








UNet论文地址:https://arxiv.org/abs/1505.04597
我实现的github地址
Unet
该论文研究的问题是什么?
主要研究的是,在只有少量图片的情况下,充分利用数据增广,实现图像分割
为什么重要或者有趣?
Unet发表在MICCAI上,目前的引用量是6.7k,成为大多做医疗影像语义分割任务的baseline,也启发了大量研究者去思考U型语义分割网络。而如今在自然影像理解方面,也有越来越多的语义分割和目标检测SOTA模型开始关注和使用U型结构。
该论文提出的主要方法是什么?
1.提出基于FCN的U型网络
2.Overlap-tile策略
3.数据增广
该论文基于全卷积网络提出了如下的模型。这个网络基本上是左右对称的,呈U型。左半边为收缩路径(contracting path),用来提取特征,由两个3x3的卷积+ReLU+2x2的max pooling层(stride=2)反复组成。而右半边为扩展路径(expanding path),用来精确定位,由一个2x2的上采样卷积层+ReLU+Concatenation(crop对应的收缩路径的输出feature map然后与扩展路径的上采样结果相加)+2个3x3的卷积层+ReLU+反复构成。
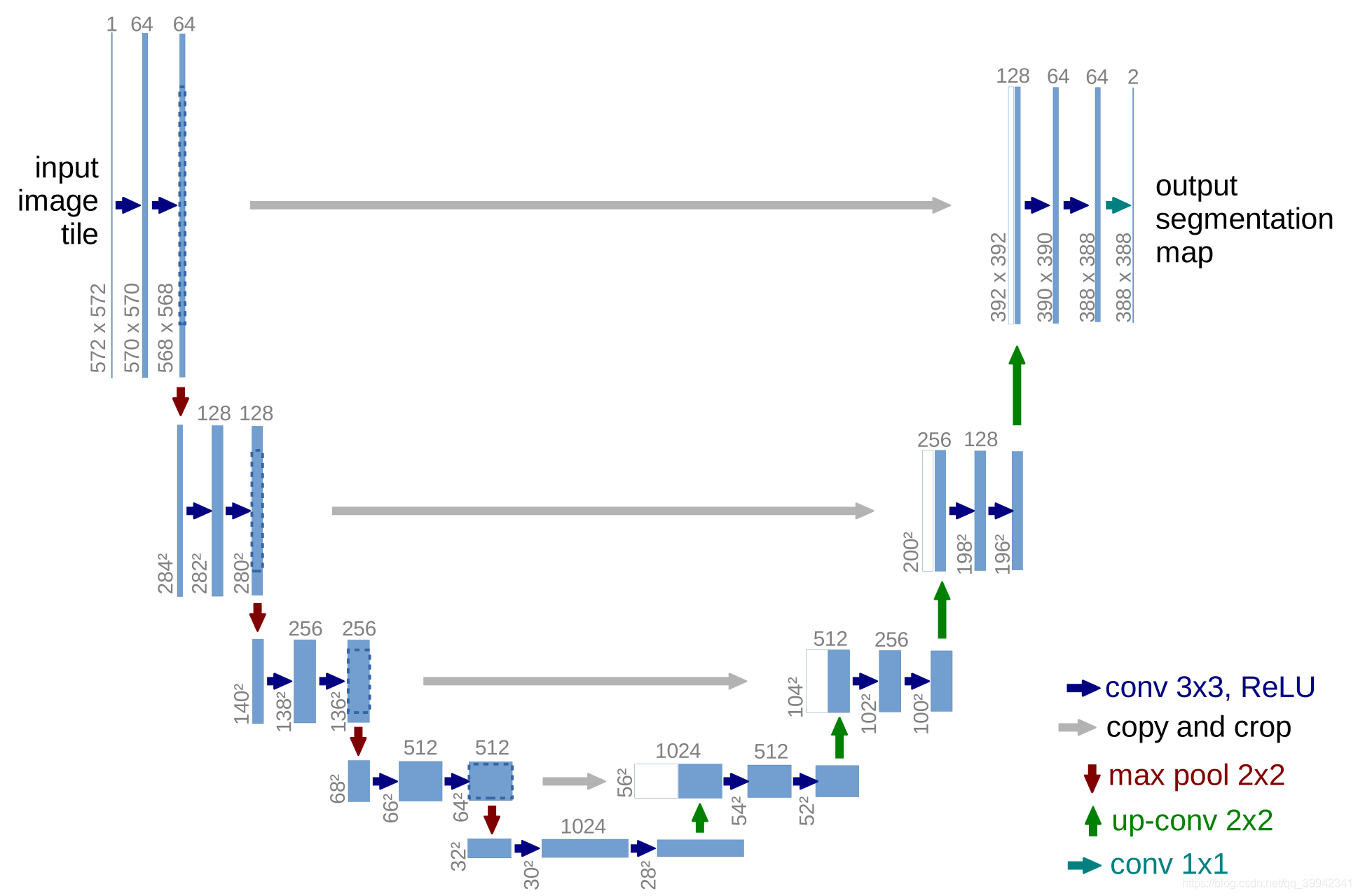
Unet的输入是572x572的,而输出是388x388的(作者的数据集是512x512的)。
Unet的卷积都是valid卷积(而非same),这么做是为了,网络只使用输入图片的信息。如果会用same卷积,这样每次3x3卷积就不会改变特征图的尺寸了,最终上采样回来的尺寸就能够和输入一致了。但是,padding是会引入误差的,而且模型越深层得到的feature map抽象程度越高,受到padding的影响会呈累积效应。
其实388x388的图片也可以通过反卷积,或者上采样来还原成512x512,但是Unet采用了Overlap-tile策略,如下图,假设要预测黄色的区域,则将蓝色区域输入,因为图片经过模型会缩小,所以需要大一圈。为了预测边缘区域,需要将图像进行镜像padding,以获得边缘的周边信息。
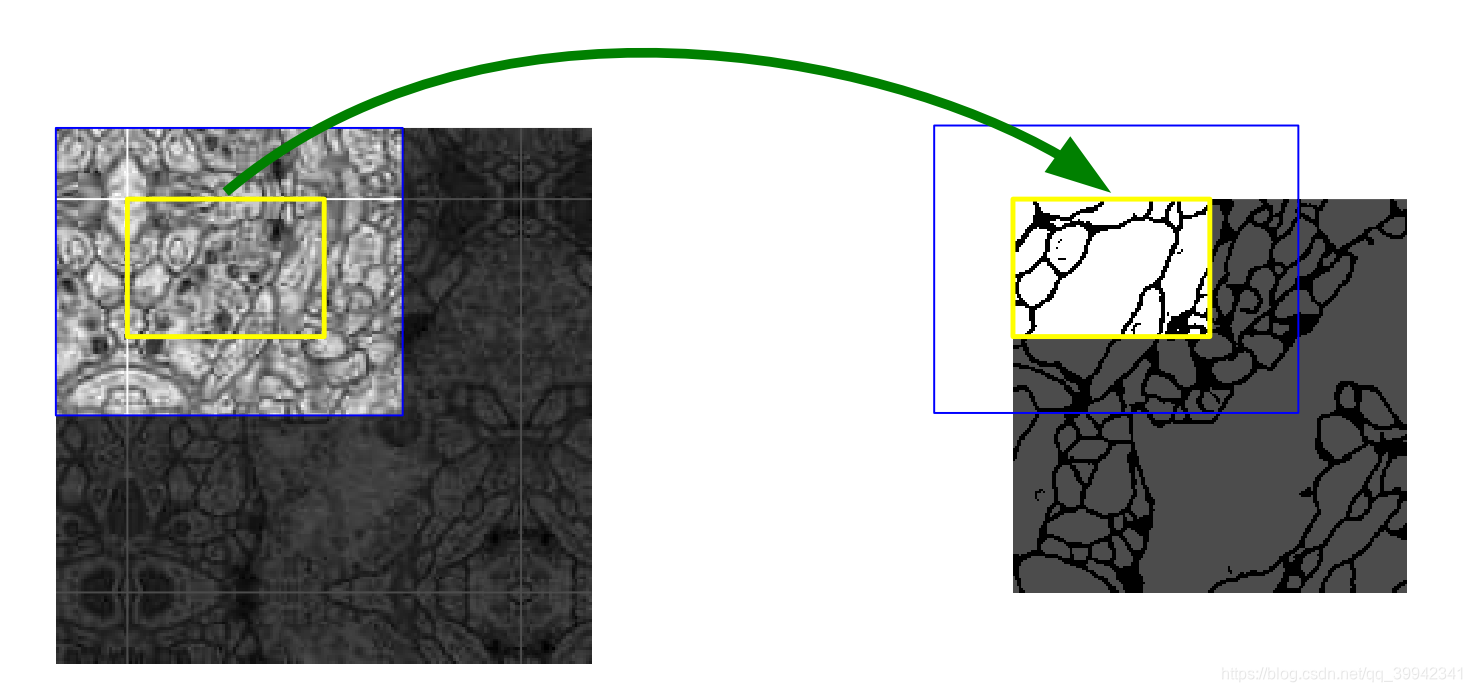
因为当时的gpu显存限制(NVidia Titan GPU (6 GB)),不能将原图输入,而resize会损失图像的分辨率,所以采用的是将512512的图片进行镜像padding,得到696696,切割出4张572572的图片(左上,右上,左下,右下),输出388388的图片,最后拼接在一起(重复的部分会取平均)。
因为数据集的图片较少,作者采用了图像增广,其中比较特殊的是弹性形变(elastic deformations)
因为数据集的白色(前景)比较多,会导致模型倾向于预测前景比较多,作者的方法是带权重的交叉熵~~(自己看吧,反正没什么人去实现)~~

实现
github地址
接下来的实现是padding=valid,尽管很多人实现的时候,padding用的是same
模型辅助部分,这里封装了2次卷积和relu,然后上采样部分,从收缩路径过来的要记得裁剪中间,然后记住我们的padding都是0。
#!/usr/bin/env python
# _*_ coding:utf-8 _*_
import torch
import torch.nn as nn
class DoubleConv(nn.Module):
def __init__(self, in_ch, out_ch):
super(DoubleConv, self).__init__()
self.conv = nn.Sequential(
nn.Conv2d(in_ch, out_ch, kernel_size=3, stride=1, padding=0),
# nn.BatchNorm2d(out_ch),
nn.ReLU(inplace=True),
nn.Conv2d(out_ch, out_ch, kernel_size=3, stride=1, padding=0),
# nn.BatchNorm2d(out_ch),
nn.ReLU(inplace=True)
)
def forward(self, x):
x = self.conv(x)
return x
class ConvDown(nn.Module):
def __init__(self, in_ch, out_ch):
super(ConvDown, self).__init__()
self.conv = DoubleConv(in_ch, out_ch)
self.pool = nn.MaxPool2d(kernel_size=2, stride=2)
