







The Art of Drafting: A Team-Oriented Hero Recommendation System for Multiplayer Online Battle Arena Games
纯MCTS方法,阵容选定后,胜率用模型预测,然后反向传播
https://github.com/czxttkl/DraftArtist
没有训练,只有推理
方法
问题定义
DOTA2 Radiant(天辉)和Dire_(夜魇)
以天辉为例(先手选人)
n
=
2
n=2
n=2玩家数量
S
⊂
Z
N
S \subset \mathbb{Z}^N
S⊂ZN游戏状态,
s
∈
S
s \in S
s∈S是一个
N
N
N维向量,表示一个游戏状态;
N
N
N是总英雄数量
s
i
=
{
1
,
Radiant
−
1
,
Dire
0
,
otherwise
s_{i} = \begin{cases} 1, & \text{Radiant} \\ -1, & \text{Dire} \\ 0, &\text{otherwise} \end{cases}
si=⎩
⎨
⎧1,−1,0,RadiantDireotherwise
S
T
S_{T}
ST终态集合,bp结束
ρ
:
S
→
{
Radiant
,
Dire
}
\rho: S\to \left\{ \text{Radiant}, \text{Dire}\right\}
ρ:S→{Radiant,Dire}轮到哪一队选英雄
A
A
A选人动作集合
f
:
S
×
A
→
S
f:S \times A \to S
f:S×A→S转移函数
R
:
S
→
R
2
R:S \to \mathbb{R}^2
R:S→R2奖励,
R
1
(
s
)
=
−
R
2
(
s
)
=
w
(
s
)
R^1 \left( s \right)= -R^2\left( s \right)=w \left( s \right)
R1(s)=−R2(s)=w(s),其中
w
(
s
)
w \left( s \right)
w(s)表示Radient胜率
MCTS
Monte Carlo Tree Search(MCTS)

Upper Confidence Bound applied to trees(UCT)
Upper Confidence Bound(UCB)
UCT = MCTS + UCB
选择
从根节点往下搜索,直到终态或者可扩展节点
若一个节点全扩展完了,那么下一个节点用UCB来选择
π
U
C
B
(
s
)
=
arg
max
a
{
w
ˉ
+
c
log
n
(
s
)
n
(
s
,
a
)
}
\pi_{UCB} \left( s \right) = \arg\max\limits_{a} \left\{ \bar{w} + c\sqrt{ \frac{\log n \left( s \right) }{n \left( s,a \right) } } \right\}
πUCB(s)=argamax{wˉ+cn(s,a)logn(s)}
其中
s
s
s是当前状态,
a
a
a是动作,
w
ˉ
\bar{w}
wˉ是平均回报(平均胜率),
n
(
s
)
n \left( s \right)
n(s)是总访问次数,
c
c
c是平衡常数
子节点访问次数越少,公式后半部分越大,让节点有机会被访问到
扩展
随机选择一个未访问过的动作,进入下一个节点
模拟
通过随机动作到终态
反向传播
更新访问过的节点的胜率和访问次数
胜率预测
s i = { 1 , Radiant − 1 , Dire Ξ , ban 0 , otherwise s_{i} = \begin{cases} 1, & \text{Radiant} \\ -1, & \text{Dire} \\ \Xi, &\text{ban}\\ 0, &\text{otherwise} \end{cases} si=⎩ ⎨ ⎧1,−1,Ξ,0,RadiantDirebanotherwise
12个特殊字符
Ξ
\Xi
Ξ(?)
对于奖励函数
R
(
s
)
R\left( s \right)
R(s),输入的
s
s
s可以将ban的英雄设置为
0
0
0
模型为mlp classifer,隐藏层数为1,维度为120
(111->120->2)
评估
数据集
dota2 2016.02.11-2016.03.02
5百万场“Ranked All Pick”对局,包含阵容和平均段位(正常,高,非常高)
为了降低段位的影响,选择了正常段位
最后有3056596场,111个英雄
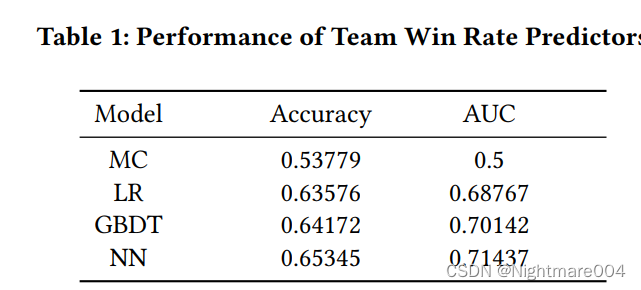
胜率预测训练
对比方法:
梯度提升树(GBDT)
逻辑回归(LR):对
majority class(MC):直接预测天辉赢,因为有53.75%的对局天辉赢
模拟
对局1000局,轮流先手
第一个英雄:每个英雄被选择的概率和在数据集中被选的概率有关

