









个人博客地址
[ISSTA 22] jTrans(个人阅读笔记)
论文:《jTrans: Jump-Aware Transformer for Binary Code Similarity》
仓库:https://github.com/vul337/jTrans
提出的问题
- 二进制代码相似性检测(BCSD)对于发现已知漏洞、恶意软件检测、软件抄袭检测、补丁分析以及软件供应链分析等众多应用至关重要。
- 随着二进制程序数量的不断增加以及二进制分析任务的普遍性,迫切需要开发更具可扩展性和准确性的BCSD解决方案。
- 现有方法仍存在一些局限性:
- 首先,基于 NLP 的汇编语言建模只考虑指令的顺序和指令之间的关系,而不考虑程序的实际执行信息(如控制流)。因此,仅依赖 NLP 的方法将缺乏对所分析二进制文件的语义理解,也不能很好地适应编译器优化后代码可能发生的重大变化。
- 其次,仅仅依靠 CFG 会遗漏每个基本块中指令的语义。部分解决方案使用 GNN 来处理 CFG,而 GNN 只能捕捉结构信息。GNN 的训练和并行应用也相对困难,这限制了其在现实世界中的应用。
- 现有的数据集不够大或多样化,导致模型可能过度拟合,评估往往不能反映真实世界的案例。
方法
jTrans基于Transformer的模型,专门设计用于解决上述问题。
二进制函数表示建模
在jTrans 沿用了 BERT 用于文本建模的一般方法,即为每个token(即单词)创建嵌入,并使用 BERT 强大的注意力机制来有效地建模二进制代码。然而,二进制代码与自然语言在几个方面有所不同:
- 词汇量过多:二进制代码中有许多词汇(例如常量和字面量)。
- 跳转指令:二进制代码中存在跳转指令。对于跳转指令,将其操作数token表示为source token,指定跳转目标指令的地址。为简单起见,将目标指令的助记符token表示为target token,并表示这对跳转对为<source token, target token>。
因此,要应用BERT,需要解决以下两个问题:
- 词汇表外(OOV)token:和NLP领域一样,需要在包含分析语料中最常见标记的固定大小词汇表上训练jTrans。不包含在词汇表中的标记需要以一种方式表示,使得Transformer能够有效地处理它们。
- 建模跳转指令(Modeling jump instructions):二进制代码在预处理后,对于跳转对的source token和target token,留下的信息很少。BERT很难推断出它们之间的联系。这个问题由源和目标之间可能的大距离加剧,这使得上下文推断变得更加困难。
预处理指令(Preprocessing instructions)
旨在缓解词汇表外(OOV)问题。使用先进的反汇编工具IDA Pro 7.5来分析输入的二进制程序,生成汇编指令序列。为了规范化汇编代码并减小其词汇量,应用以下tokenization策略:
-
使用助记符和操作数作为token
-
将字符串字面量替换为特殊标记
<str> -
将常量值替换为特殊标记
<const> -
对于外部函数调用,保留它们的名称和标签作为标记,而将内部函数调用的名称替换为
<function>。- 原因:外部函数调用反映了模块间的接口,并且在不同版本的二进制文件之间不会频繁更改,但内部函数调用则没有这种性质。
-
对于每对跳转指令,用
JUMP_XXX标记替换其source token(跳转目标的绝对或相对地址),其中XXX是这对跳转对中target token的为序。通过这种方式,可以消除二进制文件随机基址的影响。
为跳转指令建模(Modeling jump instructions)
jTrans采用了Transformer架构中的关键部分——位置编码(positional encodings)。位置编码使模型能够确定token之间的距离,通常距离越大,token之间的相互影响越弱。然而,跳转指令会将代码中可能相距很远的区域联系起来,因此jTrans修改了位置编码机制,以反映跳转指令的影响。通过**参数共享(parameter sharing)**来实现:
-
对于每个跳转对,源标记的嵌入(见图 3 中的 E J U M P _ 14 E_{JUMP\_14} EJUMP_14)被用作目标标记(见 P 14 P_{14} P14)的位置编码。
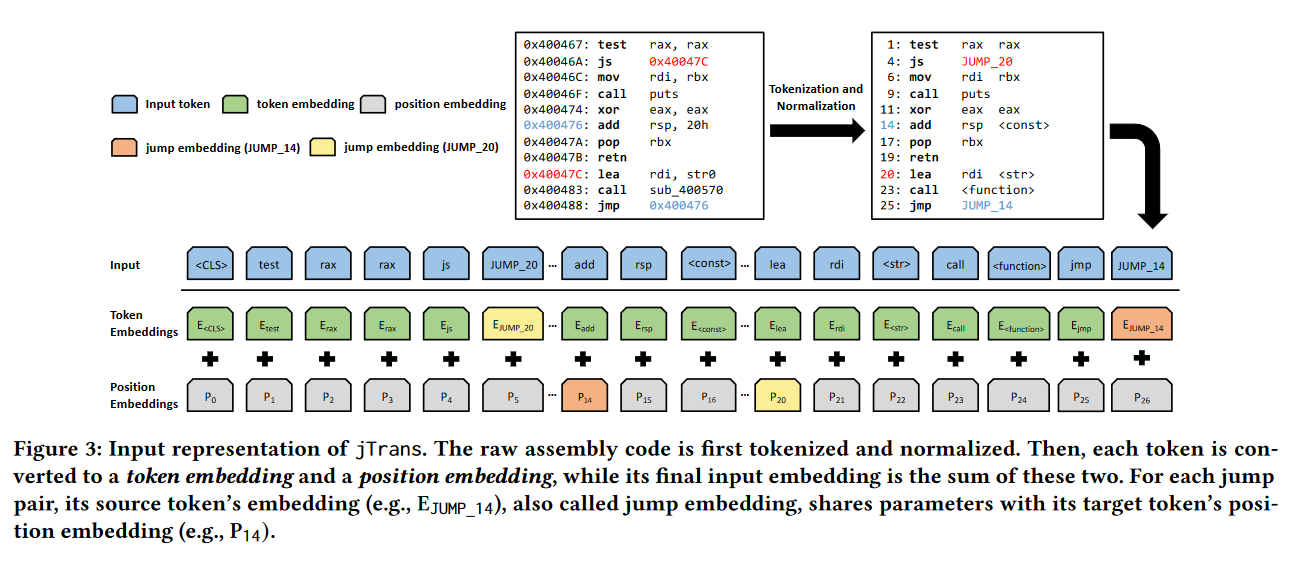