def forward(self, x):
x = self.conv(x)
pool_x = self.pool(x)
return pool_x, x
def extract_img(size, in_tensor):
"""
提取图片中心部分
:param size: 切割大小
:param in_tensor: 图片
:return: 图片中心
"""
height = in_tensor.size(2)
width = in_tensor.size(3)
return in_tensor[:, :, (height - size) // 2:(height + size) // 2, (width - size) // 2: (width + size) // 2]
class ConvUP(nn.Module):
def __init__(self, in_ch, out_ch):
super(ConvUP, self).__init__()
self.up = nn.ConvTranspose2d(in_ch, out_ch, kernel_size=2, stride=2)
self.conv = DoubleConv(in_ch, out_ch)
def forward(self, x1, x2):
x1 = self.up(x1)
x1_dim = x1.size()[2]
x2 = extract_img(x1_dim, x2)
x1 = torch.cat((x1, x2), dim=1)
x1 = self.conv(x1)
return x1
Unet具体实现,输入是
B
∗
1
∗
572
∗
572
B*1*572*572
B∗1∗572∗572,输出是
B
∗
2
∗
388
∗
388
B*2*388*388
B∗2∗388∗388,输出2个通道代表一个预测前景,一个预测背景,然后哪个大,就归为哪一类
当然你也可以输出一个通道,然后经过sigmoid转成概率,然后大于
0.5
0.5
0.5就前景什么的
#!/usr/bin/env python
# _*_ coding:utf-8 _*_
from model.unet_parts import *
class UNet(nn.Module):
def __init__(self, in_channels=1, out_channels=2):
super(UNet, self).__init__()
self.conv_down1 = ConvDown(in_channels, 64)
self.conv_down2 = ConvDown(64, 128)
self.conv_down3 = ConvDown(128, 256)
self.conv_down4 = ConvDown(256, 512)
self.conv_down5 = ConvDown(512, 1024)
# self.dropout = nn.Dropout(p=0.5)
self.conv_up1 = ConvUP(1024, 512)
self.conv_up2 = ConvUP(512, 256)
self.conv_up3 = ConvUP(256, 128)
self.conv_up4 = ConvUP(128, 64)
self.conv_out = nn.Conv2d(64, out_channels, 1, stride=1, padding=0)
def forward(self, x):
x, conv1 = self.conv_down1(x)
x, conv2 = self.conv_down2(x)
x, conv3 = self.conv_down3(x)
x, conv4 = self.conv_down4(x)
_, x = self.conv_down5(x)
# x = self.dropout(x)
x = self.conv_up1(x, conv4)
x = self.conv_up2(x, conv3)
x = self.conv_up3(x, conv2)
x = self.conv_up4(x, conv1)
x = self.conv_out(x)
return x
if __name__ == '__main__':
im = torch.randn(1, 1, 572, 572)
model = UNet(in_channels=1, out_channels=2)
print(model)
x = model(im)
print(x.shape)
预处理,值得注意的是弹性形变,其他应该很显然
#!/usr/bin/env python
