









环境为pytorch
在Jupyter中运行
1.导入包与数据集
(这里的数据集是28 X 28的灰度像素值组成,所有图像共分为10个类别)

代码解释
import torch
from torch import nn
from d2l import torch as d2l
batch_size = 256 #批量大小等于256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)#训练和测试集
2.初始化模型参数

代码解释
这里我们设置一层隐藏层
num_inputs, num_outputs, num_hiddens = 784, 10, 256 #输入,输出,隐藏层
W1 = nn.Parameter(torch.randn( #w(隐藏层权重),行数是输入大小(784),列数是隐藏层大小(256),要更新,算梯度
num_inputs, num_hiddens, requires_grad=True) * 0.01)
b1 = nn.Parameter(torch.zeros(num_hiddens, requires_grad=True))#偏差,向量,大小为隐藏层的大小,全0,算梯度
W2 = nn.Parameter(torch.randn(#输出层权重,行数256,列数10,算梯度
num_hiddens, num_outputs, requires_grad=True) * 0.01)
b2 = nn.Parameter(torch.zeros(num_outputs, requires_grad=True))#大小10 ,因为要分10类,算梯度
params = [W1, b1, W2, b2]
3.设置激活函数
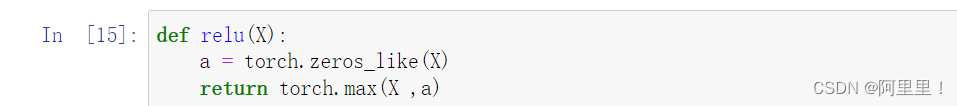
代码解释
其实这个relu激活函数的本质就是一个MAX函数
def relu(X):
a = torch.zeros_like(X) #生成一个和X形状完全一样,但是元素值完全为0
return torch.max(X, a) #求最大值
4.定义模型

代码解释:
def net(X):
X = X.reshape((-1, num_inputs)) #本来是28*28的图片,拉成一个784的矩阵
H = relu(X@W1 + b1) # 这里“@”代表矩阵乘法
return (H@W2 + b2) #输出就是第一层的输出和第二层的权重做乘法,再加上偏差
5.损失函数

loss = nn.CrossEntropyLoss(reduction='none')
6.训练

代码解释:
num_epochs, lr = 10, 0.1 #跑10次,学习率为0.1
d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs,
#train_ch3一个训练算法,传入我们的模型,和训练集,数据集。损失函数,以及训练次数,还有sgd内置优化函数
lambda batch_size: d2l.sgd(params, lr, batch_size))
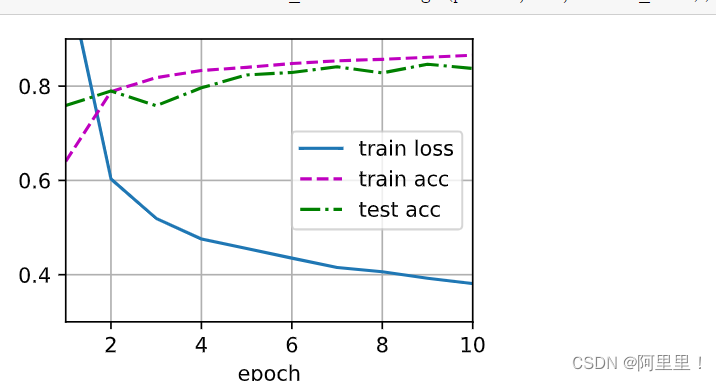
结果展示:
初学啦,有什么问题可以指出来,谢谢















 352
352











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