然后,每个token被转换为token embedding和position embedding,而其最终的输入嵌入则是这两个嵌入的总和。
这种表示法实现了两个重要目标:首先,共享嵌入使Transformer能够识别source token和target token之间的上下文联系。其次,这种强上下文联系在训练过程中保持不变,因为shared parameters会同时为两个标记更新。
对于间接跳转,尽管它们可能对控制流信息的表示也很重要,但如何识别间接跳转的目标仍是一个公开的挑战,目前尚未包含在jTrans的工作范围内。
提出方法的原理
jTrans模型的设计理念是通过共享跳转对(jump pair)中source token和target token之间的参数,从而在它们的表示中创建高度的相似性。这样做的结果是,当jTrans的注意力机制分配高权重给这些token之一(即确定它对理解或分析二进制代码很重要)时,它们也会自动给对应的配对token分配高权重。因此,这种表示确保了跳转指令的两部分——以及在代码中与它们相邻的指令——都将包括在推理过程中。
公式分析:
对于给定的二元函数 f = [ x 1 , ⋅ ⋅ ⋅ , x n ] f = [x_1, · · · , x_n] f=[x1,⋅⋅⋅,xn], x i x_i xi 是 f f f 的第 i i i 个标记。所有token在输入 jTrans 之前将被转换为混合嵌入向量 E ( x 1 ) , ⋅ ⋅ ⋅ , E ( x n ) {E (x_1), · · ·, E (x_n)} E(x1),⋅⋅⋅,E(xn)。将第 m 层的嵌入表示为 E m = [ E m ( x 1 ) , ⋅ ⋅ ⋅ , E m ( x n ) ] E_m = [E_m (x_1), · · · , E_m (x_n)] Em=[Em(x1),⋅⋅⋅,Em(xn)]
-
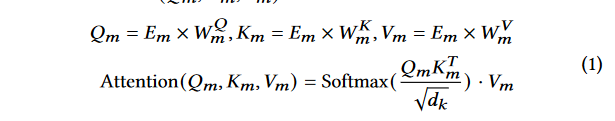
- 这是标准的-Transformer模型中的注意力机制。模型首先计算查询( Q m Q_m Qm)、键( K m K_m Km)和值( V m V_m Vm)矩阵。注意力得分是通过查询和键的缩放点积计算得到的,然后对这些得分应用 S o f t m a x Softmax Softmax函数来获得概率分布,最后用这个分布来加权值矩阵,得到该层的注意力输出。
-
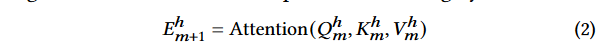
- 在有多个注意力头的情况下,每个头产生的更新嵌入 E m h + 1 E^h_m+1 Emh+1是通过应用注意力机制到相应的查询、键和值上获得的。这里的 h h h代表注意力头的编号。
-
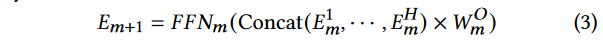
- 在获取了所有注意力头的输出后,它们被连接在一起,并通过输出转换矩阵 W m O W^O_m WmO来获得下一层的嵌入表示 E m + 1 E_{m+1} Em+1。然后,这个表示通过一个前馈网络 F F N m FFN_m FFNm来进一步转换。
-
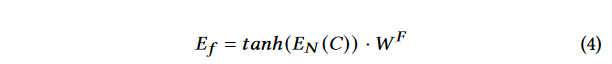
- jTrans的最终输出是模型最后一层的输出。函数嵌入
E
f
E_f
Ef是通过将特殊标记
<CLS>的嵌入与函数嵌入权重矩阵 W F W^F WF进行 T a n h Tanh Tanh非线性激活函数处理后获得的。
- jTrans的最终输出是模型最后一层的输出。函数嵌入
E
f
E_f
Ef是通过将特殊标记
-
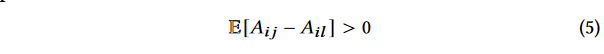
- 这个公式说明了source token i i i通常比其他任何token l l l给予target token j j j更多的注意力。 A i j A_{ij} Aij代表token i i i对token j j j的注意力权重,而 A i l A_{il} Ail代表token i i i对token l l l的注意力权重。
- 在Appendix部分有对这个公式的具体注明,我还没细看
预训练模型
第一个任务:掩码语言模型任务(The Masked Language Model Task, MLM)
-
它使用了BERT的掩码策略,其中80%的选择标记被一个特殊的