# _*_ coding:utf-8 _*_
import random
import numpy
import numpy as np
from scipy.ndimage.filters import gaussian_filter
from scipy.ndimage.interpolation import map_coordinates
def elastic_transform(image, alpha, sigma, seed=None):
"""
弹性形变
:param image: 图片(h,w)
:param alpha: 放缩因子
:param sigma: 弹性系数
:param seed: 随机种子
:return: 弹性形变后的图片
"""
assert isinstance(image, numpy.ndarray)
shape = image.shape # h*w
assert 2 == len(shape)
if seed is None:
seed = random.randint(1, 100)
random_state = np.random.RandomState(seed)
# 生成一个均匀分布(-1,1)的移位场,然后高斯滤波,然后成缩放
dx = gaussian_filter((random_state.rand(*shape) * 2 - 1), sigma) * alpha
dy = gaussian_filter((random_state.rand(*shape) * 2 - 1), sigma) * alpha
# 生成坐标
y, x = np.meshgrid(np.arange(shape[1]), np.arange(shape[0]))
# 偏移
indices = np.reshape(x + dx, (-1, 1)), np.reshape(y + dy, (-1, 1))
# 插值
return map_coordinates(image, indices, order=1).reshape(shape), seed
def padding_elastic_transform(image, alpha, sigma, seed=None, pad_size=20):
image_size = image.shape[0]
image = np.pad(image, pad_size, mode="symmetric")
image, seed = elastic_transform(image, alpha=alpha, sigma=sigma, seed=seed)
return crop(image, image_size, pad_size, pad_size), seed
def image_add_value(image, value):
"""
图片+一个值
:param image: 图片
:param value: 值
:return: 处理后的图片
"""
# 增加有可能超出图片范围,要先转类型,然后限制到255,再转回去
return np.clip(image.astype('int16') + value, 0, 255).astype('uint8')
def add_gaussian_noise(image, mean, std):
gauss_noise = np.random.normal(mean, std, image.shape)
return image_add_value(image, gauss_noise)
def add_uniform_noise(image, low, high):
uniform_noise = np.random.uniform(low, high, image.shape)
return image_add_value(uniform_noise, uniform_noise)
def change_brightness(image, value):
"""
增加图片亮度
:param image: 图片
:param value: 增加亮度
:return: 调亮的图片
"""
return image_add_value(image, value)
def crop(image, crop_size, height_crop_start, width_crop_start):
"""
图像切割(正方形)
:param image: 图像(h,w)
:param crop_size: 切割大小
:param height_crop_start: h方向上裁剪位置
:param width_crop_start: w方向上裁剪位置
