







一、引出问题
如下图,可以很明显发现遇见了问题,我写进去的明明是虎哥,而取出来的却是Rose呢?

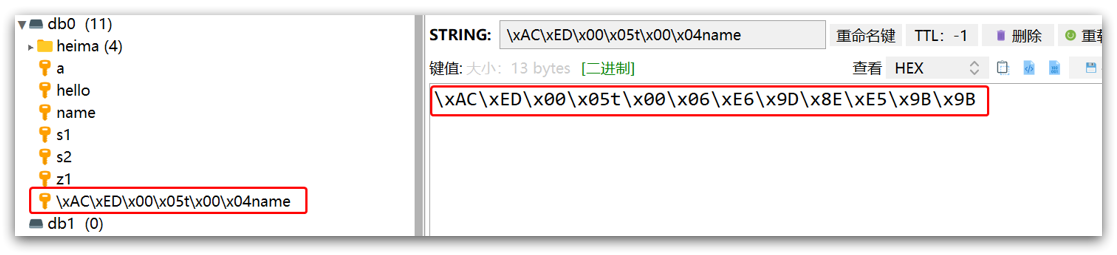
通过 keys * 来查看一下,可以发现有一个叫 name 的key,还有一个叫 "\xac\xed\x00\x05t\x00\x04name" 的key,这个key最后有一个name。
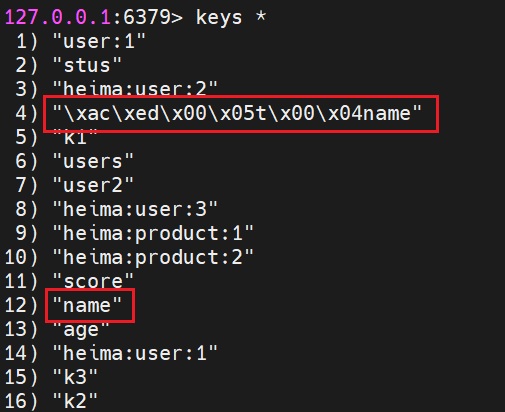
我们来查询,发现得到了下面这串东西,可以发现看不懂。
那我告诉你这就是虎哥,虎哥怎么变成这样了?

它被剁碎了,这就要说到序列化了。
二、默认JDK序列化器 + 源码查看
可以看见,RedisTemplate 的key接收的并不是字符串,而是Object,这个是我们之前讲过的 Spring Data 的一个特殊功能,它可以接收任何类型的对象,然后帮我们转成redis可以处理的字节,因此我们存进去的 "name" 和 "虎哥" 都被当成Java对象了,而RedisTemplate底层默认对这些对象的处理方式就是利用JDK的序列化工具 ObjectOutputStream,我们可以来看看 RedisTemplate 的原码。
在它里面有四个东西:keySerializer:key的序列化器;valueSerializer:value的序列化器;hashKeySerializer、hashValueSerializer:对哈希里面的字段的键值序列化器。
由此可见,我们利用 RedisTemplate 存入的一切数据,最终都会利用这四个东西做序列化和反序列化。
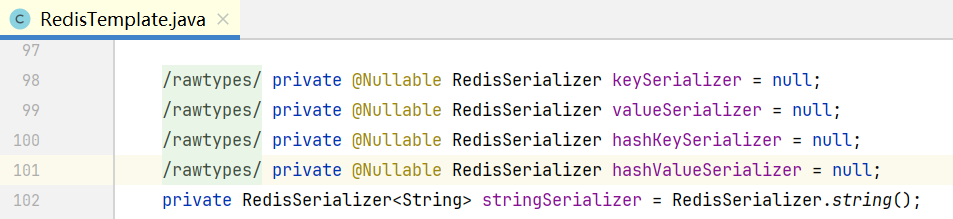
这四个东西现在都是null,那么谁给它做初始化的呢?
往下滑,在 afterPropertiesSet()方法 中会给它创建一个默认的序列化器,而默认的序列化器就是JDK的序列化器。
在你没有给这几个值进行自定义的情况下,它就会走这个默认的JDK序列化器。
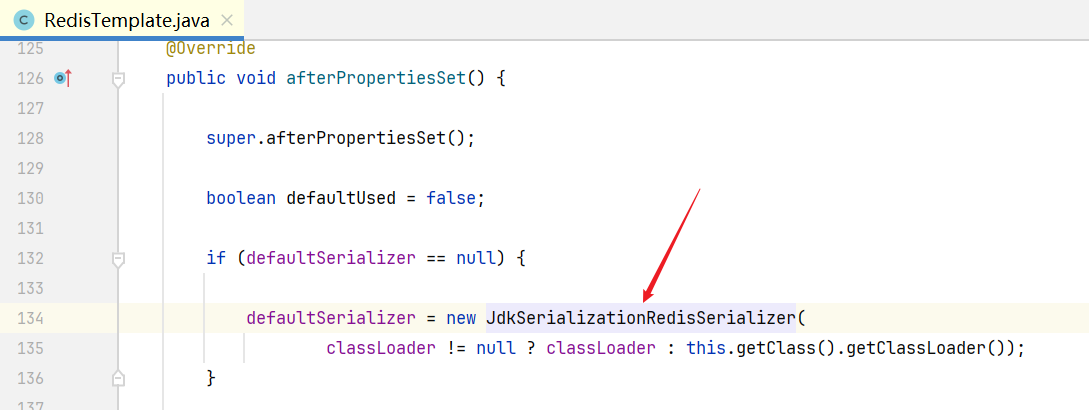
你可以在这一行打上一个断点,然后debug运行一下,跟进 set()方法

