







环境
torch 1.11.0+cu113
torchvision 0.12.0+cu113
numpy 1.21.4
imgaug 0.4.0
Pillow 9.2.0
opencv-python 4.3.0.36
opencv-python-headless 4.2.0.34
REPRODUCIBILITY
随机种子
首先要设置随机种子
#!/usr/bin/env python
# _*_ coding:utf-8 _*_
import os
import random
import numpy as np
import torch
def setup_seed(seed):
"""
set random seed
:param seed: seed num
"""
os.environ['PYTHONHASHSEED'] = str(seed)
os.environ["CUBLAS_WORKSPACE_CONFIG"] = ":16:8" # LSTM(cuda>10.2)
random.seed(seed)
np.random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
torch.cuda.manual_seed_all(seed) # if you are using multi-GPU.
torch.use_deterministic_algorithms(True)
# torch.backends.cudnn.enabled = False
torch.backends.cudnn.benchmark = False
torch.backends.cudnn.deterministic = True
不过如果你的库用的随机种子不是numpy,那需要自己设置
设置了torch.use_deterministic_algorithms(True)之后,如果你的代码里有不确定算法,就会报错
在这里可以看你的算法是不是不确定的https://pytorch.org/docs/stable/generated/torch.use_deterministic_algorithms.html#torch.use_deterministic_algorithms
多个num_workers
然后是dataloader,如果你的num_workers>1,则需要
def seed_worker(worker_id):
worker_seed = torch.initial_seed() % 2**32
numpy.random.seed(worker_seed)
random.seed(worker_seed)
g = torch.Generator()
g.manual_seed(0)
DataLoader(
train_dataset,
batch_size=batch_size,
num_workers=num_workers,
worker_init_fn=seed_worker,
generator=g,
)
下面测试只测试1个num_worker
dataloader顺序
主要测试一下固定种子后,获取图片顺序是否一样
utils/utils.py
用来设置随机种子
#!/usr/bin/env python
# _*_ coding:utf-8 _*_
import os
import random
import numpy as np
import torch
def setup_seed(seed):
"""
set random seed
:param seed: seed num
"""
os.environ['PYTHONHASHSEED'] = str(seed)
os.environ["CUBLAS_WORKSPACE_CONFIG"] = ":16:8" # LSTM(cuda>10.2)
random.seed(seed)
np.random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
torch.cuda.manual_seed_all(seed) # if you are using multi-GPU.
torch.use_deterministic_algorithms(True)
# torch.backends.cudnn.enabled = False
torch.backends.cudnn.benchmark = False
torch.backends.cudnn.deterministic = True
def seed_worker(worker_id):
worker_seed = torch.initial_seed() % 2 ** 32
np.random.seed(worker_seed)
random.seed(worker_seed)
dataset/landmark_dataset.py
#!/usr/bin/env python