:return: 切割后的图片
"""
return image[height_crop_start:height_crop_start + crop_size,
width_crop_start:width_crop_start + crop_size]
def stride_size(image_size, crop_num, crop_size):
"""
计算切割图片的步长
:param image_size: 图片长度
:param crop_num: 切割数量
:param crop_size: 切割长度
:return: 步长
"""
# 有重叠,要保证最后一块切完是刚好 (crop_num-1)crop_size+crop_size=image_size
return (image_size - crop_size) // (crop_num - 1)
def multi_cropping(image, crop_size, crop_num1, crop_num2):
"""
图像切割成左上,右上,左下,右下
:param image: 图片
:param crop_size: 切割大小
:param crop_num1: h切割数量
:param crop_num2: w切割数量
:return: [左上,右上,左下,右下]
"""
img_height, img_width = image.shape[0], image.shape[1]
# 要能够切完整个图片
assert crop_size * crop_num1 >= img_width and crop_size * crop_num2 >= img_height
# 不能切太多
assert crop_num1 <= img_width - crop_size + 1 and crop_num2 <= img_height - crop_size + 1
cropped_images = []
height_stride = stride_size(img_height, crop_num1, crop_size)
width_stride = stride_size(img_width, crop_num2, crop_size)
for i in range(crop_num1):
for j in range(crop_num2):
cropped_images.append(crop(image, crop_size, height_stride * i, width_stride * j))
return np.asarray(cropped_images)
DiceLoss
D
=
1
−
2
∑
i
N
p
i
g
i
∑
i
N
p
i
2
+
∑
i
N
g
i
2
D=1-\frac{2 \sum_{i}^{N} p_{i} g_{i}}{\sum_{i}^{N} p_{i}^{2}+\sum_{i}^{N} g_{i}^{2}}
D=1−∑iNpi2+∑iNgi22∑iNpigi
这里我实现的时候,因为输出是2个通道,所以先经过softmax,然后吧target转成onehot,逐个比较
如果你是一个通道,那你可以直接sigmoid,然后套公式,中间的target不用转onehot
然后加了一个拉普拉斯平滑
#!/usr/bin/env python
# _*_ coding:utf-8 _*_
from torch import nn
from torch.nn import functional as F
import torch
class SoftDiceLoss(nn.Module):
def __init__(self, smooth=1):
super().__init__()
self.smooth = smooth
def forward(self, predict, target):
"""
dice_loss
:param predict: 模型输出(b*c*h*w)
:param target: 目标(b*h*w)
:return: dice_loss
"""
batch_size = predict.size(0)
num_class = predict.size(1)
probability = F.softmax(predict, dim=1) # 转成概率形式
# 转one-hot
target_one_hot = F.one_hot(target, num_classes=num_class).permute((0, 3, 1, 2))
loss = 0.0
for i in range(num_class):
p = probability[:, i, ...]
