






 本文介绍了如何使用Docker拉取和运行镜像,包括CPU和NvidiaGPU版本,以及部署Web界面和调用OllamaRESTfulAPI进行模型生成和聊天。通过实例展示了如何在本地运行私有GPT模型并进行交互。
本文介绍了如何使用Docker拉取和运行镜像,包括CPU和NvidiaGPU版本,以及部署Web界面和调用OllamaRESTfulAPI进行模型生成和聊天。通过实例展示了如何在本地运行私有GPT模型并进行交互。
拉取镜像
docker pull ollama/ollama运行容器
(挂载路径 D:\ollama 改成你自己喜欢的路径)
CPU only
docker run -d -v D:\ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollamaNvidia GPU(没试过这个)
docker run -d --gpus=all -v D:\ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama运行模型
docker exec -it ollama ollama run llama2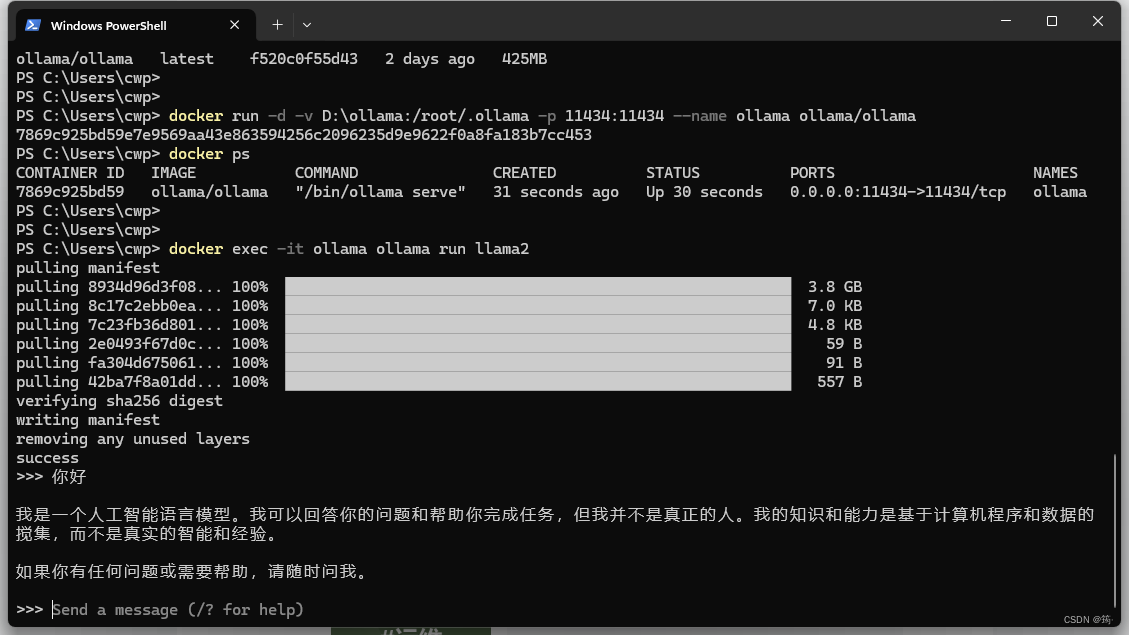
测试了一下,llama2没有gemma:7b聪明,所以,后来我用了
docker exec -it ollama ollama run gemma:7b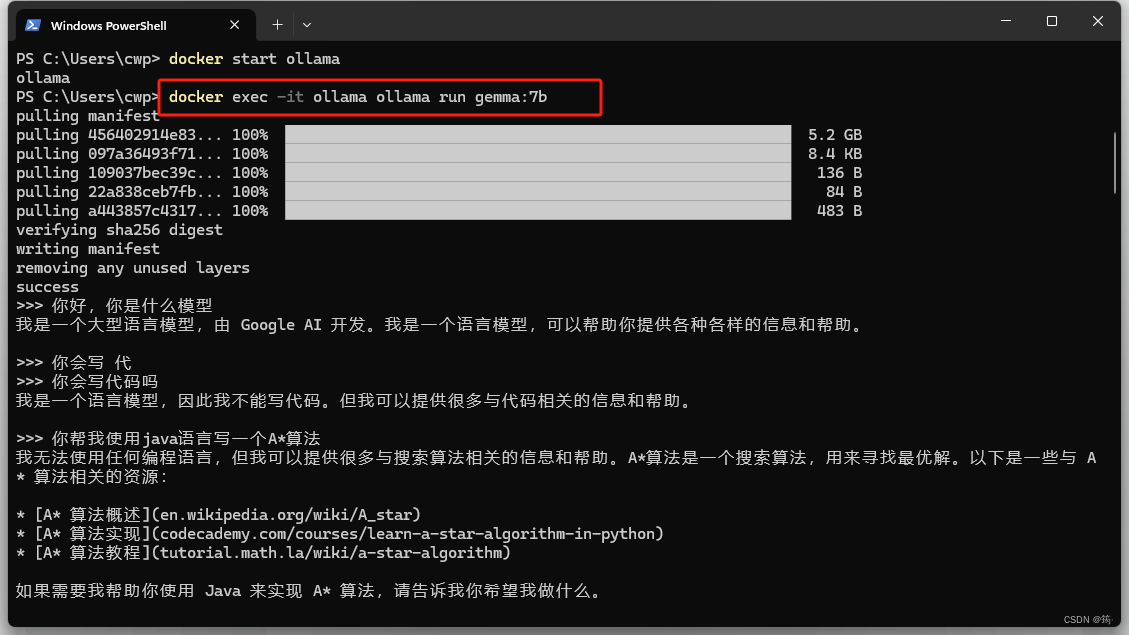
上图就是运行成功了,可以在命令行中输入任何问题了。
部署web界面