# _*_ coding:utf-8 _*_
import os
from glob import glob
import imgaug as ia
import imgaug.augmenters as iaa
import numpy as np
import torch
from cv2 import cv2
from imgaug.augmentables import KeypointsOnImage
from torch.utils.data import Dataset
class LandmarkDataset(Dataset):
def __init__(self, dataset_type='train', perform_augmentation=True):
self.landmark_num = 19
junior_annotations = glob(
os.path.join('/data/datasets/ISBI2015_ceph', 'AnnotationsByMD', '400_junior', '*.txt'))
junior_annotations.sort()
senior_annotations = glob(
os.path.join('/data/datasets/ISBI2015_ceph', 'AnnotationsByMD', '400_senior', '*.txt'))
senior_annotations.sort()
img_paths = glob(
os.path.join('/data/datasets/ISBI2015_ceph', 'RawImage', 'TrainingData', '*.bmp'))
img_paths.sort()
if 'train' == dataset_type:
self.img_paths = img_paths[:130]
self.junior_annotations = junior_annotations[:130]
self.senior_annotations = senior_annotations[:130]
elif 'val' == dataset_type:
self.img_paths = img_paths[130:151]
self.junior_annotations = junior_annotations[130:150]
self.senior_annotations = senior_annotations[130:150]
self.perform_augmentation = perform_augmentation
self.height = 512
self.width = 416
# Define augmentation
seq = [
iaa.Resize({"width": self.width, "height": self.height}),
]
if self.perform_augmentation:
seq.append(iaa.Sometimes(0.9, [
iaa.Affine(translate_px={"x": (-10, 10),
"y": (-10, 10)},
scale=(0.95, 1),
rotate=(-3, 3)),
iaa.Multiply(mul=(0.5, 1.5)),
iaa.GammaContrast(),
iaa.ElasticTransformation(alpha=(0, 500),
sigma=30, order=3)
]))
self.augmentation = iaa.Sequential(seq)
def __len__(self):
return len(self.img_paths)
def __getitem__(self, idx):
print(self.img_paths[idx])
img = cv2.imread(self.img_paths[idx], 0)
junior_annotation = np.loadtxt(self.junior_annotations[idx], delimiter=",", max_rows=self.landmark_num)
senior_annotation = np.loadtxt(self.senior_annotations[idx], delimiter=",", max_rows=self.landmark_num)
# mean landmark
annotation = ((junior_annotation + senior_annotation) / 2).astype(int)
kps_array = KeypointsOnImage.from_xy_array(annotation, img.shape)
# aug
img_aug, landmark_aug = self.augmentation(image=img, keypoints=kps_array)