gt = target_one_hot[:, i, ...]
dice_coff = (2 * torch.sum(p * gt) + self.smooth) / (torch.sum(p) + torch.sum(gt) + self.smooth)
loss += dice_coff
return 1 - loss / (num_class * batch_size)
接着是overlap-tile,这里注意我们切割的是 388 ∗ 388 388*388 388∗388,所以要把他拼成 512 ∗ 512 512*512 512∗512必然是有重叠的,计算一下每个地方重叠次数,最后取平均
def get_weight_mat(crop_size, crop_num1, crop_num2, img_height, img_width):
"""
计算重叠次数
:param crop_size: 切割大小
:param crop_num1: h切割数
:param crop_num2: w切割数
:param img_height: 图片h
:param img_width: 图片w
:return: 重叠次数
"""
# 最终结果
res = torch.zeros((img_height, img_width))
# 与切割大小相同的全1矩阵
one_mat = torch.ones((crop_size, crop_size))
# 步长
height_stride = stride_size(img_height, crop_num1, crop_size)
width_stride = stride_size(img_width, crop_num2, crop_size)
for i in range(crop_num1):
for j in range(crop_num2):
res[height_stride * i:height_stride * i + crop_size,
width_stride * j:width_stride * j + crop_size] += one_mat
return res
def image_concatenate(image, crop_num1, crop_num2, img_height, img_width):
"""
切割图片拼接
:param image: 切割图片(4*388*388)
:param crop_num1: h切割数
:param crop_num2: w切割数
:param img_height: 图片h
:param img_width: 图片w
:return: 拼接图片
"""
# 切割大小
crop_size = image.size(2)
# 最终结果
res = torch.zeros((img_height, img_width)).to(get_device())
# 步长
height_stride = stride_size(img_height, crop_num1, crop_size)
width_stride = stride_size(img_width, crop_num2, crop_size)
cnt = 0
for i in range(crop_num1):
for j in range(crop_num2):
res[height_stride * i:height_stride * i + crop_size,
width_stride * j:width_stride * j + crop_size] += image[cnt]
cnt += 1
return res
def get_prediction_image(stacked_img):
"""
预测图片
:param stacked_img: 切割的图片(4*388*388)
:return: 预测图片
"""
# 计算重叠次数
div_arr = get_weight_mat(388, 2, 2, 512, 512).to(get_device())
# 拼接图片
img_concat = image_concatenate(stacked_img, 2, 2, 512, 512)
# 因为有重叠,所以取平均
return img_concat/div_arr
训练集读取,这里就是该增强的增强,然后注意mask也要做相应的变化。
原图都是
512
∗
512
512*512
512∗512,
所以image经过镜像padding后裁剪会变成
572
∗
572
572*572
572∗572,
而mask是直接裁剪成
388
∗
388
388*388
388∗388
#!/usr/bin/env python
# _*_ coding:utf-8 _*_
import glob
import os
import cv2
import torch
from torch.utils.data import Dataset
from torch.utils.data.dataset import T_co
from torchvision import transforms
from utils.preprocess import *
class TrainDataset(Dataset):
def __init__(self, image_path, mask_path, in_size=572, out_size=388) -> None:
super().__init__()
self.in_size = in_size
self.out_size = out_size
self.images = glob.glob(os.path.join(image_path, '*'))
self.masks = glob.glob(os.path.join(mask_path, '*'))
self.images.sort()
self.masks.sort()
self.data_len = len(self.images)
self.image_transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(0, 1)
])
def __getitem__(self, index) -> T_co:
image = cv2.imread(self.images[index], 0)
mask = cv2.imread(self.masks[index], 0)
# 翻转
flip_choice = random.randint(-1, 2)
if flip_choice != 2:
image = cv2.flip(image, flip_choice)
mask = cv2.flip(mask, flip_choice)
# 添加噪声
if random.randint(0, 1):
image = add_gaussian_noise(image, 0, random.randint(0, 20))
else:
low, high = random.randint(-20, 0), random.randint(0, 20)
image = add_uniform_noise(image, low, high)
# 调整亮度
brightness = random.randint(-20, 20)
image = change_brightness(image, brightness)
# 弹性形变
sigma = random.randint(6, 12)
image, seed = padding_elastic_transform(image, alpha=34, sigma=sigma, seed=None, pad_size=20)
mask, _ = padding_elastic_transform(mask, alpha=34, sigma=sigma, seed=seed, pad_size=20)
# mask只有0和255,所以需要二值化
_, mask = cv2.threshold(mask, 127, 255, cv2.THRESH_BINARY)
h, w = image.shape
pad_size = (self.in_size - self.out_size) // 2
# 为了更好预测边缘,使用镜像padding
image = np.pad(image, pad_size, mode='symmetric')
height_crop_start = random.randint(0, h - self.out_size)
width_crop_start = random.randint(0, w - self.out_size)
# 对应论文中,预测黄色的部分需要将蓝色部分输入
image = crop(image, crop_size=self.in_size, height_crop_start=height_crop_start,
