







一、覆盖索引
尽量使用覆盖索引,减少 select *。 那么什么是覆盖索引呢? 覆盖索引是指查询使用了索引,并且需要返回的列,在该索引中已经全部能够找到 。
之前我们所研究的是where之后的条件该怎么去写,怎么去规避索引失效,此时我们要来研究的是查询需要返回的字段,即select这一部分。
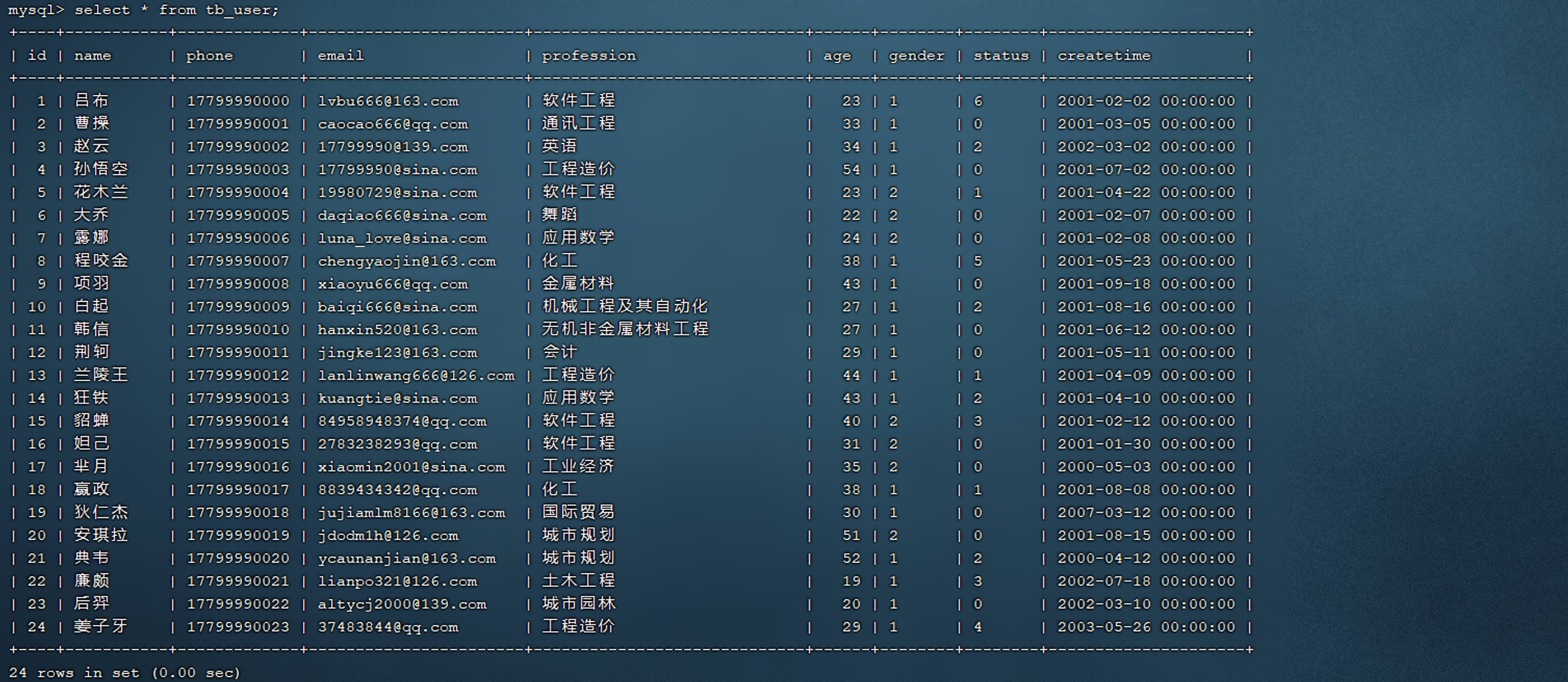
目前tb_user表的数据情况如下:
索引情况如下:

把上述的 idx_user_age, idx_email 这两个之前测试使用过的索引直接删除。
drop index idx_user_age on tb_user;
drop index idx_email on tb_user;
接下来,我们来看一组SQL的执行计划,看看执行计划的差别,然后再来具体做一个解析。
explain select id, profession from tb_user where profession = '软件工程' and age = 31 and status = '0' ;
explain select id,profession,age, status from tb_user where profession = '软件工程' and age = 31 and status = '0' ;
