









多层感知机的从零开始实现
多层感知机,通过向输入层和输出层中间添加多个隐藏层(Hidden),使其能处理更普遍的函数关系类型,预测可信度更高。
直观理解图
原理图如下:
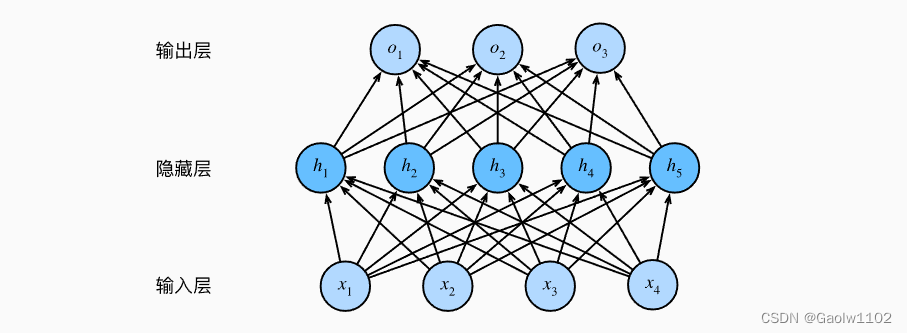
注意,这个多层感知机有4个输入,3个输出,其隐藏层包含5个隐藏单元。
输入层不涉及任何计算,因此使用此网络产生输出只需要实现隐藏层和输出层的计算。 因此,这个多层感知机中的层数为2。 注意,这两个层都是全连接的。 每个输入都会影响隐藏层中的每个神经元, 而隐藏层中的每个神经元又会影响输出层中的每个神经元。
推导公式
我们都知道,之前学习的softmax回归模型或者线性模型仅包含输入输出,是直接通过仿射函数完成的,如下公式。
o u t p u t s = X ⃗ ⋅ W ⃗ + b outputs = \vec{X} \cdot \vec{W} + b outputs=X⋅W+b
其中,X为样本向量,每个标量即为一个特征。W为特征权重向量,每个标量对应特征的权重。b为偏置量。
通过该式子计算便可以得到一个预测值或概率分布。
那么现在,我们已经向输入层和输出层增加了隐藏层(Hidden),则现在预测公式即为
H
=
X
⋅
W
1
+
b
1
H = X \cdot W_{1} + b_{1}
H=X⋅W1+b1
o
u
t
p
u
t
s
=
H
⋅
W
2
+
b
2
outputs = H \cdot W_{2} + b_{2}
outputs=H⋅W2+b2
这是一个具有单隐层的多层感知机的实现公式(多层感知器套用多个 H H H 即可),其中 H H H 即为隐层, W 1 和 b 1 W_{1}和b_{1} W1和b1是输入层到隐层的权重和偏置, W 2 和 b 2 W_{2}和b_{2} W2和b2是隐层到输出层的权重和偏置,经过多层运算,即可得到最终结果。
动手实现多层感知机
若对下面的某些函数实现感到困惑,请看图像分类数据集和从零开始实现softmax回归着两篇文章,均包含函数算法详细实现过程。
现在让我们尝试自己实现一个多层感知机。 为了与之前softmax回归获得的结果进行比较, 我们将继续使用Fashion-MNIST图像分类数据集 。
import torch #引入torch包
from torch import nn #引入神经网络
from d2l import torch as d2l
batch_size = 256 #小批量样本大小为256
#获取训练集迭代器和测试集迭代器
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size) #该方法在《图像分类数据集》中实现
初始化模型参数
回想一下,Fashion-MNIST中的每个图像由 28 × 28 = 784 28 \times 28 = 784 28×28=784 个灰度像素值组成。 所有图像共分为10个类别。 忽略像素之间的空间结构, 我们可以将每个图像视为具有784个输入特征 和10个类的简单分类数据集。 首先,我们将实现一个具有单隐藏层的多层感知机, 它包含256个隐藏单元。 注意,我们可以将这两个变量都视为超参数。 通常,我们选择2的若干次幂作为层的宽度。 因为内存在硬件中的分配和寻址方式,这么做往往可以在计算上更高效。
我们用几个张量来表示我们的参数。 注意,对于每一层我们都要记录一个权重矩阵和一个偏置向量。 跟以前一样,我们要为损失关于这些参数的梯度分配内存。
num_imputs = 784 #输入特征个数
num_outputs = 10 #输出类别个数
num_hiddens = 256 #隐层的宽度,即隐单元的个数,256个
W1 = nn.Parameter(torch.randn(
num_imputs, num_hiddens, requires_grad=True)*0.1) #定义输入层与隐层之间的权重矩阵, 即(784, 256)
b1 = nn.Parameter(torch.zeros(num_hiddens, requires_grad=True)) #定义输入层与隐层之间的偏置量,长度为256
