人体作为一个铰接体的运动规律。
图6另一个例子中,给定舞者左侧大腿后抬的指令,预测结果中整个左腿能够一起运动;而给定舞者右腿后移的指令,预测结果中脚仍旧还是固定的,因为右脚支撑在地上。这些结果遵循物体的运动学属性,并且反映出了一部分现实世界中的物理规律。
利用这些特性,我们将它应用到了交互式视频生成。

图7. 交互式视频生成
T=0为输入图片,红色箭头为用户的指令(鼠标拖拽),利用条件运动传播,能够根据不同的指令生成合理的运动后的图像。
如图7,我们将原图用预测出来的光流做warping后得到运动后的图像。这样我们可以使用鼠标让一张静态图中的物体动起来,并且它们的运动符合其原有的运动规律
应用3:半自动实例标注。
我们发现条件运动传播能很好地分割出物体的边界,而不受复杂的背景影响。因此我们利用训练好的条件运动传播网络实现了半自动实例标注。
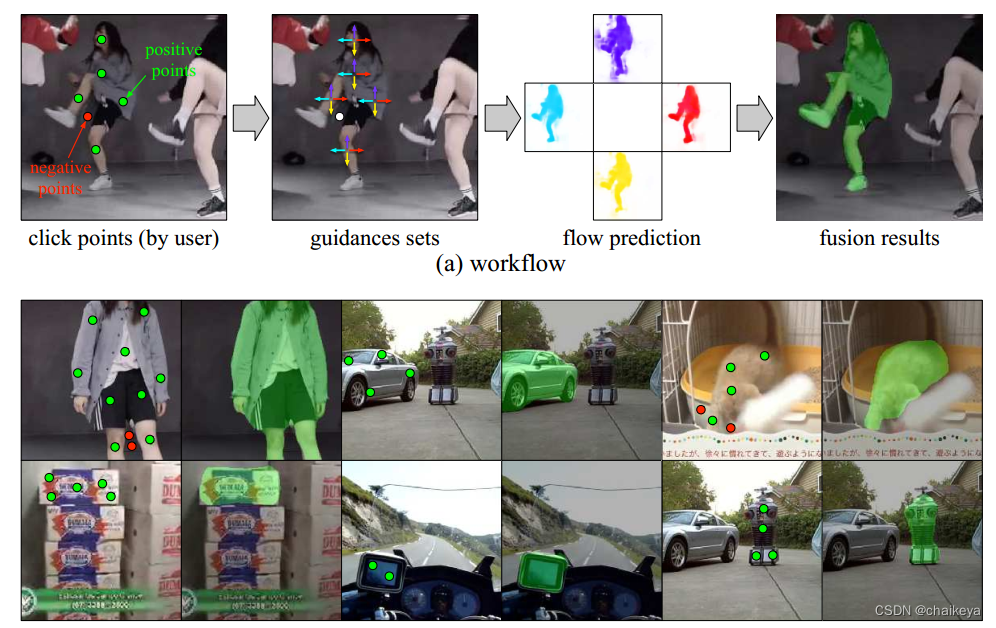
图8. 半自动实例标注
如图8,用户只需指定少量落在目标物体上的positive points和物体外的negative points即可得到物体的mask。由于条件运动传播是无监督的,没有物体类别的限制,因此可以用来标注一些不常见的物体。
到此为止,这些结果都没有用到任何人工的标注。
参考链接:
1、稀疏表示:稀疏表示
稀疏表示(Sparse Representation)也叫作稀疏编码(Sparse Coding),就是用字典中元素的线性组合去表示测试样本。
2、自监督:自监督学习
半监督(semi-supervised learning):利用好大量无标注数据和少量有标注数据进行监督学习;
远程监督(distant-supervised learning):利用知识库对未标注数据进行标注;
无监督:不依赖任何标签值,通过对数据内在特征的挖掘,找到样本间的关系,比如聚类相关的任务。
自监督:利用辅助任务从无监督的数据中挖掘大量自身的信息。(辅助任务就是基于数据特征构造一个任务进行训练)用于机器学习的标注(ground truth)源于数据本身,而非来自人工标注。
3、鲁棒性:鲁棒性
鲁棒性(Robustness)即一个系统或组织有抵御或克服不利条件的能力。
4、参考笔记:我爱计算机视觉的博客


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