# draw landmark
img_aug = landmark_aug.draw_on_image(cv2.cvtColor(img_aug, cv2.COLOR_GRAY2RGB), color=(0, 255, 0), size=3)
return torch.FloatTensor(img_aug.transpose((2, 0, 1))).contiguous()/255.0
main.py
#!/usr/bin/env python
# _*_ coding:utf-8 _*_
import argparse
import os
import torch
from torch.utils.data import DataLoader
from torchvision import utils as vutils
from dataset.landmark_dataset import LandmarkDataset
from utils.utils import setup_seed, seed_worker
g = torch.Generator()
g.manual_seed(0)
def get_args():
parser = argparse.ArgumentParser()
# optional
parser.add_argument("-s", "--save_dir")
return parser.parse_args()
if __name__ == '__main__':
args = get_args()
setup_seed(42)
train_dataset = LandmarkDataset()
train_data_loader = DataLoader(train_dataset,
batch_size=4,
shuffle=True,
worker_init_fn=seed_worker,
generator=g)
valid_dataset = LandmarkDataset(dataset_type='val')
valid_data_loader = DataLoader(valid_dataset,
batch_size=4,
shuffle=True,
worker_init_fn=seed_worker,
generator=g)
for epoch in range(10):
for idx, x in enumerate(train_data_loader):
cur_dir = f'{args.save_dir}/{epoch}/{idx}'
os.makedirs(cur_dir, exist_ok=True)
for i, t in enumerate(x):
vutils.save_image(t.unsqueeze(0), os.path.join(cur_dir, f'{i}.bmp'))
print()
if 0 == (epoch + 1) % 5:
for x in valid_data_loader:
pass
文件结构
测试方法
输出两次获取图片的顺序,然后对比
python main.py --save_dir imgaug1>test1
python main.py --save_dir imgaug2>test2
diff test1 test2
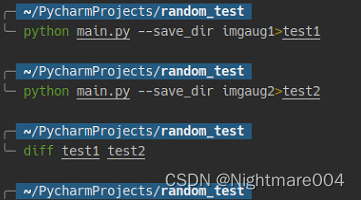
也就是说生成顺序是一样的
测试imgaug数据增强
根据imgaug作者在https://github.com/aleju/imgaug/issues/555说的
imgagu会先从numpy获取第一个随机种子,所以imgaug前设置numpy随机种子,也就相当于设置了imgaug的随机种子

check_same.py
#!/usr/bin/env python
# _*_ coding:utf-8 _*_
import argparse
import os
import numpy as np
from cv2 import cv2
def is_same(direction1, direction2):
for root, dirs, files in os.walk(direction1):
for file in files:
path1 = os.path.join(root, file)
path2 = path1.replace(direction1, direction2)
img1 = cv2.imread(path1)
img2 = cv2.imread(path2)
if not np.allclose(img1, img2):
return False
return True
def get_args():
parser = argparse.ArgumentParser()
# optional
parser.add_argument("--d1")