传进来的key-value会被 rawValue() 装饰(raw),跟进 rawValue()方法
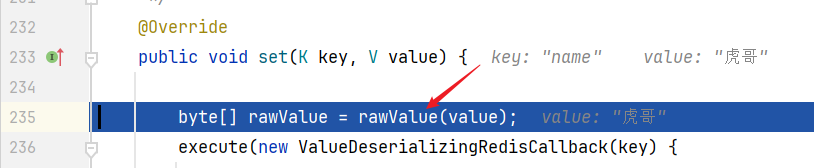
跟进来后往下走,它会尝试获取 valueSerializer,即我们刚刚看见的值序列化器,我们跟入 serialize(value)方法
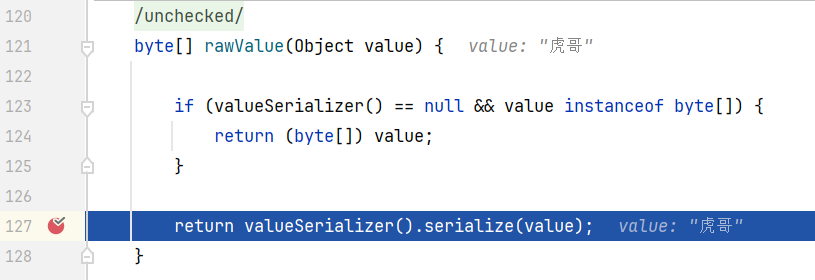
此时发现,直接进入到了JDK的 Serialization,就是我们刚刚看见的默认的JDK序列化工具。
JDK的底层序列化用的是 ObjectOutputStream。往下,跟进convert()方法
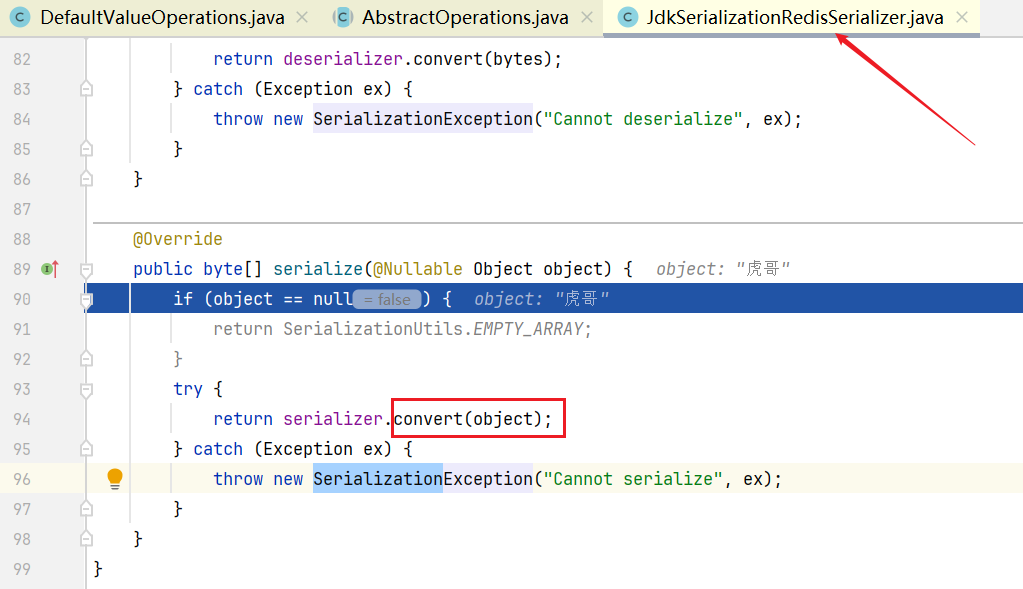
继续跟进 serializeToByteArray(source)