UCT n , c \text{UCT}_{n,c} UCTn,c, n n n是迭代, c c c是常数
Association Rules (AR):设定一些规则,比如这个英雄选了的情况下选另一个英雄counter
Highest Win Rate (HWR):选胜率最高
Random (RD):随机
全英雄模式
同一行的迭代次数是一样的,因此调
c
c
c作用不大
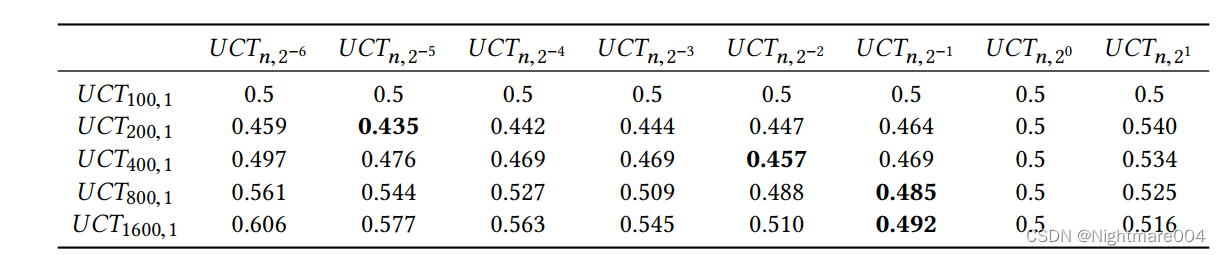
全英雄模式
UCT比非UCT胜率高
基本趋势是随着迭代,胜率越来越高
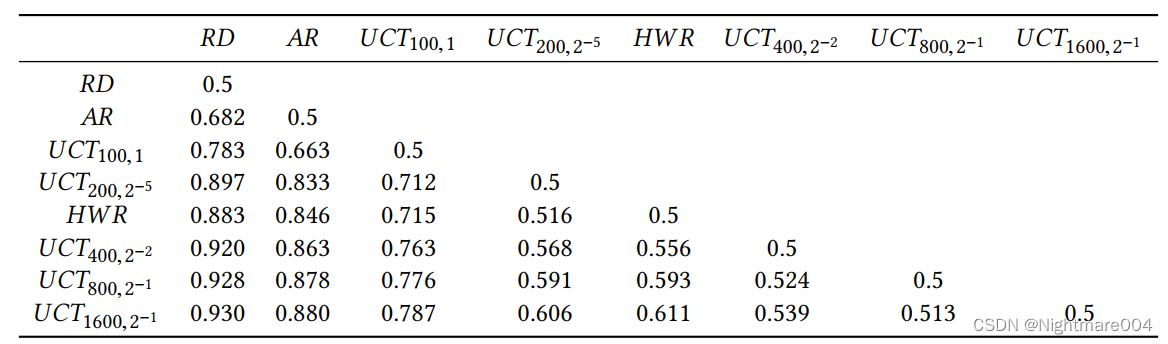

Captain Mode

在ban环节,UCT将输出的英雄ban了
c开始有影响,所以图中的c是实验中最好的
UCT比非UCT好


















 2850
2850

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