parser.add_argument("--d2")
return parser.parse_args()
if __name__ == '__main__':
args = get_args()
print(is_same(args.d1, args.d2))
其他程序跟上面一样
测试方法
python main.py --save_dir imgaug1
python main.py --save_dir imgaug2
python check_same.py --d1 imgaug1 --d2 imgaug2
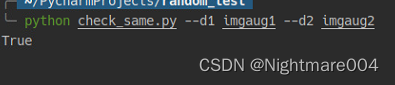
也就是说跑2次,增强的是一样的
to_deterministic
如果用了这个,那你只有第一下是随机的,后面的增强都跟第一次一样
不过如果你传入一个batch,那batch之间是可以不同的
比如说第一个batch,旋转5,10,15
那么第二个batch就也是旋转5,10,15
模型
model/unet2d.py
import torch
import torch.nn as nn
import torch.nn.functional as F
class DoubleConv(nn.Module):
"""(convolution => [BN] => ReLU) * 2"""
def __init__(self, in_channels, out_channels, mid_channels=None):
super().__init__()
if not mid_channels:
mid_channels = out_channels
self.double_conv = nn.Sequential(
nn.Conv2d(in_channels, mid_channels, kernel_size=3, padding=1),
nn.BatchNorm2d(mid_channels),
nn.ReLU(inplace=True),
nn.Conv2d(mid_channels, out_channels, kernel_size=3, padding=1),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True)
)
def forward(self, x):
return self.double_conv(x)
class Down(nn.Module):
"""Downscaling with maxpool then double conv"""
def __init__(self, in_channels, out_channels):
super().__init__()
self.maxpool_conv = nn.Sequential(
nn.MaxPool2d(2),
DoubleConv(in_channels, out_channels)
)
def forward(self, x):
return self.maxpool_conv(x)
class Up(nn.Module):
"""Upscaling then double conv"""
def __init__(self, in_channels, out_channels, bilinear=True):
super().__init__()
# if bilinear, use the normal convolutions to reduce the number of channels
if bilinear:
self.up = nn.Upsample(
scale_factor=2, mode='bilinear', align_corners=True)
# self.up = nn.Upsample(scale_factor=2)
self.conv = DoubleConv(in_channels, out_channels, in_channels // 2)
else:
self.up = nn.ConvTranspose2d(
in_channels, in_channels // 2, kernel_size=2, stride=2)
self.conv = DoubleConv(in_channels, out_channels)
def forward(self, x1, x2):
x1 = self.up(x1)
# input is CHW
diffY = x2.size()[2] - x1.size()[2]
diffX = x2.size()[3] - x1.size()[3]
x1 = F.pad(x1, [diffX // 2, diffX - diffX // 2,
diffY // 2, diffY - diffY // 2])