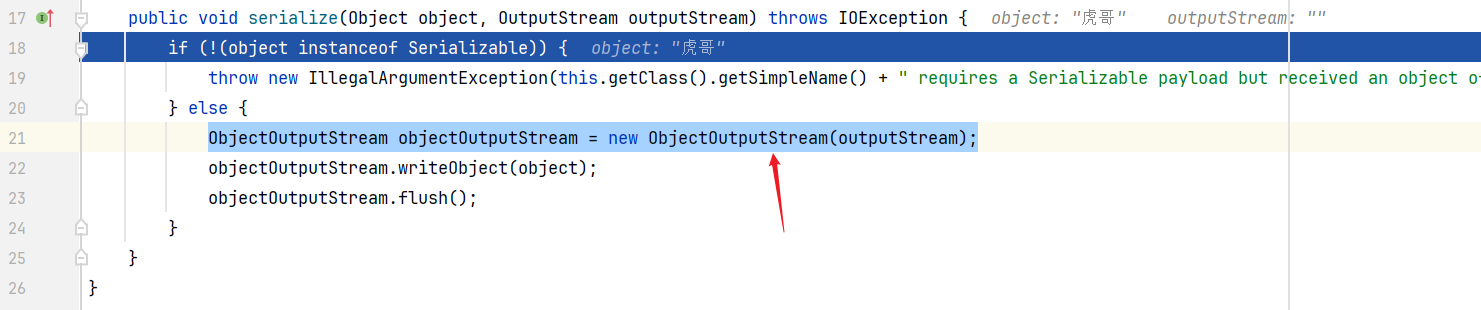
serializeToByteArray(source):字节缓冲。继续跟进 serialize()

此时看见了,底层就是使用 ObjectOutputStream 来写对象的,这个流的作用就是将Java对象转成字节,转成字节后再写入redis后就变成了 \xac\xed\x00\x05t\x00\x06\xe8\x99\x8e\xe5\x93\xa5,这就是默认的JDK序列化方式。
三、解决问题
这种方式的第一个问题就是:可读性差,如果我不说,你知道这是虎哥吗?
而且还会出现一些Bug,我在代码中是 set name,我以为我把 name 改了,结果 name 没改,而是 set 一个新的东西进去了。
并且内存占用空间也大,我明明就是一个 name,结果序列化后这么长。
因此我们希望的是:我写的是什么,你就存什么,所见即所得多好。此时就必须去改变RedisTemplate的序列化方式了。
选中 RedisSerializer,ctrl + H 可以查看它具体有哪些实现.
JdkSerializationRedisSerializer 我们刚刚已经看过了,它是最不好用的一种方式。
除了它以外,还有两个是我们可以使用的:StringRedisSerializer,它是专门用来处理字符串的,因为我们知道字符串想要转字节写入redis,只需要简单的 getBytes() 就行了,没必要利用JDK去转化,因此 StringRedisSerializer 做的事情就是 getBytes(),只不过底层编码你可以控制是 UTF-8 还是别的。
使用场景:当key和hashKey都是字符串的情况可以用它,一般情况下key都是字符串,只有值可能是对象,因此 key 的序列化器就可以用它。
如果value有可能是对象,建议使用 GenericJackson2JsonRedisSerialzer,也就是转JSON字符串的这样的序列化工具。

四、代码实现
引入 Jackson依赖。这个Jackson依赖我们平常在开发的时候是不需要自己引的,因为平时开发的时候使用的是SpringMVC,而SpringMVC中就会自带 jackson-databind 依赖。
<!--Jackson依赖-->
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
</dependency>
修改序列化器代码如下:
RedisSerializer.string() 返回值确实就是 StringRedisSerializer 的常量,然后编码格式是UTF-8,这样写就方便一些,不需要我们自己去 new 了。

