







利用百度或高德的api接口,是无法获得这些poi点的详细信息数据的,只能获得poi的经纬度和类型,还有名字,但是这个poi的面积,形状具体是咋样的,我们是无法得知的,百度或高德的api接口没有给出这个信息。《地图时空大数据爬取》一书上第6章后半部分给出一个爬虫的代码,但是这个代码现在已经不行了,网上说好像是因为高德网站更新过了,反爬性能变强了,以后直接用request,urllib等来爬是无法成功的。而且我尝试了更改ip,更改浏览器伪装信息user-agent等都无法成功,最后还使得我电脑无法用高德进行查询了,十分难受,不过看来看到了这个大佬写的另一种爬虫思路,用这种思路重新写了一下爬虫,终于成功爬取了poi的边界信息,然后再用geopandas处理一下就可以得到每个poi的polygon了,不过评分,面积什么就没有爬取了,但是这些也不重要,面积可以自己算一下就完了。
1.书上的代码
现在使用这个爬取,我尝试过可以成功爬取几十个poi的信息,然后就会被封了,十分难受。
import basics
import geopandas as gpd
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import json
import urllib
from urllib.parse import quote
import string
from shapely.geometry import Point
from shapely.geometry import Polygon
from shapely.geometry import LineString
import pyproj
import time
import random
import importlib
importlib.reload(basics)
抓取公园信息
cookie = 'your cookie'
refer = 'your refer'
user_agent = 'your user-agent'
def getBoundry(POIList,poitype,writeboundryfile,starti):
for i in range(starti,len(POIList)):
poi = POIList[i]
send_headers={'user-agent': user_agent , 'cookie':cookie ,'refer':refer }
url="https://ditu.amap.com/detail/get/detail?id="+poi.id
print(i,poi.id,url)
req=urllib.request.Request(url,headers=send_headers)
json_obj=urllib.request.urlopen(req)
json_data=json.load(json_obj)
# print(json_data)
poidata=json_data['data']
try:
spec=poidata['spec']
except Exception as e:
print(poi.id,poidata)
continue
try:
mining_shape = spec['mining_shape']
except Exception as e:
print(poi.id , "无边界")
else:
shape = mining_shape['shape']
coords = shape.split(';')
coords1=str("|".join(coords))
try:
area=mining_shape['area']
except Exception as e:
area=-1
print("无面积")
# 如果是是居住小区,poi增加容积率和绿化率的字段
if (poitype == "12302"):
try:
poi.volume_rate = str(poidata['deep']['volume_rate'])
except Exception as e:
poi.volume_rate = ""
try:
poi.green_rate=str(poidata['deep']['green_rate'])
except Exception as e:
poi.green_rate = ""
try:
poi.sevice_parking=poidata['deep']['sevice_parking']
except Exception as e:
poi.service_parking=""
bf=open(writeboundryfile,'a')
bf.write(poi.id+";"+poi.type+";"+poi.lon+";"+poi.lat+";"+poi.volume_rate+";"+poi.green_rate+";"+poi.service_parking+\
";"+coords1+"\n")
bf.close()
# 如果是公园绿地
if (poitype == '110100' or poitype == '110101' or poitype == '110102' or poitype == '110103' or
poitype == '110104' or poitype == '110105' or poitype == '110202' or poitype == '110203'):
try :
star = poidata['deep']['src_star']
except Exception as e:
print(poi.id , "无评分")
star = '-1'
poi.star = str(star)
poi.area = str(area)
bf=open(writeboundryfile , 'a')
bf.write(str(poi.id)+";"+str(poi.type)+";"+str(poi.lon)+";"+str(poi.lat)+";"+str(poi.star)+";"+str(poi.area)+";"+str(coords)+"\n")
bf.close()
rand = random.randint(0,30)
time.sleep(30+rand)
output_directory = "F:\\study1\\研一\\兴趣面数据采集\\"
parksfile = output_directory + "杭州市公园POI.txt"
writeboundryfile = output_directory + "boundry.txt"
poitype = '110101'
POIList = basics.creatpoint(parksfile ,0,3,4,2,1)
getBoundry( POIList ,poitype ,writeboundryfile , 62)
62 B0FFH35BLM https://ditu.amap.com/detail/get/detail?id=B0FFH35BLM
---------------------------------------------------------------------------
KeyError Traceback (most recent call last)
<ipython-input-34-4e5b057420a0> in <module>
4 poitype = '110101'
5 POIList = basics.creatpoint(parksfile ,0,3,4,2,1)
----> 6 getBoundry( POIList ,poitype ,writeboundryfile , 62)
<ipython-input-33-5426a5b911a2> in getBoundry(POIList, poitype, writeboundryfile, starti)
9 json_data=json.load(json_obj)
10 # print(json_data)
---> 11 poidata=json_data['data']
12 try:
13 spec=poidata['spec']
KeyError: 'data'
2.通过伪装代理和ip来进行爬取
现在这种方法也无法成功了,应该是因为反爬技术提升了吧。
