







 Bootstrapping是一种统计方法,用于估计参数的分布并确定置信区间。它通过从有限样本中进行多次有放回抽样来创建新样本,进而估算统计量的分布。在机器学习和深度学习中,该方法可用于计算实验结果的p值。通过在测试集中进行随机抽样,可以获取关于特定指标的平均值,以此计算p值。
Bootstrapping是一种统计方法,用于估计参数的分布并确定置信区间。它通过从有限样本中进行多次有放回抽样来创建新样本,进而估算统计量的分布。在机器学习和深度学习中,该方法可用于计算实验结果的p值。通过在测试集中进行随机抽样,可以获取关于特定指标的平均值,以此计算p值。
Bootsrapping指的就是利用有限的样本资料经由多次重复抽样,重新建立起足以代表母体样本分布的新样本。
统计中我们常常需要做参数估计,具体问题可以描述为:给定一系列数据
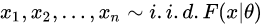
假设它们是从分布F中采样得到的,参数估计就是希望估计分布F中的θ。θ可以是均值,标准差(Standard Deviation),标准误差(Standard Error)。
bootstrapping算法的目的就是为了估计从而得到的分布的预测。具体地,它的思想对已有的观测值进行多次重复的抽样,每次抽样都可以得到一个预测的经验分布函数,根据这些不同抽样得到的经验分布函数,可以得到一个更好的关于统计量分布的估计。
打个比方,如果现在有N个学生的身高数据,需要估计的统计量是学生的平均身高。bootstraping的方法可以替我们确定身高平均值的置信区间。步骤大致如下:
1.从N个数据中随机抽取M个数据(有放回)构成一个样本
2.计算每个样本的均值
3.重复步骤1,2知道计算足够多的次数(至少多于20-30次)
根据这些步骤得到的100次结果,我们可以得出95%的置信区间,即覆盖了95%的样本均值的区间。换言之,超出这个范围的身高均值,出现的次数都小于5%,也可以说它的p值<0.05。以上所说的可以理解为bootstrapping百分位法,它假设样本均值与总体均值的分布大致相似,但这个假设在现实中很难保证成立。
总结
- 确定数据集数据量N
- 确定每次抽取数据M的大小(M≤N)</
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1878
1878











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