@Configuration
public class RedisConfig {
// 这里定义了一个Bean叫RedisTemplate,然后定义了一个泛型,key是String,值为Object,也就是默认key永远都是String
@Bean
public RedisTemplate<String, Object> redisTemplate(RedisConnectionFactory connectionFactory){
// 创建RedisTemplate对象
RedisTemplate<String, Object> template = new RedisTemplate<>();
// redis的构建需要连接工厂,连接工厂不需要我们创建,因为SpringBoot会帮我们自动创建,我们只需要注入进来即可
template.setConnectionFactory(connectionFactory);
// 创建JSON序列化工具
GenericJackson2JsonRedisSerializer jsonRedisSerializer =
new GenericJackson2JsonRedisSerializer();
// 设置Key的序列化,使用String类型的序列化工具
template.setKeySerializer(RedisSerializer.string());
template.setHashKeySerializer(RedisSerializer.string());
// 设置Value的序列化,使用JSON类型的序列化工具
template.setValueSerializer(jsonRedisSerializer);
template.setHashValueSerializer(jsonRedisSerializer);
// 返回
return template;
}
}
修改测试代码,给注入进来的 RedisTemplate 加一个泛型,告诉它key的值一定是一个字符串,值是Object类型。
@SpringBootTest(classes = Main.class)
public class RedisDemoApplicationTests {
@Autowired
private RedisTemplate<String, Object> redisTemplate;
@Test
void testString() {
// 写入一条String数据
redisTemplate.opsForValue().set("name", "虎哥");
// 获取string数据
Object name = redisTemplate.opsForValue().get("name");
System.out.println("name = " + name);
}
}
五、测试
执行测试代码

可以发现执行成功,点开 name,发现已经成功写入 "虎哥" 了。

接下来验证一下,如果我写了一个对象,那它能不能也去帮我做序列化呢?
新建实体类
package com.itheima.redis.pojo;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
@Data
@NoArgsConstructor
@AllArgsConstructor
public class User {
private String name;
private Integer age;
}
新写一个单元测试,这次保存一个对象到redis中。
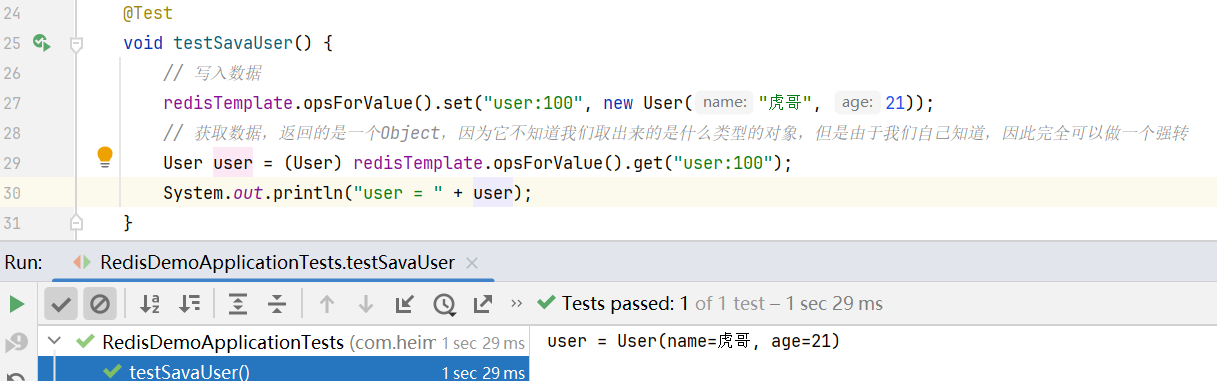
@Test
void testSavaUser() {
// 写入数据
redisTemplate.opsForValue().set("user:100", new User("虎哥", 21));
// 获取数据,返回的是一个Object,因为它不知道我们取出来的是什么类型的对象,但是由于我们自己知道,因此完全可以做一个强转
User user = (User) redisTemplate.opsForValue().get("user:100");
System.out.println("user = " + user);
}
运行单元测试,可以发现成功打印出了用户的信息,那就表示强转没有问题
接下来看一下图形化客户端,可以发现已经存入了一个User对象了,而且是JSON风格的,说明它自动化的将对象转为了JSON存入到了里面。并且最神奇的是,当我们去获取结果的时候,它还能自动的帮我们反序列化成了对象,它是怎么做到这个反序列化的呢?
如下图,事实上在写入JSON的同时,还帮我们写出了一个class的属性,对应的就是User类的字节码名称,就是因为有这样的一条属性,所以它在反序列化的时候才能够读取到我们对应的字节码,即类的名称,然后再帮我们反序列化为对应的User写进来。

也就是说将来我们存储任何数据,不管是Java对象也好还是普通对象也好,都不用担心了,全部都交给了自动化的序列化工具去处理,我们要做的就是在 Config类 中定义好key和value的序列化工具就行了。
















 1962
1962

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