explain select id,profession,age, status, name from tb_user where profession = '软件工程' and age = 31 and status = '0' ;
explain select * from tb_user where profession = '软件工程' and age = 31 and status = '0';
上述这几条SQL的执行结果为:

从上述的执行计划我们可以看到,这四条SQL语句的执行计划前面所有的指标都是一样的,看不出来差异。但是此时,我们主要关注的是后面的Extra,前面两条SQL的结果为 Using where; Using Index ; 而后面两条SQL的结果为: Using index condition 。
当然Extra中出现的信息大家不用去记,因为如果你使用的MySQL版本不同,Extra所出现的值、展现的形式也是不同的。
| Extra | 含义 |
|---|---|
| Using where; Using Index | 查找使用了索引,但是需要的数据都在索引列中能找到,所以不需要回表查询数据(性能更高) |
| Using index condition | 查找使用了索引,但是需要回表查询数据(性能更低) |
在前面讲解聚集索引&二级索引的时候,有一个概念叫:回表。
回表查询: 这种先到二级索引中查找数据,找到主键值,然后再到聚集索引中根据主键值,获取数据的方式,就称之为回表查询。
因为,在tb_user表中有一个联合索引 idx_user_pro_age_sta,该索引关联了三个字段 profession、age、status,而这个索引也是一个二级索引,所以叶子节点下面挂的是这一行的主键id。 所以当我们查询返回的数据在 id、profession、age、status 之中,则直接走二级索引 直接返回数据了。 如果超出这个范围,就需要拿到主键id,再去扫描聚集索引,再获取额外的数据 了,这个过程就是回表。 而我们如果一直使用select * 查询返回所有字段值,很容易就会造成回表查询(除非是根据主键查询,此时只会扫描聚集索引)。
为了大家更清楚的理解,什么是覆盖索引,什么是回表查询,我们一起再来看下面的这组SQL的执行过程。
二、执行过程
A. 表结构及索引示意图:
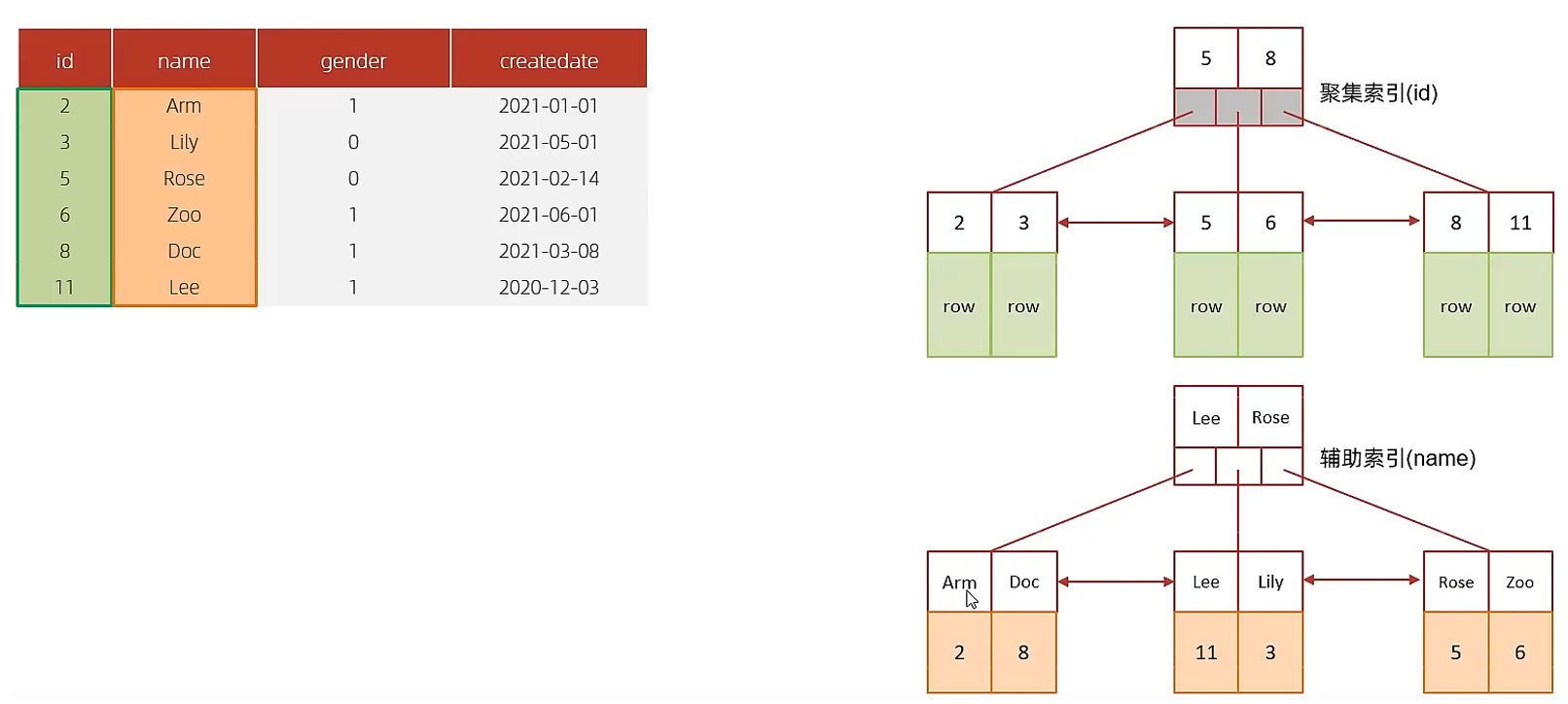
id是主键,是一个聚集索引。 name字段建立了普通索引,是一个二级索引(辅助索引)。
B. 执行SQL : select * from tb_user where id = 2;
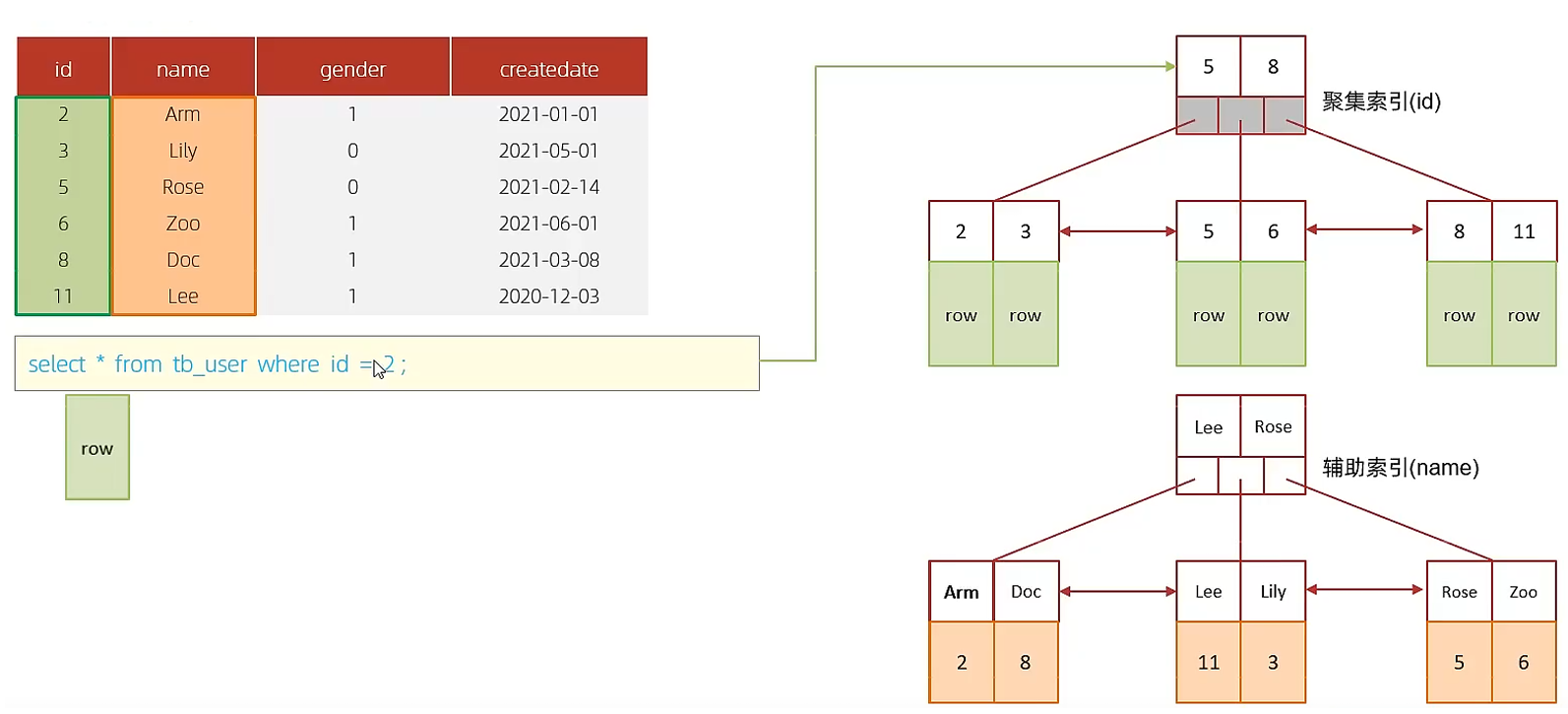
根据id查询,直接走聚集索引查询,一次索引扫描,直接返回数据,性能高。
C. 执行SQL:select id,name from tb_user where name = 'Arm';

虽然是根据name字段查询,查询二级索引,但是由于查询返回在字段为 id,name,在name的二级索引中,这两个值都是可以直接获取到的,因为覆盖索引,所以不需要回表查询,性能高。
