






原论文:openview
PGMA介绍
PGMA(Parameters Generation and Model Adaptation),作者提出的模型与之前的LwF、EWC、iCarL方法大不相同。PGMA不像LwF或EWC,学习一整套的参数,来应对所有的任务。它将分类器的参数分为两部分,一部分为所有任务共享参数集,另一部分为任务特定参数集。对于每一个训练(测试)实例,都为其生成特定的参数集来完成分类等任务。
PGMA由三部分组成:
-
Solver
主要的分类模型。有两套参数,分别是对所有任务共享的参数集 θ 0 \theta_0 θ0,以及任务特定的参数集 H H H。 H H H由DPG针对特定的训练(测试)样本动态生成。 -
Data Generator(DG)
DG有两个作用,主要的作用是来生成过去任务的数据,来抗遗忘。次要作用是来生成嵌入向量 z i z_i zi。
所以DG由两部分组成:Decoder和Encoder,分别用来生成过去的数据和生成嵌入向量。 -
Dynamic Parameter Generator(DPG)
接受训练样本 x i x_i xi,和一个嵌入向量 z i z_i zi,由DG生成。DPG利用 z i z_i zi来产生针对 x i x_i xi的参数集,替换Solver中的 H H H。使用 z i z_i zi而不是用原始数据 x i x_i xi的原因是原始数据的维度可能过高,计算处理起来十分麻烦,所以采用embedding的方式来降低计算复杂度,降低映射空间。
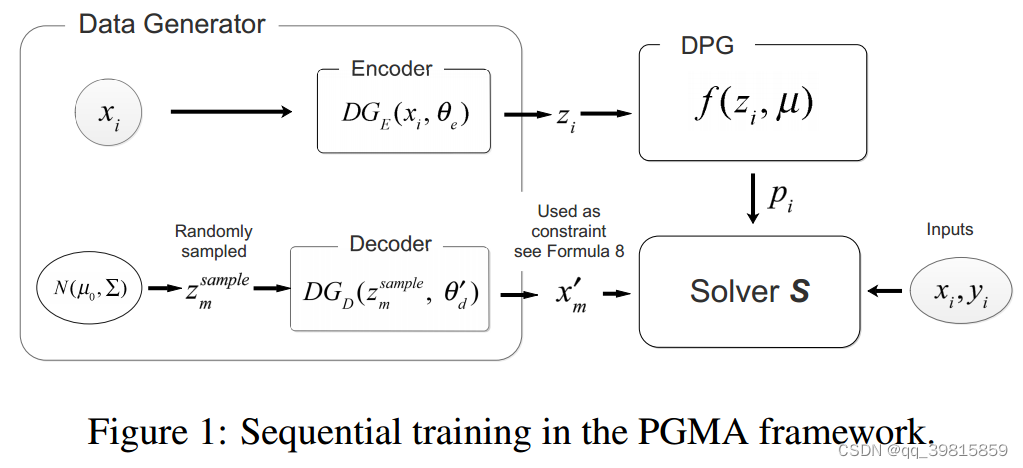
Symbol denotation
x
i
x_i
xi是真实数据集中的数据,
y
i
y_i
yi是
x
i
x_i
xi对应的标签;
z
i
z_i
zi表示嵌入向量;
p
i
p_i
pi表示DPG生成的参数,传递给Solver。
从上图可以看出,DG由两部分组成,分别是
D
G
E
DG_E
DGE和
D
G
D
DG_D
DGD,代表Encoder和Decoder。其中
θ
e
\theta_e
θe表示Encoder网络中的参数,
θ
d
\theta_d
θd表示Decoder网络中的参数。
μ
\mu
μ代表DGP网络中已经训练好的参数,
x
m
′
x_m^{'}
xm′表示生成的过去任务的数据(replayed data)。
Loss function
模型训练的目标是最小化目标函数,继而使模型能够得出理想的结果。PGMA由多个部分组成,所以每个部分都有其相应的Loss function。
对于DPG & S:
minimize
μ
,
θ
0
L
c
e
(
S
(
x
i
,
θ
i
∗
)
,
y
i
)
s.t.
