







 本文解析了LeetCode上一道关于单词序列转换的难题,通过广度优先搜索(BFS)算法,寻找从一个单词开始,经过最少步骤转换到目标单词的所有路径。详细介绍了算法思路及代码实现。
本文解析了LeetCode上一道关于单词序列转换的难题,通过广度优先搜索(BFS)算法,寻找从一个单词开始,经过最少步骤转换到目标单词的所有路径。详细介绍了算法思路及代码实现。
首先透露一下,本人在2018年参加南京大学本科生开放日(保研夏令营)的机试时,此题目为三道机试题中的一题,十个测试样例,看你AC了几个样例。当时基本没怎么准备,看到题目时一脸懵,今天竟然又让我在LeetCode上碰到了。
题目描述
给定两个单词(beginWord 和 endWord)和一个字典 wordList,找出所有从 beginWord 到 endWord 的最短转换序列。转换需遵循如下规则:
- 每次转换只能改变一个字母。
- 转换过程中的中间单词必须是字典中的单词。
说明:
- 如果不存在这样的转换序列,返回一个空列表。
- 所有单词具有相同的长度。
- 所有单词只由小写字母组成。
- 字典中不存在重复的单词。
- 你可以假设
beginWord和endWord是非空的,且二者不相同。
示例 1:
输入:
beginWord = "hit",
endWord = "cog",
wordList = ["hot","dot","dog","lot","log","cog"]
输出:
[
["hit","hot","dot","dog","cog"],
["hit","hot","lot","log","cog"]
]
示例 2:
输入:
beginWord = "hit"
endWord = "cog"
wordList = ["hot","dot","dog","lot","log"]
输出: []
解释: endWord "cog" 不在字典中,所以不存在符合要求的转换序列。
解题思路
本题目采用广度优先搜索(BFS)的方法,因此利用队列来存储单词序列。
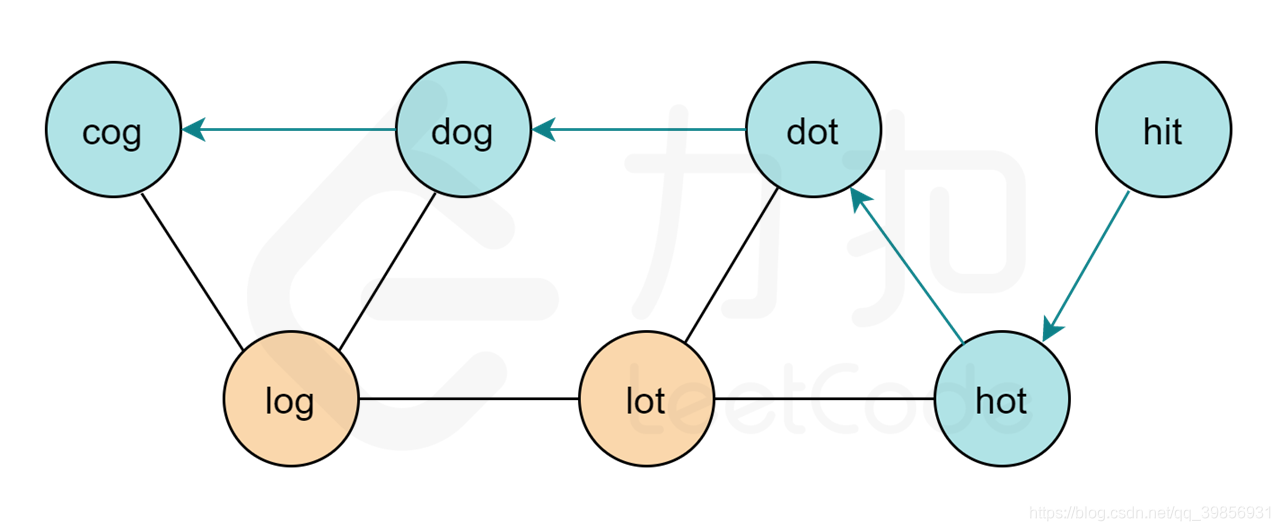
为方便起见,我们利用哈希表给单词标号,操作单词编号,发现到达终点时再输出单词序列。
为了保留相同长度的多条路径,我们采用 cost 数组,其中 cost[i] 表示 beginWord 对应的点到第i个点的代价(即转换次数)。初始情况下其所有元素初始化为无穷大。
- 若该节点为终点,则将其路径转换为对应的单词存入答案;
- 若该节点不为终点,则遍历和它连通的节点(假设为 next )中满足
cost[next] >= cost[now] + 1的加入队列,并更新cost[next] = cost[now] + 1。如果cost[next] < cost[now] + 1,说明这个节点已经被访问过,不需要再考虑。
以上思路参考:LeetCode官方。
具体实现细节可见代码及其注释。
注:
bool checkDifference(string& str1, string& str2)函数的参数需要加引用,不然会超出时间限制。
具体代码
class Solution {
public:
//判断两个字符串是否相等
bool checkDifference(string& str1, string& str2) {
int difference = 0;
for (int i = 0; i<str1.size() && difference <= 1; i++) {
if (str1[i] != str2[i]) difference++;
}
return difference == 1;
}
vector<vector<string>> findLadders(string beginWord, string endWord, vector<string>& wordList) {
unordered_map<string, int>wordId;//利用哈希表记录单词表中的词
vector<string>words;//记录所有的单词
vector<vector<int>>edge;//记录每个单词相邻的单词id
int id = 0;//单词的编号
//利用哈希表记录单词
for (const string& word : wordList) {
if (!wordId.count(word)) {
wordId[word] = id++;
words.push_back(word);
}
}
//如果最终的单词不在wordId中,直接返回{}
if (wordId.count(endWord) == 0) return {};
//如果起始单词不在wordId中,将其加入
if (wordId.count(beginWord) == 0) {
wordId[beginWord] = id++;
words.push_back(beginWord);
}
//为edge赋值(找相邻单词)
edge.resize(words.size());//重新赋值edge数组大小
for (int i = 0; i<words.size(); i++) {
for (int j = i + 1; j<words.size(); j++) {
if (checkDifference(words[i], words[j])) {
edge[i].push_back(j);
edge[j].push_back(i);
}
}
}
//寻找全部路径,利用广度优先搜索
int dest = wordId[endWord];
queue<vector<int>>que;//定义一个队列用于存放当前的所有路径
vector<vector<string>>ans;//存放最终的答案
vector<int>cost(words.size(), INT_MAX);//找代价最小的路径,先赋值为最大
cost[wordId[beginWord]] = 0;//将起始点的代价设为0
que.push(vector<int>{wordId[beginWord]});//将起始点放进que
while (que.empty() == 0) {
vector<int>now = que.front();//当前队列中的遍历顺序
que.pop();
int last = now.back();//当前的队尾元素
//如果队尾元素就是终点单词
if (last == dest) {
vector<string>tmp;
//将now中的id映射成word后放入ans中
for (int i = 0; i<now.size(); i++)
tmp.push_back(words[now[i]]);
ans.push_back(tmp);
}
//如果不是终点单词还要继续查找
else {
for (int i = 0; i<edge[last].size(); i++) {
int next = edge[last][i];
//如果下一个相邻单词的代价大于当前单词(保证最短路径)
if (cost[last] + 1 <= cost[next]) {
cost[next] = cost[last] + 1;
//将新的序列加入到队列中进行判断。
vector<int>tmp(now);
tmp.push_back(next);
que.push(tmp);
}
}
}
}
return ans;
}
};
性能结果



















 361
361

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









