






在 Stata 中实现中介效应(Mediation Effect)分析通常包括以下几个步骤:首先拟合基础模型,然后估计中介变量的效应,最后检验中介效应是否显著。常见的中介效应模型是使用 Baron & Kenny 方法或 结构方程模型(SEM)。
以下是一个基于 Stata 的中介效应分析流程,其中包括了数据准备、模型设定、路径分析等步骤,并提供了相关的代码示例。

1. 数据准备
假设你有一个数据集,其中包含一个自变量(X),一个因变量(Y)和一个中介变量(M)。
* 导入数据
import delimited "your_data.csv", clear
* 假设你的数据包含变量: X, Y 和 M
2. 检验是否存在中介效应(Baron & Kenny 方法)
Baron 和 Kenny 提出的经典中介效应检验方法通常分为四个步骤:
- 自变量 X 对因变量 Y 的影响显著。
- 自变量 X 对中介变量 M 的影响显著。
- 中介变量 M 对因变量 Y 的影响显著。
- 控制了 M 后,自变量 X 对因变量 Y 的直接效应显著下降或不显著,从而判断中介效应。
第一步:自变量 X 对因变量 Y 的影响
* 拟合回归模型:Y = cX
regress Y X
第二步:自变量 X 对中介变量 M 的影响
* 拟合回归模型:M = aX
regress M X
第三步:中介变量 M 对因变量 Y 的影响
* 拟合回归模型:Y = c'X + bM
regress Y X M
第四步:自变量 X 对因变量 Y 的直接效应
* 直接效应的检验已经在第 3 步中完成,注意检查X的系数。
3. 检验中介效应的显著性(Bootstrapping 方法)
为了更精确地检验中介效应的显著性,可以使用 Bootstrapping 方法来计算中介效应的置信区间。Stata 提供了 bootstrap 命令来进行这种非参数估计。
进行中介效应的 Bootstrapping 检验
* 使用 Bootstrapping 检验中介效应
bootstrap r(a)*r(b), reps(500) saving(bootstrap_results.dta) : regress Y X M
在上面的代码中,r(a) 是自变量 X 对中介变量 M 的回归系数,r(b) 是中介变量 M 对因变量 Y 的回归系数。我们通过 reps(500) 指定了重复抽样次数。
检查结果
* 检查 Bootstrapping 结果的置信区间
use bootstrap_results.dta, clear
summarize r(a) r(b)
4. 使用结构方程模型(SEM)进行中介效应分析
Stata 也提供了结构方程模型(SEM)工具来进行中介效应分析,SEM 可以同时估计多个路径,从而实现更复杂的中介模型。
* 使用结构方程模型(SEM)进行中介效应分析
sem (Y <- X M) (M <- X), method(ml)
在这个模型中,Y <- X 表示自变量 X 对因变量 Y 的效应,M <- X 表示自变量 X 对中介变量 M 的效应,Y <- M 表示中介变量 M 对因变量 Y 的效应。
5. 检验中介效应的显著性
在 SEM 模型中,可以通过路径系数和标准误差来检验中介效应的显著性。如果你使用了 Bootstrapping 方法,Stata 会自动计算中介效应的显著性。
* 检查路径系数和显著性
estat ic
6. 可视化中介效应的结果
你可以通过 Stata 的图形命令可视化中介效应的路径图。
* 绘制路径图
sem (Y <- X M) (M <- X), method(ml)
graph semplot
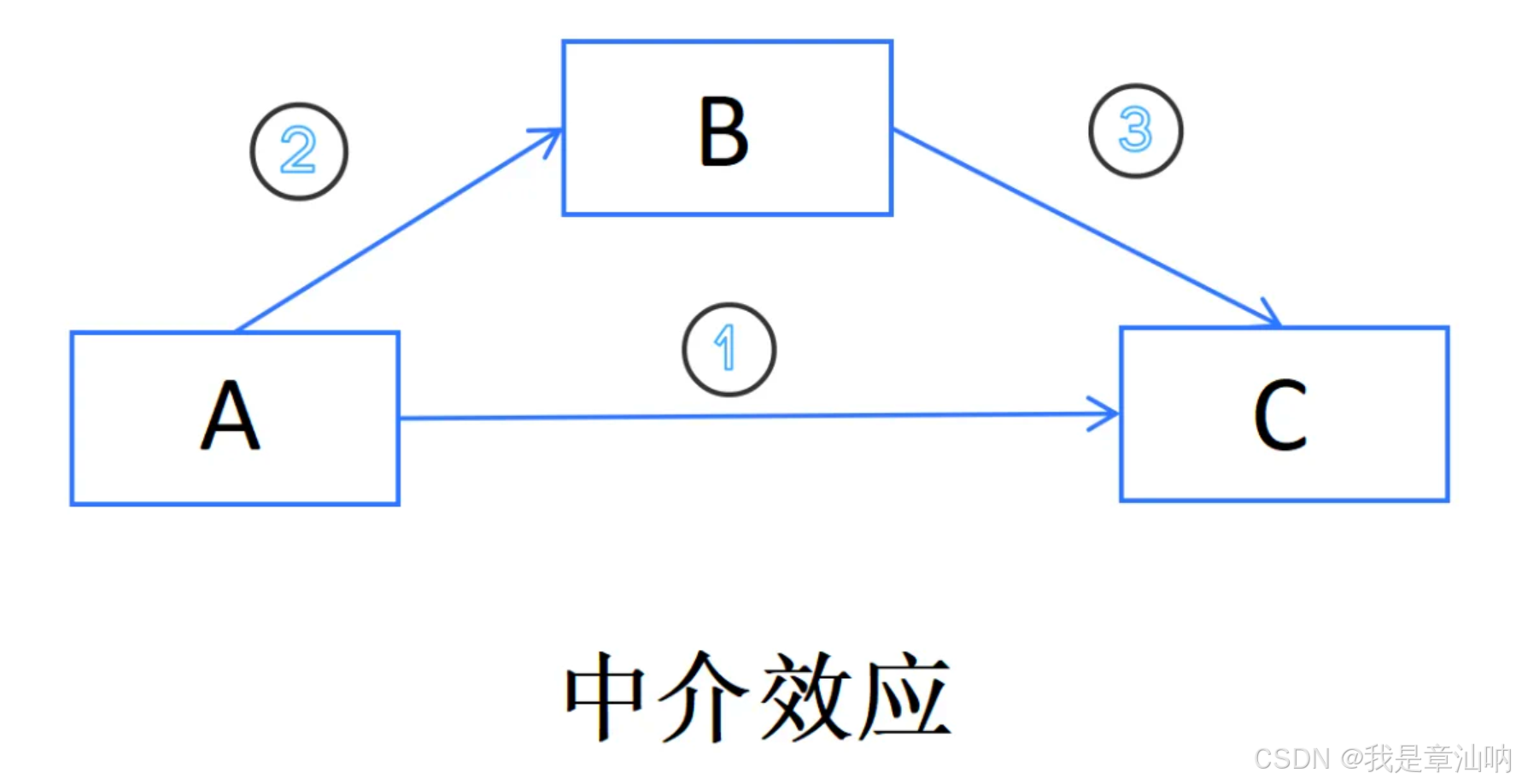
通过上述步骤,你可以使用 Stata 来完成中介效应分析。中介效应的检验可以通过经典的 Baron 和 Kenny 方法进行,也可以通过 Bootstrapping 或 SEM 方法来更加精确地检验中介效应的显著性。
如果你有具体的模型或数据需求,可以进一步调整这些代码。


















 2831
2831

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











