






InfoNCE(Noise Contrastive Estimation)和交叉熵损失都是两个关键的概念。它们不仅在衡量概率分布之间的差异方面发挥着重要作用,而且在深度学习的自监督学习领域扮演着重要角色。虽然它们的形式和应用环境有所不同,但是我们可以发现它们之间存在着微妙的联系。
InfoNCE Loss(Noise Contrastive Estimation Loss)是一种用于自监督学习的损失函数,通常用于学习特征表示或者表征学习。它基于信息论的思想,通过对比正样本和负样本的相似性来学习模型参数。
InfoNCE Loss 公式
InfoNCE 损失的计算公式如下:
L
N
C
E
=
−
1
N
∑
i
=
1
N
log
exp
(
P
i
,
p
o
s
/
τ
)
∑
k
exp
(
P
i
,
k
/
τ
)
\mathcal{L}_{NCE} = -\frac{1}{N} \sum_{i=1}^N \log\frac{\exp(P_{i, pos}/\tau)}{\sum_k \exp(P_{i,k}/\tau)}
LNCE=−N1i=1∑Nlog∑kexp(Pi,k/τ)exp(Pi,pos/τ)
其中 P i , p o s P_{i,pos} Pi,pos表示第i个样本与其正样本的相似性/距离,log右侧整体为正样本的概率分布。
CLIP中用到的对比损失就是典型的InfoNCE Loss,其正样本对在相似性矩阵的对角线上。
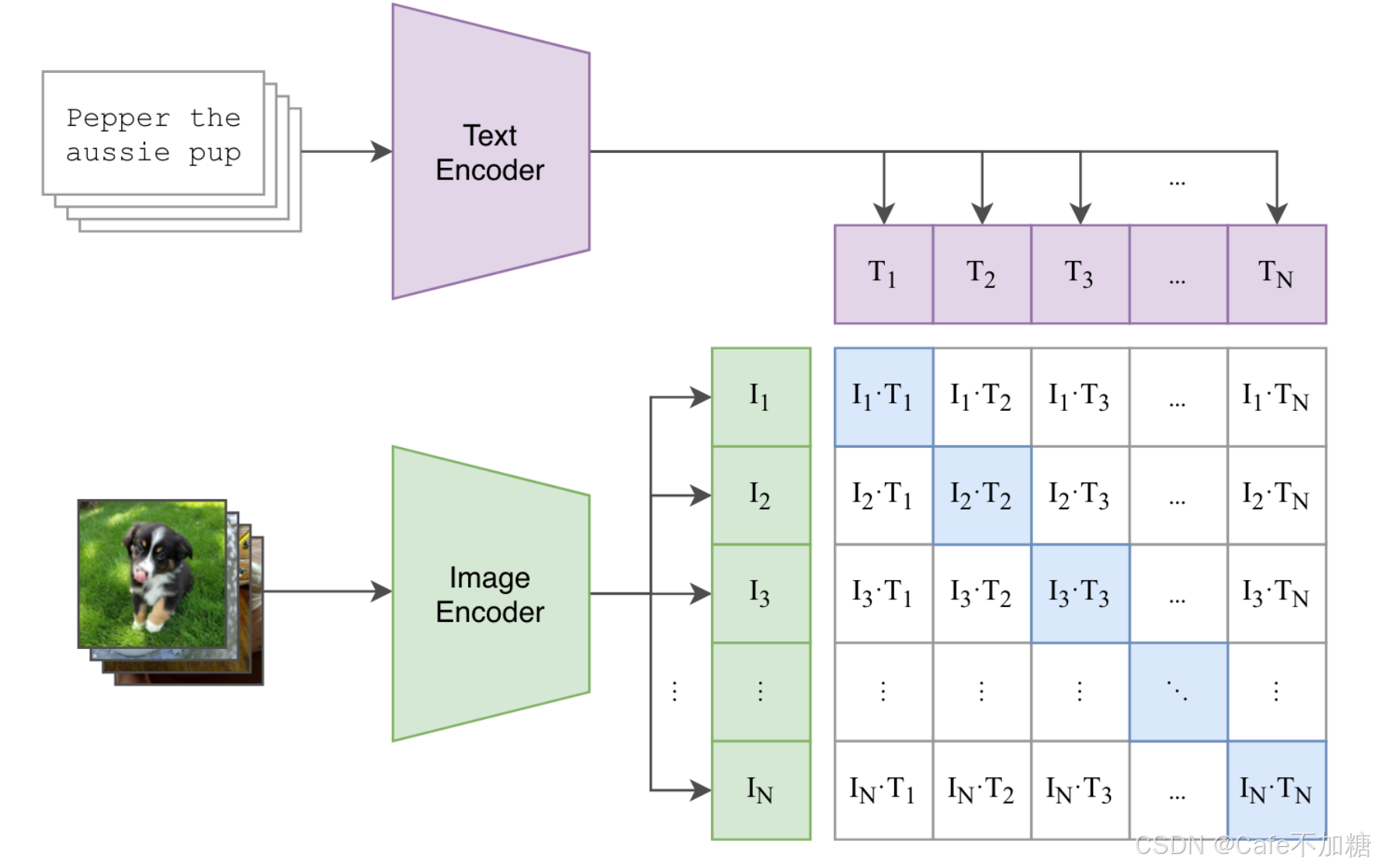

InfoNCE损失在自监督学习场景下也发挥着重要的作用。在此以多视角自监督对比学习举例。
对于一个批次的数据 X ∈ R n × c × w × h X\in \mathbb{R}^{n\times c\times w\times h} X∈Rn×c×w×h,我们计算其两个视角的图像特征 F , F ′ F,F' F,F′。随后计算相似性矩阵 S = F ⋅ F T S = F\cdot F^T S=F⋅FT,其中 F ∈ R n × d F \in \mathbb{R}^{n\times d} F∈Rn×d。
在
S
S
S中,对于一个样本数据
x
i
x_i
xi,其正样本为它的第二个视角数据
x
i
′
x_i'
xi′ 以及其自身。得到
S