W2 = nn.Parameter(torch.randn(
num_hiddens, num_outputs, requires_grad=True)*0.1) #定义隐层与输出层之间的权重矩阵,即(256, 10)
b2 = nn.Parameter(torch.zeros(num_outputs, requires_grad=True)) #定义隐层与输出层之间的偏置量,长度为10
params = [W1, b1, W2, b2] #均作为网络模型的参数
激活函数
为了确保我们对模型的细节了如指掌, 我们将实现ReLU激活函数(即舍弃负数), 而不是直接调用内置的relu函数。
def relu(X):
a = torch.zeros_like(X) #同X形状一致的全0矩阵
return torch.max(X, a) #通过max()函数实现X矩阵去除负数的效果
模型
因为我们忽略了空间结构, 所以我们使用reshape将每个二维图像转换为一个长度为num_inputs的向量。 只需几行代码就可以实现我们的模型。
def net(X):
X = X.reshape((-1, num_imputs)) #对X进行形状重塑,使其符合矩阵相乘
H = relu(X@W1 + b1 ) #首先计算输入层到隐层的结果,记得一定要使用激活函数预处理数据
return H@W2 + b2 #再计算隐层到输出层的结果
损失函数
由于我们已经从零实现过softmax函数, 因此在这里我们直接使用高级API中的内置函数来计算softmax和交叉熵损失。
loss = nn.CrossEntropyLoss(reduction='none') #定义内置的交叉熵损失函数,保持数据稳定性,torch.nn内部API算法
训练
幸运的是,多层感知机的训练过程与softmax回归的训练过程完全相同。 可以直接调用d2l包的train_ch3函数(不懂可以看这里,从零实现softmax回归), 将迭代周期数设置为10,并将学习率设置为0.1.
num_epochs = 10 #迭代次数选择为10
lr = 0.1 #学习率为0.1
updater = torch.optim.SGD(params, lr) #定义优化函数,更新神经网络内的参数,即[W1,b1,W2,b2],torch内梯度下降算法
#开始训练模型,参数分别为神经网络、训练集迭代器、测试集迭代器、损失函数、迭代次数、优化函数
#《从零开始实现softmax回归模型》文章中有详细实现过程
d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, updater)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-aQVFVQ7a-1664235853809)(output_32_0.svg)]](https://img-blog.csdnimg.cn/2aaed17fe38d4f388dbd6502d53fedda.png)
预测结果
为了对学习到的模型进行评估,我们将在一些测试数据上应用这个模型。
# 预测6个图片的标签
#《从零开始实现softmax回归模型》文章中有该函数详细实现过程
d2l.predict_ch3(net, test_iter)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-jniuIZDr-1664235853810)(output_35_0.svg)]](https://img-blog.csdnimg.cn/5099ea81ff1849dd993bd85abe4ae240.png)
小结
手动实现一个简单的多层感知机是很容易的。然而如果有大量的层,从零开始实现多层感知机会变得很麻烦(例如,要命名和记录模型的参数)。
另外,多层感知机(MLP) 是深度学习流行模型的简单思想概括,深刻理解该模型将非常有助于其它深度学习模型的学习。
















 2174
2174











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