width_crop_start=width_crop_start)
mask = crop(mask, crop_size=self.out_size, height_crop_start=height_crop_start,
width_crop_start=width_crop_start)
image = self.image_transform(image)
mask = torch.from_numpy(mask / 255).long()
# torch.Size([1, 572, 572]),torch.Size([388, 388])
return image, mask
def __len__(self):
return self.data_len
if __name__ == '__main__':
train_dataset = TrainDataset(r'..\data\train\images',
r'..\data\train\masks')
image, mask = train_dataset.__getitem__(0)
print(image)
print(mask)
print(image.shape)
print(mask.shape)
print(image.dtype)
print(mask.dtype)
读取验证集,这里和读取训练集不同的是,不用开各种各样的数据增广,然后这里是切割成4块
#!/usr/bin/env python
# _*_ coding:utf-8 _*_
import glob
import os
import cv2
import torch
from torch.utils.data import Dataset
from torch.utils.data.dataset import T_co
from torchvision import transforms
from utils.preprocess import *
class ValidDataset(Dataset):
def __init__(self, image_path, mask_path, in_size=572, out_size=388) -> None:
super().__init__()
self.in_size = in_size
self.out_size = out_size
self.images = glob.glob(os.path.join(image_path, '*'))
self.images.sort()
if mask_path:
self.masks = glob.glob(os.path.join(mask_path, '*'))
self.masks.sort()
else:
self.masks = None
self.data_len = len(self.images)
self.image_transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(0, 1)
])
def __getitem__(self, index) -> T_co:
image = cv2.imread(self.images[index], 0)
pad_size = (self.in_size - self.out_size) // 2
# 为了更好预测边缘,使用镜像padding
image = np.pad(image, pad_size, mode='symmetric')
# 切割成左上,右上,左下,右下
cropped_images = multi_cropping(image,
crop_size=self.in_size,
crop_num1=2, crop_num2=2)
processed_list = np.empty(cropped_images.shape, dtype=np.float32)
for i in range(len(cropped_images)):
processed_list[i] = self.image_transform(cropped_images[i])
cropped_images = torch.from_numpy(processed_list)
if self.masks:
mask = cv2.imread(self.masks[index], 0)
cropped_masks = multi_cropping(mask,
crop_size=self.out_size,
crop_num1=2, crop_num2=2)
mask = torch.from_numpy(mask / 255).long()
cropped_masks = torch.from_numpy(cropped_masks / 255).long()
else:
mask, cropped_masks = None, None
# torch.Size([4, 572, 572]),torch.Size([4, 388, 388]),torch.Size([512, 512])
return cropped_images, cropped_masks, mask
def __len__(self):
return self.data_len
if __name__ == '__main__':
valid_dataset = ValidDataset(r'..\data\val\images',
r'..\data\val\masks')
cropped_images, cropped_masks, mask = valid_dataset.__getitem__(0)
print(cropped_images)
print(cropped_masks)
print(mask)
print(cropped_images.shape)
print(cropped_masks.shape)
print(mask.shape)
print(cropped_images.dtype)
print(cropped_masks.dtype)
print(mask.dtype)
训练代码
其实就很普通了,训练的时候就随机裁剪一块,然后比较一下
验证的时候是切的4块,然后分别进入模型算loss,拼成一块,算准确率
#!/usr/bin/env python
# _*_ coding:utf-8 _*_
import csv
import os
import torch
from torch import nn
from torch.utils.data import DataLoader
from dataset.train_dataset import TrainDataset
from dataset.valid_dataset import ValidDataset
from model.unet_model import UNet
from utils.SoftDiceLoss import SoftDiceLoss
from utils.util import get_device, get_prediction_image, save_image
device = get_device()
use_weight = False
use_cross_entropy = True
use_dice_loss = True
def get_loss(outputs, masks, criterion, dice_loss=None):
loss = torch.tensor(0.0).to(device)
if criterion:
loss += criterion(outputs, masks)
if dice_loss:
loss += dice_loss(outputs, masks)
return loss
def train_model(model, train_data_loader, criterion, optimizer, dice_loss=None):
"""
训练模型
:param model: 模型
:param train_data_loader: 训练集
:param criterion: 损失
:param optimizer: 优化器
"""
model.train()
for images, masks in train_data_loader:
images = images.to(device)
masks = masks.to(device)
outputs = model(images)
loss = get_loss(outputs, masks, criterion, dice_loss)
optimizer.zero_grad()
loss.backward()
optimizer.step()