S
S之后,我们需要对其进行修改,抹去对角线元素,拉近样本与其第二个视角数据的相似性。
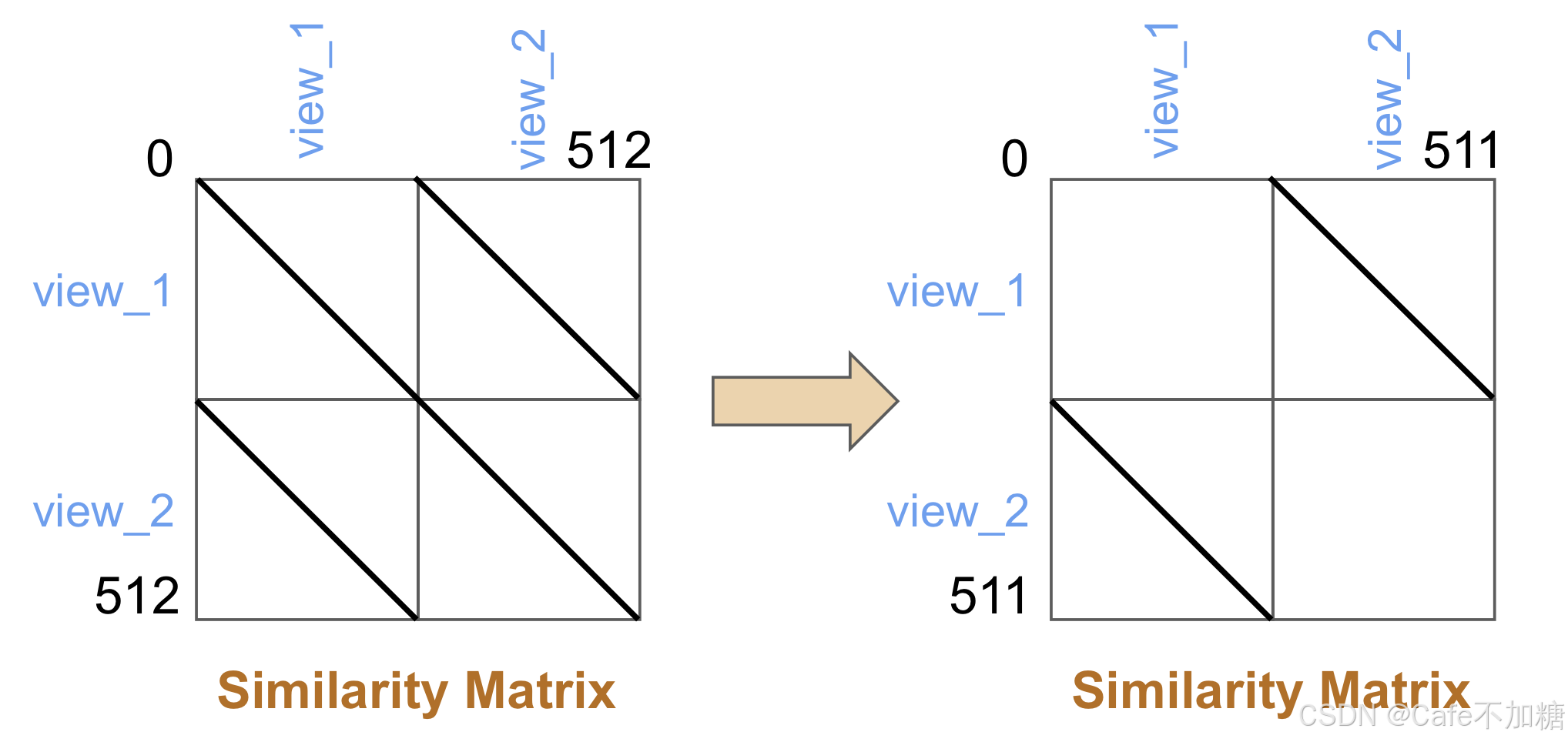
在上图所示的相似性矩阵中,左上角表示view_1的数据与view_1的数据的相似性矩阵,右上角表示view_1的数据与view_2的数据的相似性矩阵,其他以此类推。数字0,512,511表示 S S S的维度。
然后我们从中筛选出正样本对的相似性分数向量 p o s ∈ R ( n − 1 ) × 1 pos \in \mathbb{R}^{(n-1)\times1} pos∈R(n−1)×1,负样本对的相似性分数向量 n e g = ∈ R ( n − 1 ) × ( n − 1 ) neg = \in \mathbb{R}^{(n-1) \times (n-1)} neg=∈R(n−1)×(n−1),构成概率分布 logits = [ p o s , n e g ] ∈ R ( n − 1 ) × n \text{logits} = [pos, neg] \in \mathbb{R}^{(n-1) \times n} logits=[pos,neg]∈R(n−1)×n。因为正样本设置在logits开头处,我们构造标签为长度为 n 的向量 y ∈ R ( n − 1 ) y \in \mathbb{R}^{(n-1)} y∈R(n−1),其中所有元素为0,计算logits与y的CE损失即可得到目标损失。
具体代码实现
def info_nce_logits(features, batch_size, n_views=2, temperature=1.0):
"""
It is assumed that features are aggregated so the first of all the images is first,
then the second view of all images and so on
So e.g. for args.n_views == 3, features = [x_1, x_2, ..., x_1', x_2', ..., x_1'', x_2'', ...]
"""
device = features.device
labels = torch.eye(batch_size, dtype=torch.bool, device=device).repeat(n_views, n_views)
# labels is a correspondence matrix: do the features come from the same image?
features = F.normalize(features, dim=1)
similarity_matrix = torch.matmul(features, features.T)
# discard the main diagonal from both: labels and similarities matrix
mask = ~torch.eye(labels.shape[0], dtype=torch.bool, device=device) # False on the diagonal, True elsewhere
labels = labels[mask].view(labels.shape[0], -1)
similarity_matrix = similarity_matrix[mask].view(similarity_matrix.shape[0], -1)
# select and combine multiple positives
positives = similarity_matrix[labels].view(labels.shape[0], -1)
# select only the negatives the negatives
negatives = similarity_matrix[~labels].view(labels.shape[0], -1)
logits = torch.cat([positives, negatives], dim=1)
labels = torch.zeros(logits.shape[0], dtype=torch.long, device=device)
logits = logits / temperature
return logits, labels

















 1635
1635

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