∑
m
=
1
M
∥
R
(
x
m
′
,
θ
i
∗
)
−
R
(
x
m
′
,
θ
i
−
1
∗
)
∥
<
ϵ
r
\begin{aligned} \underset{\mu, \theta_{0}}{\operatorname{minimize}} & \mathcal{L}_{c e}\left(S\left(x_{i}, \theta_{i}^{*}\right), y_{i}\right) \\ \text { s.t. } & \sum_{m=1}^{M}\left\|\mathcal{R}\left(x_{m}^{\prime}, \theta_{i}^{*}\right)-\mathcal{R}\left(x_{m}^{\prime}, \theta_{i-1}^{*}\right)\right\|<\epsilon_{r} \end{aligned}
μ,θ0minimize s.t. Lce(S(xi,θi∗),yi)m=1∑M
R(xm′,θi∗)−R(xm′,θi−1∗)
<ϵr
L
c
e
\mathcal{L}_{ce}
Lce是交叉熵损失函数,要求
μ
\mu
μ和
θ
0
\theta_0
θ0使得
L
c
e
\mathcal{L}_{ce}
Lce最小,但同时要满足第二个式子的条件。
对于DG,先来看一下DG的训练流程:
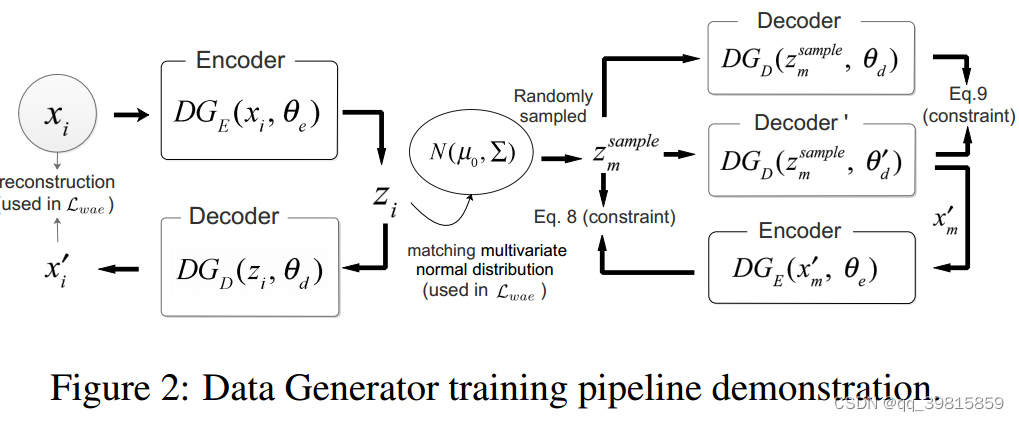
在上图的左半部分,
x
i
x_i
xi经由encode得到
z
i
z_i
zi,然后
z
i
z_i
zi经过decoder之后得到
x
i
′
x_i^{'}
xi′,即重放数据。与原数据
x
i
x_i
xi作比较,计算损失,来提高重放的精度。
右半部分,有两个constraint,还有两个decoder。这两个decoder的不同之处在于其参数不同,一个是
θ
d
\theta_d
θd,一个是
θ
d
′
\theta_d^{'}
θd′。
θ
d
′
\theta_d^{'}
θd′的意思是decoder在对优化(训练)当前任务
T
i
T_i
Ti之前的参数集。
我们可以看到,随机取样的向量z,由两个decoder接收,生成两个重放数据,然后要这两个重放数据的差异最小化,防止遗忘过去的知识(Eq9);同时,将decoder ‘ 产生的重放数据
x
m
′
x_m^{'}
xm′输入进encoder中,解码为向量
z
z
z,与
z
m
s
a
m
p
l
e
z_m^{sample}
zmsample比较,保证取样的稳定性。(Eq8)
E
q
.
8
:
min
∑
m
=
1
M
∥
z
m
sample
−
D
G
E
(
x
m
′
,
θ
e
)
∥
E
q
.