# if you have padding issues, see
# https://github.com/HaiyongJiang/U-Net-Pytorch-Unstructured-Buggy/commit/0e854509c2cea854e247a9c615f175f76fbb2e3a
# https://github.com/xiaopeng-liao/Pytorch-UNet/commit/8ebac70e633bac59fc22bb5195e513d5832fb3bd
x = torch.cat([x2, x1], dim=1)
return self.conv(x)
class OutConv(nn.Module):
def __init__(self, in_channels, out_channels):
super(OutConv, self).__init__()
self.conv = nn.Conv2d(in_channels, out_channels, kernel_size=1)
def forward(self, x):
return self.conv(x)
class UNet(nn.Module):
def __init__(self, in_channels, out_channels, bilinear=True):
super(UNet, self).__init__()
if not isinstance(in_channels, list):
in_channels = [in_channels]
if not isinstance(out_channels, list):
out_channels = [out_channels]
self.in_channels = in_channels
self.out_channels = out_channels
self.bilinear = bilinear
for i, (n_chan, n_class) in enumerate(zip(in_channels, out_channels)):
setattr(self, 'in{i}'.format(i=i), OutConv(n_chan, 64))
setattr(self, 'out{i}'.format(i=i), OutConv(64, n_class))
self.conv = DoubleConv(64, 64)
self.down1 = Down(64, 128)
self.down2 = Down(128, 256)
self.down3 = Down(256, 512)
factor = 2 if bilinear else 1
self.down4 = Down(512, 1024 // factor)
self.up1 = Up(1024, 512 // factor, bilinear)
self.up2 = Up(512, 256 // factor, bilinear)
self.up3 = Up(256, 128 // factor, bilinear)
self.up4 = Up(128, 64, bilinear)
def forward(self, x, task_idx=0):
x1 = getattr(self, 'in{}'.format(task_idx))(x)
x1 = self.conv(x1)
x2 = self.down1(x1)
x3 = self.down2(x2)
x4 = self.down3(x3)
x5 = self.down4(x4)
x = self.up1(x5, x4)
x = self.up2(x, x3)
x = self.up3(x, x2)
x = self.up4(x, x1)
logits = getattr(self, 'out{}'.format(task_idx))(x)
return {'output': torch.sigmoid(logits)}
顺带一提,nn.Upsample(scale_factor=2, mode=‘bilinear’, align_corners=True)是在cuda里不确定算法
(可以用下面的代码试试
#!/usr/bin/env python
# _*_ coding:utf-8 _*_
import os
import random
import numpy as np
import torch
from torch import nn
def setup_seed(seed):
"""
set random seed
:param seed: seed num
"""
os.environ['PYTHONHASHSEED'] = str(seed)
os.environ["CUBLAS_WORKSPACE_CONFIG"] = ":16:8" # LSTM(cuda>10.2)
random.seed(seed)
np.random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