def get_train_loss(model, train_data_loader, criterion, dice_loss=None):
"""
计算训练集上的损失和准确率
:param model: 模型
:param train_data_loader: 训练集
:param criterion: 损失
:return: 损失,准确率
"""
model.eval()
total_acc = 0
total_loss = 0
batch = 0
for images, masks in train_data_loader:
batch += 1
with torch.no_grad():
images = images.to(device)
masks = masks.to(device)
outputs = model(images)
loss = get_loss(outputs, masks, criterion, dice_loss)
predict = torch.argmax(outputs, dim=1).float()
batch_size, height, width = masks.size()
acc = 1.0 * torch.eq(predict, masks).sum().item() / (batch_size * height * width)
total_acc += acc
total_loss += loss.cpu().item()
return total_acc / batch, total_loss / batch
def validate_model(model, valid_data_loader, criterion, save_dir, dice_loss=None):
"""
验证模型(batch_size=1)
:param model: 模型
:param valid_data_loader: 验证集
:param criterion: 损失
:param save_dir: 保存图片
:return: 损失,准确率
"""
model.eval()
total_acc = 0
total_loss = 0
batch = 0
cnt = 0
batch_size = 1
os.makedirs(save_dir, exist_ok=True)
for cropped_image, cropped_mask, origin_mask in valid_data_loader:
# 1*4*572*572 1*4*388*388 1*512*512
batch += 1
with torch.no_grad():
# 用来存储4个切割
stacked_image = torch.Tensor([]).to(device) # 4*388*388
for i in range(cropped_image.size(1)):
images = cropped_image[:, i, :, :].unsqueeze(0).to(device) # 1*1*572*572
masks = cropped_mask[:, i, :, :].to(device) # 1*388*388
outputs = model(images) # 1*388*388
loss = get_loss(outputs, masks, criterion, dice_loss)
predict = torch.argmax(outputs, dim=1).float()
total_loss += loss.cpu().item()
stacked_image = torch.cat((stacked_image, predict))
origin_mask = origin_mask.to(device)
for j in range(batch_size):
cnt += 1
predict_image = get_prediction_image(stacked_image)
save_image(predict_image, os.path.join(save_dir, f'{cnt}.bmp'))
batch_size, height, width = origin_mask.size()
# predict_image = predict_image.unsqueeze(0)
acc = 1.0 * torch.eq(predict_image, origin_mask).sum().item() / (batch_size * height * width)
total_acc += acc
return total_acc / batch, total_loss / (batch * 4)
def save_model(model, path, epoch):
path = os.path.join(path, f'epoch_{epoch}')
os.makedirs(path, exist_ok=True)
torch.save(model, os.path.join(path, f"model_epoch_{epoch}.pth"))
if __name__ == '__main__':
train_image_path = os.path.join('data', 'train', 'images')
train_mask_path = os.path.join('data', 'train', 'masks')
valid_image_path = os.path.join('data', 'val', 'images')
valid_mask_path = os.path.join('data', 'val', 'masks')
train_dataset = TrainDataset(train_image_path, train_mask_path)
valid_dataset = ValidDataset(valid_image_path, valid_mask_path)
train_data_loader = DataLoader(train_dataset, num_workers=10, batch_size=6, shuffle=True)
# 为了方便写,这里batch_size必须为1
valid_data_loader = DataLoader(valid_dataset, num_workers=3, batch_size=1, shuffle=False)
model = UNet(in_channels=1, out_channels=2).to(device)
weight = torch.Tensor([2, 1]).to(device) if use_weight else None
criterion = nn.CrossEntropyLoss(weight) if use_cross_entropy else None
dice_loss = SoftDiceLoss() if use_dice_loss else None
# optimizer = torch.optim.SGD(model.parameters(), lr=0.0001, momentum=0.99)
# optimizer = torch.optim.Adam(model.parameters(), lr=0.0001)
optimizer = torch.optim.RMSprop(model.parameters(), lr=0.0001)
epoch_start = 0
epoch_end = 2000
header = ['epoch', 'train loss', 'train acc', 'val loss', 'val acc']
history_path = os.path.join('history', 'RMS')
save_file_name = os.path.join(history_path, 'history_RMS3.csv')
os.makedirs(history_path, exist_ok=True)
with open(save_file_name, 'w') as f:
writer = csv.writer(f)
writer.writerow(header)
model_save_dir = os.path.join(history_path, 'saved_models3')
image_save_path = os.path.join(history_path, 'result_images3')
os.makedirs(model_save_dir, exist_ok=True)
os.makedirs(image_save_path, exist_ok=True)
print("Initializing Training!")