9
:
min
∑
m
=
1
M
∥
D
G
D
(
z
m
sample
,
θ
d
)
−
x
m
′
∥
\begin{array}{l} Eq.8:\min \sum_{m=1}^{M}\left\|\mathbf{z}_{m}^{\text {sample }}-D G_{E}\left(x_{m}^{\prime}, \theta_{e}\right)\right\| \\ \\ Eq.9:\min \sum_{m=1}^{M}\left\|D G_{D}\left(\mathbf{z}_{m}^{\text {sample }}, \theta_{d}\right)-x_{m}^{\prime}\right\| \end{array}
Eq.8:min∑m=1M
zmsample −DGE(xm′,θe)
Eq.9:min∑m=1M
DGD(zmsample ,θd)−xm′
PGMA完整训练流程
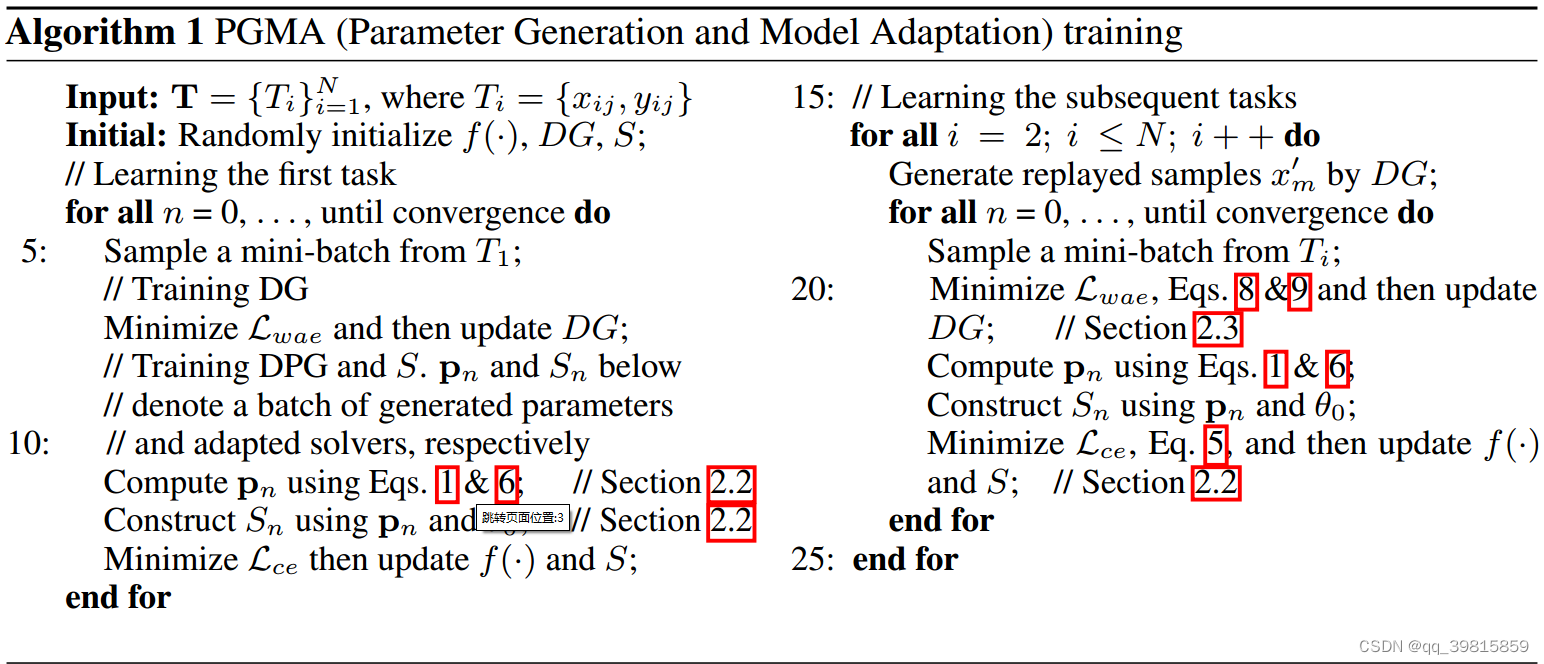
左半部分是对于第一个任务学习时,因为一开始没有先前的学习经验,所以对于第一个任务需要单独处理。
右半部分是对剩余的任务的学习,可以看出两部分的步骤有较大的重叠。
对于实验部分,作者使用MNIST数据集和CIFAR-10数据集用来做图像分类任务。类别不多,训练过程较为容易。不再赘述。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