通过伪装代理和伪装ip来进行爬取
import random
import requests
import re
# 用于获取User_Agent
from fake_useragent import UserAgent
# 获取随机User_Agent伪装
def get_fake_User_Agent():
# 随机获取User_Agent
ua = UserAgent()
user_anget = ua.random
return user_anget
# 获取IP伪装
def get_fake_IP():
ip_page = requests.get( # 获取200条IP
'http://www.89ip.cn/tqdl.html?num=60&address=&kill_address=&port=&kill_port=&isp=')
proxies_list = re.findall(
r'(25[0-5]|2[0-4]\d|[0-1]\d{2}|[1-9]?\d)\.(25[0-5]|2[0-4]\d|[0-1]\d{2}|[1-9]?\d)\.(25[0-5]|2[0-4]\d|[0-1]\d{2}|[1-9]?\d)\.(25[0-5]|2[0-4]\d|[0-1]\d{2}|[1-9]?\d)(:-?[1-9]\d*)',
ip_page.text)
# 转换proxies_list的元素为list,最初为'tuple'元组格式
proxies_list = list(map(list, proxies_list))
# 格式化ip ('112', '111', '217', '188', ':9999') ---> 112.111.217.188:9999
for u in range(0, len(proxies_list)):
# 通过小数点来连接为字符
proxies_list[u] = '.'.join(proxies_list[u])
# 用rindex()查找最后一个小数点的位置,
index = proxies_list[u].rindex('.')
# 将元素转换为list格式
proxies_list[u] = list(proxies_list[u])
# 修改位置为index的字符为空白(去除最后一个小数点)
proxies_list[u][index] = ''
# 重新通过空白符连接为字符
proxies_list[u] = ''.join(proxies_list[u])
# proxies = {'协议':'协议://IP:端口号'}
# 'https':'https://59.172.27.6:38380'
return "'" + random.choice(proxies_list) + "'"
# 解析网址
def get_html(url):
headers = {
'User-Agent': get_fake_User_Agent()
}
proxies = {'http': get_fake_IP()}
resp = requests.get(url, headers=headers, proxies=proxies)
return resp
url = "https://ditu.amap.com/detail/get/detail?id=B0FFH35BLM"
result = get_html(url)
result
json_obj = result.json() # 将结果进行反序列化
# json_data=json.load(json_obj)
json_obj
上面的两种方法都不行了,高德地图的网站似乎进行了更新,这种通过链接直接爬取的方式已经不行了。而且换ip,伪装代理也不能成功。
在网上查到了下面这种爬虫的方式,亲测这种爬虫是可以成功的。
https://zhuanlan.zhihu.com/p/248626051?utm_source=wechat_timeline
import random
import re
import time
from browsermobproxy import Server
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
server = Server(r'C:\Users\Administrator\Desktop\browsermob-proxy-2.1.4-bin\browsermob-proxy-2.1.4\bin\browsermob-proxy.bat')
server.start()
proxy = server.create_proxy()
chrome_options = Options()
chrome_options.add_argument('--proxy-server={0}'.format(proxy.proxy)) # 加代理抓包
chrome_options.add_argument('--ignore-certificate-errors') # 忽略无效证书的问题
driver = webdriver.Chrome(chrome_options=chrome_options)
base_url = 'https://www.amap.com/'
proxy.new_har("amap", options={'captureHeaders': True, 'captureContent': True})
driver.get(base_url)
E:\Anaconda\lib\site-packages\ipykernel_launcher.py:8: DeprecationWarning: use options instead of chrome_options
input = driver.find_element_by_id('searchipt') #获取输入框
input.clear() #清空输入框
input.send_keys("重庆大学B区") #输入关键词
time.sleep(random.randint(10, 30))
select = driver.find_elements_by_class_name("autocomplete-suggestion") #获取联想词框
time.sleep(random.randint(2, 5))
select[0].click() #点击出来的第一个联想词
current_url = driver.current_url
current_url
time.sleep(5)
result = proxy.har
print(result)
IOPub data rate exceeded.
The notebook server will temporarily stop sending output
to the client in order to avoid crashing it.
To change this limit, set the config variable
`--NotebookApp.iopub_data_rate_limit`.
Current values:
NotebookApp.iopub_data_rate_limit=1000000.0 (bytes/sec)
NotebookApp.rate_limit_window=3.0 (secs)
hhh = re.findall('(\d{3}\.\d{6},\d{2}\.\d{6}_)', str(result)) #提取坐标串
print(hhh)
server.stop()
driver.quit()
['106.461922,29.570084_', '106.461969,29.570016_', '106.461177,29.570714_']
借助上面答主介绍的方法来改写爬虫,将杭州市公园信息爬取下来
最后改写的就不放了,大家自己动动手把,按照成功的这个爬取方式做个循环就可以了。
我爬了前20个公园,画了一下图,数据缺失还是比较严重的,有5-6个估计都没有边界的经纬度信息。

前20个公园的分布。
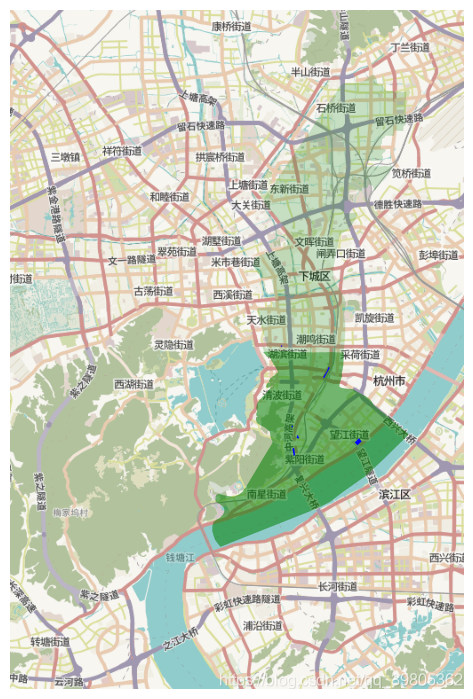
蓝色的小块就是,太小了不大看得见了。


















 596
596

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