for i in range(epoch_start, epoch_end):
train_model(model, train_data_loader, criterion, optimizer, dice_loss)
train_acc, train_loss = get_train_loss(model, train_data_loader, criterion, dice_loss)
print('Epoch', str(i + 1), 'Train loss:', train_loss, "Train acc", train_acc)
if (i + 1) % 5 == 0:
val_acc, val_loss = validate_model(
model, valid_data_loader, criterion, os.path.join(image_save_path, f'epoch{i + 1}'), dice_loss)
print('Val loss:', val_loss, "val acc:", val_acc)
values = [i + 1, train_loss, train_acc, val_loss, val_acc]
with open(save_file_name, 'a') as f:
writer = csv.writer(f)
writer.writerow(values)
if (i + 1) % 10 == 0:
save_model(model, model_save_dir, i + 1)
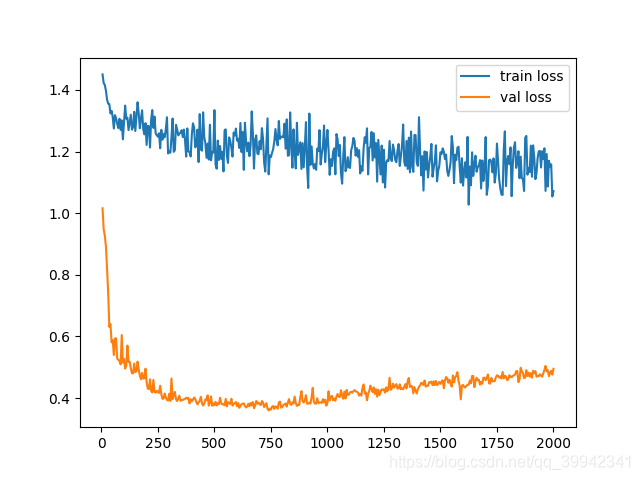
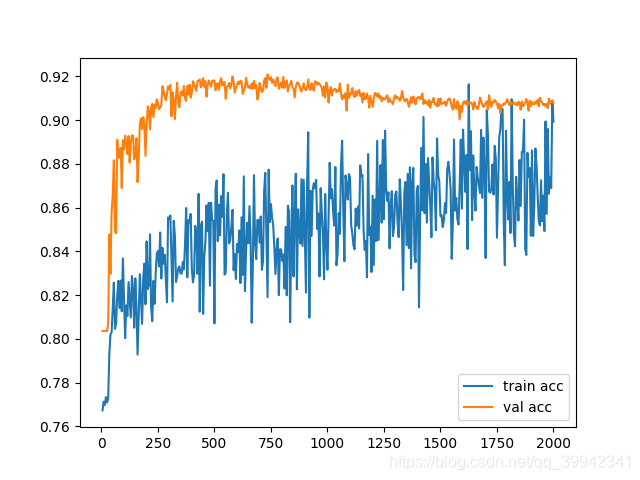
训练结果
训练集只有27张图片,验证集只有3张图片
虽然论文里有dropout,但是我没开
然后如果单纯用交叉熵,会发现,验证集准确率会固定在一个数字上
所以用了dice_loss+交叉熵,才会有效果
根据观察,如果验证集准确率是0.80左右,那基本上你预测出来就是全白
如果到了0.85,就有点东西了
我最后的准确率是0.9078369140625(其实貌似200多轮就有0.9的准确率了)
最后的预测(中间的黑线懒得调宽度了,凑合看吧)
其实好像还可以。




















 1236
1236

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