torch.cuda.manual_seed_all(seed) # if you are using multi-GPU.
torch.use_deterministic_algorithms(True, warn_only=True)
# torch.backends.cudnn.enabled = False
torch.backends.cudnn.benchmark = False
torch.backends.cudnn.deterministic = True
setup_seed(42)
device = torch.device('cuda')
if __name__ == '__main__':
x = torch.randn((1, 3, 64, 64), requires_grad=True).to(device)
target = torch.randn((1, 3, 128, 128)).to(device)
m = nn.Upsample(scale_factor=2, mode='bilinear', align_corners=True).to(device)
y_hat = m(x)
loss = torch.sum((y_hat - target) ** 2)
print(loss)
loss.backward()
改成nn.Upsample(scale_factor=2)的话,是确定算法
save_model.py
#!/usr/bin/env python
# _*_ coding:utf-8 _*_
import argparse
import torch
from model.unet2d import UNet
from utils.utils import setup_seed
def get_args():
parser = argparse.ArgumentParser()
# optional
parser.add_argument("-s", "--save_name")
return parser.parse_args()
if __name__ == '__main__':
args = get_args()
setup_seed(42)
model = UNet(1, 19)
torch.save(model, args.save_name)
check_same_model.py
#!/usr/bin/env python
# _*_ coding:utf-8 _*_
import argparse
import torch
def get_args():
parser = argparse.ArgumentParser()
# optional
parser.add_argument("--m1")
parser.add_argument("--m2")
return parser.parse_args()
def is_same(path1, path2):
model1 = torch.load(path1)
model2 = torch.load(path2)
for p1, p2 in zip(model1.parameters(), model2.parameters()):
if not torch.allclose(p1, p2):
return False
return True
if __name__ == '__main__':
args = get_args()
print(is_same(args.m1, args.m2))
其他跟上面一样
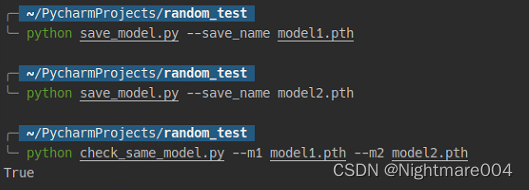
测试方法
简单来说就是生成两个,然后逐个参数对比
python save_model.py --save_name model1.pth
python save_model.py --save_name model2.pth
python check_same_model.py --m1 model1.pth --m2 model2.pth
如果你有不确定算法
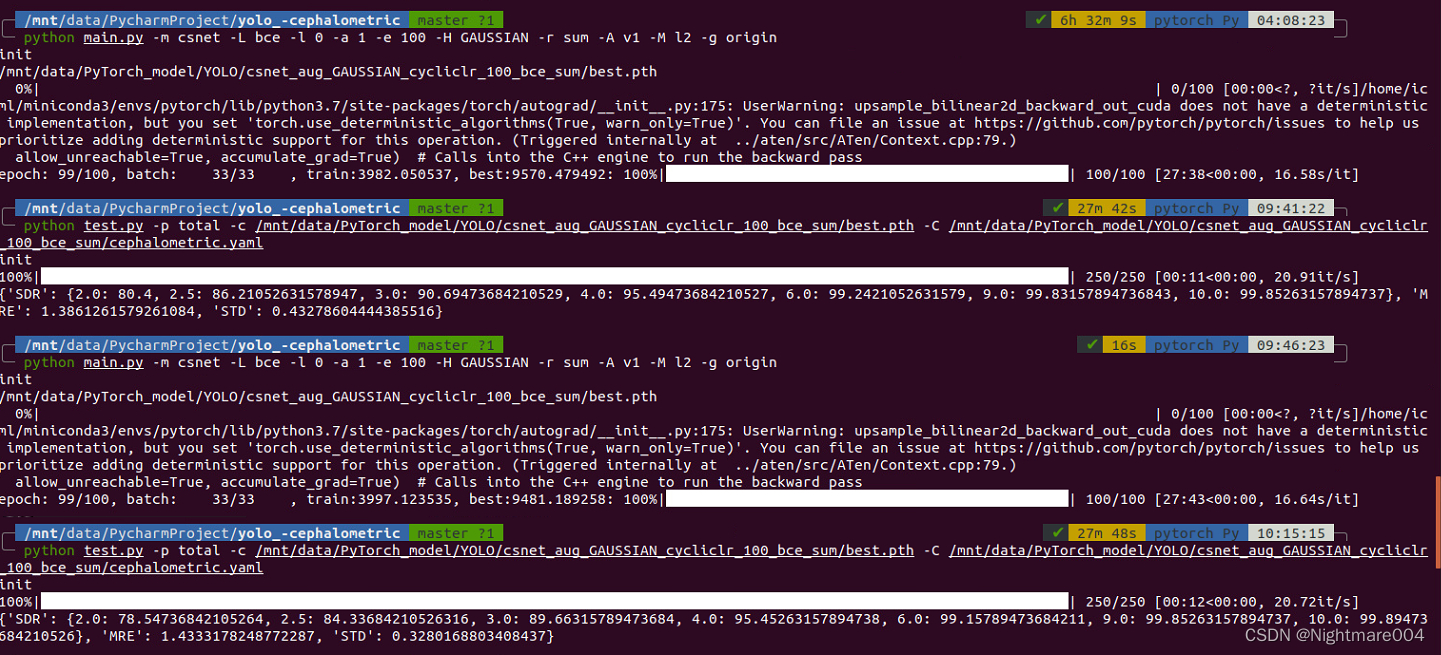
可以看到两次结果不一样
如果你都是确定算法
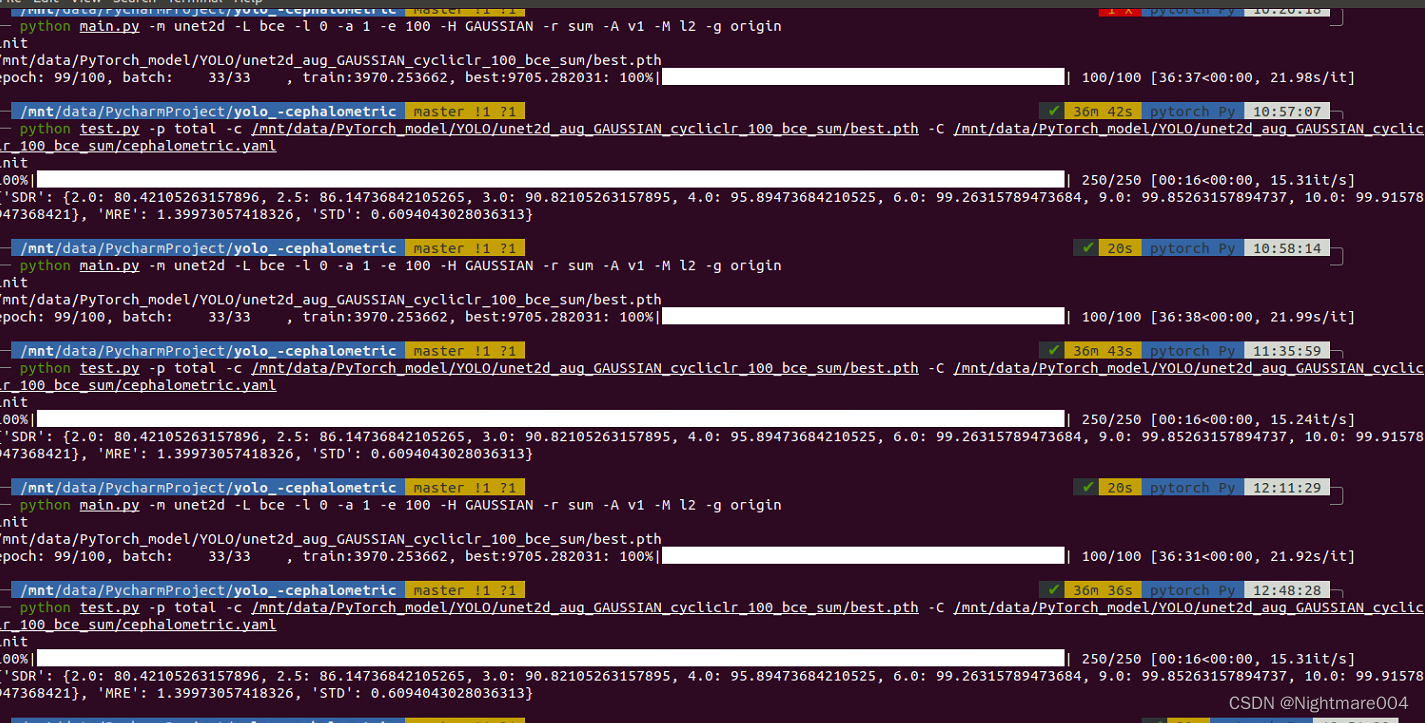 这3次结果都是一样的
这3次结果都是一样的
参考
https://pytorch.org/docs/stable/notes/randomness.html
https://zhuanlan.zhihu.com/p/480931657
https://github.com/aleju/imgaug/issues/555



















 1055
1055

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











