






 本文介绍了如何解决BilibiliUWP电脑客户端下载的mp4视频由于编码问题导致无法播放的问题,提供了使用WinHex工具和Python代码进行编码数据删除的两种方法。
本文介绍了如何解决BilibiliUWP电脑客户端下载的mp4视频由于编码问题导致无法播放的问题,提供了使用WinHex工具和Python代码进行编码数据删除的两种方法。
解决bilibili的电脑客户端UWP下载的mp4视频无法播放@TOC
问题:mp4播放器无法播放UWP下载的mp4视频
原因:UWP电脑客户端下载的mp4格式视频文件在文件编码上比普通的mp4视频文件多了一些数据;导致mp4播放器无法播放该视频。
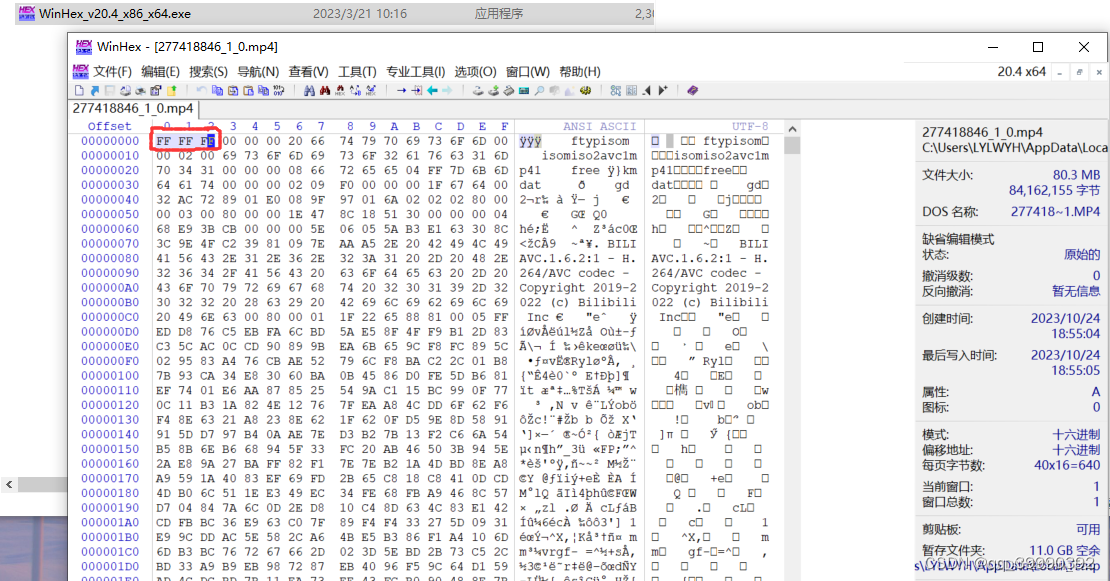
解决措施:将对应的编码数据删除
方法1:使用推荐的WinHex工具
参考链接:[Bilibili(UWP版)下载视频后,解决不能播放的问题](https://blog.csdn.net/m0_56802351/article/details/134019139?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522170987812016800227438527%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%255Fblog.%2522%257D&request_id=170987812016800227438527&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~blog~first_rank_ecpm_v1~hot_rank-2-134019139-null-null.nonecase&utm_term=bilibili%20UWP%E4%B8%8B%E8%BD%BD%E7%9A%84%E8%A7%86%E9%A2%91%E6%97%A0%E6%B3%95%E6%92%AD%E6%94%BE&spm=1018.2226.3001.4450)
方法2:python编写代码删除对应的编码数据
代码逻辑:获取当前路径下的所有mp4格式文件、判断该文件编码是否以FFFFFF为起点;修改编码保存视频;
由于UWP下载的视频均是以单独的文件夹形式存在,将所有的mp4文件全部放在一起更整洁。
代码如下:
import os
import shutil
# 去除编码
def remove_ff(full_path):
flag = False
with open(full_path, 'rb') as file:
start1 = file.read(1)
start2 = file.read(1)
start3 = file.read(1)
if start1 == b'\xff' and start2 == b'\xff' and start3 == b'\xff':
dirname = os.path.dirname(full_path)
temp_name = os.path.join(dirname, 'temp.mp4')
print('生成文件:', full_path)
f2 = open(temp_name, 'wb')
nums = 0
while f2.write(file.read(1024*1024)):
nums += 1
print("处理文件大小:", nums, 'M')
f2.close()
print('处理完成')
flag = True
else:
print('此文件无需处理')
if flag:
if os.path.exists(full_path):
os.remove(full_path)
os.rename(temp_name, full_path)
# 复制文件
def mycopy(srcpath, dstpath):
if not os.path.exists(srcpath):
print("srcpath not exist!")
if not os.path.exists(dstpath):
print("dstpath not exist!")
for root, dirs, files in os.walk(srcpath, True):
for eachfile in files:
if (eachfile.endswith('.mp4')):
shutil.copy(os.path.join(root, eachfile), dstpath)
if __name__ == '__main__':
print('程序开始')
counter = 0
dirname = os.path.dirname(os.path.realpath(__file__))
print('当前文件夹名称为:',dirname)
# 将所需文件移动到指定的文件夹下
mycopy(dirname,dirname)
# 更改文件编码
for name in os.listdir(dirname):
if name.endswith('.mp4'):
counter += 1
print('处理文件序号:', counter, ',处理文件名称:',name)
remove_ff(os.path.join(dirname, name))
print('程序结束')

















 1150
1150

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









