







文章标题:ICLR2015-Neural machine translation by jointly learning to align and translate
梗概:
本文提出了一种新的编码-译码方式,他认为之前提到的RNN-encode-decoder 是因为中间转换的固定向量C,而导致该模型无法有效处理长句序列,因此提出一种为当前预测词从输入序列中自动搜寻相关部分的机制(soft-search),也就是注意力机制
具体实现:
因为前面已经对RNN-encoder-decoder做了介绍,所以这里就不在详细的说了。
我们定义最后对应的输出结果为:
![]()
St为隐状态,![]()
Ci为关键,他取决于输入序列的annotation(h1…ht)(编码层的隐状态),每个hi都包含着整个输入序列的信息,重点关注的是当前输入单词xi的周围信息。
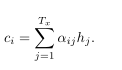
而
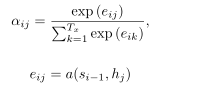
这个地方其实比较迷惑,从上面这几个式子来分析,我们可以看出来,a为一个对齐模型,文章中体现为一个前馈神经网络,并且是和其他模型一起训练的,他的目的便是计算当前输入的隐状态si-1和输入序列hj之间的相似度,在文章中对齐模型a为一个单层感知机:
这里也提出了一种计算相似度的方法,也就是通过网络(一般是感知机网络)来计算。
个人感悟:
这篇文章很明显是基于之前的RNN-encoder-decoder,但提出了一些创新。首先是:
1、他利用biLSTM来解决RNN的长时依赖问题,每个输出的hi隐状态是正反LSTM的hi连接生成的,也就是说当前的隐状态hi主要focus on 当前的词,而当前词主要是由周围的词决定的,而这周围词也就是上下文。
2、注意力机制:我们要注意的是注意力机制最关键是找到context vector或extra information,在这里便是si-1,也就是输出单词的前一个隐状态,实际上我们稍微深究一下,这个隐状态实际上代表的便是当前的输出词向量,而这个隐状态包含的是之前的输出词信息,也就是一种另类的上下文。















 1302
1302











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