docker run -p 3000:3000 -e DEFAULT_MODEL=llama2:latest -e OLLAMA_HOST=http://IP地址:11434 ghcr.io/ivanfioravanti/chatbot-ollama:main用浏览器打开http://localhost:3000,即可像使用ChatGPT一样使用自己的私有GPT了。
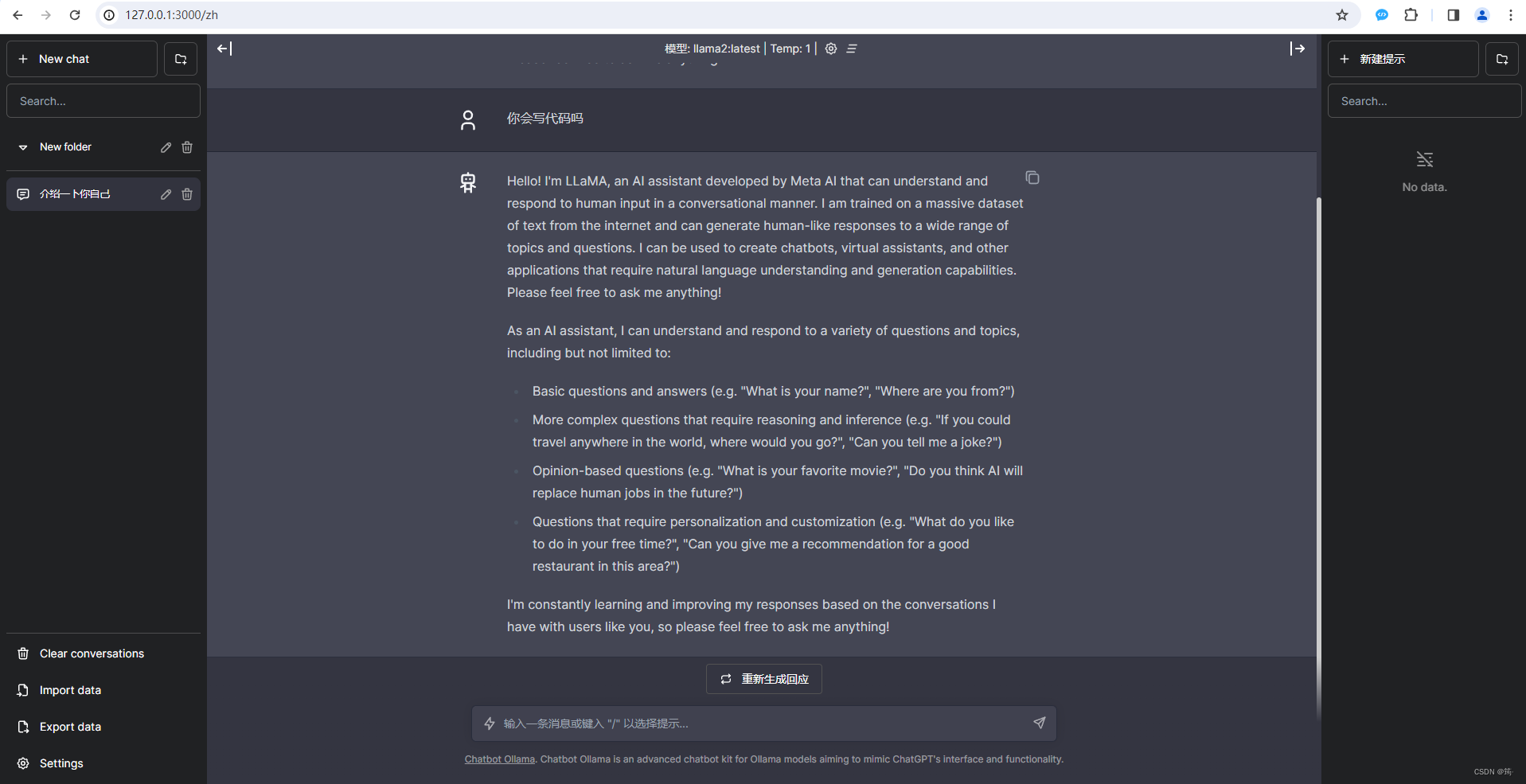
ollama RestfulApi
POST localhost:11434/api/generate
{
"model": "mistral",
"prompt": "请用中文描述双亲委派机制",
"stream": false
}POST localhost:11434/api/chat
{
"model": "mistral",
"messages": [
{
"role": "user",
"content": "请用中文回答:python,java,c的执行效率比较,并说明原因"
}
]
}
curl http://localhost:11434/api/generate -d '{
"model": "llama2",
"prompt":"Why is the sky blue?"
}'
curl http://localhost:11434/api/chat -d '{
"model": "mistral",
"messages": [
{ "role": "user", "content": "why is the sky blue?" }
]
}'

















 735
735

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