D. 执行SQL:selet id,name,gender from tb_user where name = 'Arm';
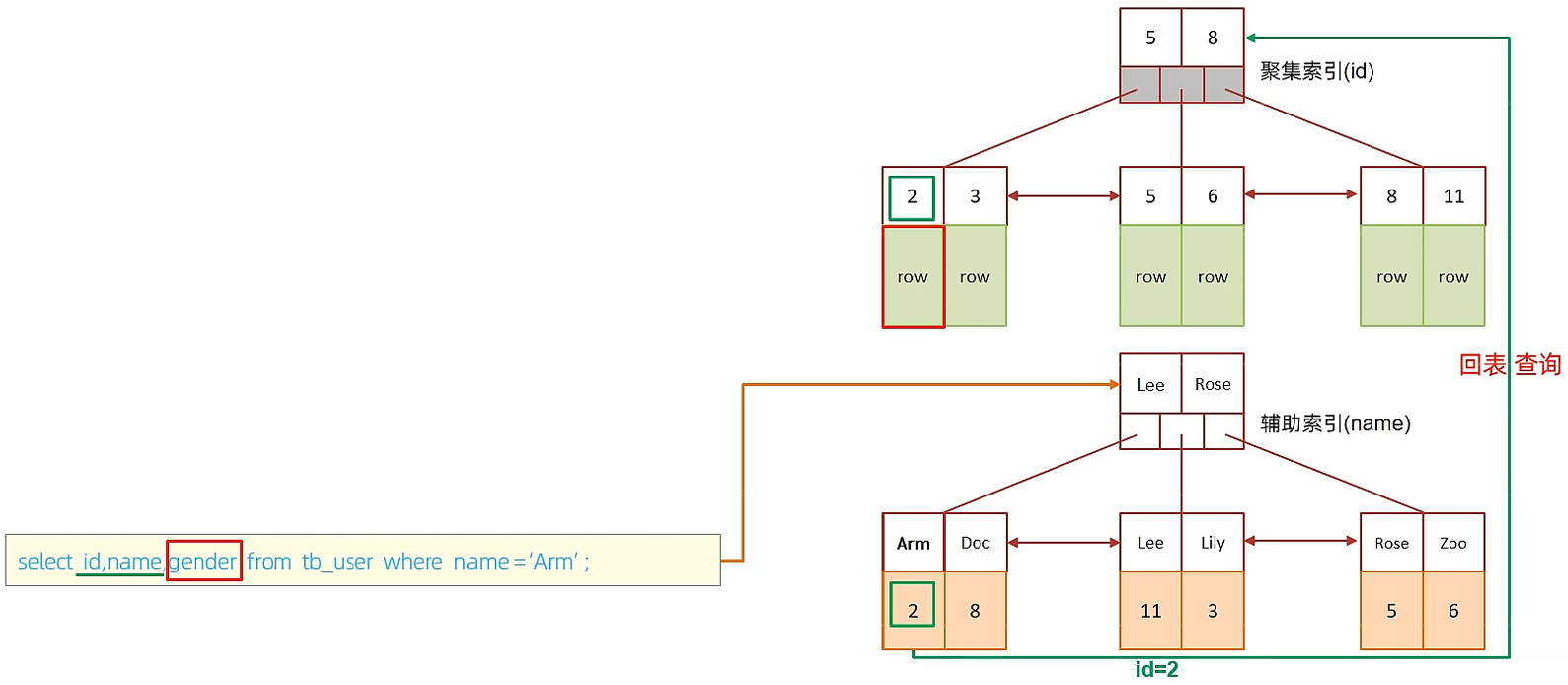
由于在name的二级索引中,不包含gender,所以,需要两次索引扫描,也就是需要回表查询,性能相对较差一点。
避免使用 select * ,原因是很容易就出现回表查询,除非你创建一个联合索引,这个联合索引包含这张表的所有字段,否则就极易出现回表查询的情况,性能就会降低。
三、思考题
一张表, 有四个字段(id, username, password, status), 由于数据量大, 需要对 以下SQL语句进行优化, 该如何进行才是最优方案:
select id,username,password from tb_user where username = 'itcast';
答案: 针对于 username, password 建立联合索引, sql为: create index idx_user_name_pass on tb_user(username,password);
这样可以避免上述的SQL语句,在查询的过程中,出现回表查询。
















 1442
1442

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