<MASK>标记替换,10%被其他随机标记替换,剩下的10%保持不变。MLM任务的目标是重构这些被掩盖的标记,其目标函数公式如下:
min Θ L M L M ( Θ ) = ∑ i − log P ( x i ∣ f m l m ) \min_{\Theta} L_{MLM}(\Theta) = \sum_{i} -\log P(x_i | f_{mlm}) minΘLMLM(Θ)=∑i−logP(xi∣fmlm)
其中 f m l m f_{mlm} fmlm代表含有掩码标记的函数, Θ Θ Θ代表模型参数, i i i是被掩码的标记的索引。- Θ \Theta Θ:代表模型的参数。优化这个目标函数意味着我们想要调整模型的参数以最小化损失函数的值。
- L M L M ( Θ ) L_{MLM}(\Theta) LMLM(Θ):是损失函数,特定于MLM任务。这个函数衡量的是模型对于被掩码标记正确预测的准确性。这个值越低,表示模型的预测越准确。
- ∑ i \sum_{i} ∑i:表示对所有被掩码的标记进行求和。这意味着我们会计算每个被掩码标记的预测损失,并将它们加起来得到总损失。
- − log P ( x i ∣ f m l m ) -\log P(x_i | f_{mlm}) −logP(xi∣fmlm):是对给定的掩码序列 f m l m f_{mlm} fmlm 中第$ i$ 个被掩码标记的负对数似然。这里的$ P(x_i | f_{mlm})$ 表示模型预测实际标记$ x_i$ 的概率。
- f m l m f_{mlm} fmlm:是经过掩码处理后的函数或代码序列。在这个序列中,一些标记被特殊的
<MASK>标记替换,模型需要预测这些标记原来的值。
第二个任务:跳转目标预测任务(Jump Target Prediction, JTP)
- JTP任务要求模型预测给定source token的target token。这个任务对于模型来说很有挑战性,因为它需要模型深入理解CFG。JTP任务通过先选择一部分可用的跳转source token,然后用
<LOC>替换这些token来进行。JTP任务的目标函数可以表述为:
m i n Θ L J T P ( Θ ) = ∑ i − log P ( x i ∣ f j t p ) min_{\Theta} L_{JTP}(\Theta) = \sum_{i} -\log P(x_i | f_{jtp}) minΘLJTP(Θ)=∑i−logP(xi∣fjtp)
其中 f j t p f_{jtp} fjtp代表含有<LOC>token的函数, i i i是跳转符号的位置集合。
预训练阶段jTrans的总体损失函数是MLM和JTP目标函数的和:
m
i
n
Θ
L
P
(
Θ
)
=
L
M
L
M
(
Θ
)
+
L
J
T
P
(
Θ
)
min_{\Theta} L_{P}(\Theta) = L_{MLM}(\Theta) + L_{JTP}(\Theta)
minΘLP(Θ)=LMLM(Θ)+LJTP(Θ)
二进制相似性检测的微调
目标是训练jTrans最大化相似二进制函数对之间的相似性,同时最小化不相关函数对的相似性。使用余弦相似度作为函数相似性的度量。
目标函数:
m
i
n
θ
L
F
(
θ
)
=
∑
(
f
,
g
+
,
g
−
)
∈
D
max
(
0
,
ϵ
−
cos
(
E
f
,
E
g
+
)
+
cos
(
E
f
,
E
g
−
)
)
min_{\theta} L_{F}(\theta) = \sum_{(f,g^+,g^-) \in \mathcal{D}} \max(0, \epsilon - \cos(E_f, E_{g^+}) + \cos(E_f, E_{g^-}))
minθLF(θ)=∑(f,g+,g−)∈Dmax(0,ϵ−cos(Ef,Eg+)+cos(Ef,Eg−))
其中
θ
\theta
θ 表示模型参数,
ϵ
\epsilon
ϵ 是一个超参数(通常在0到0.5之间选择),
E
f
E_f
Ef、
E
g
+
E_{g^+}
Eg+ 和
E
g
−
E_{g^-}
Eg− 分别表示函数
f
f
f、相似函数
g
+
g^+
g+ 和不相关函数
g
−
g^-
g− 的嵌入向量。这个目标函数试图确保查询函数
f
f
f 的嵌入与相似函数
g
+
g^+
g+ 的嵌入的余弦相似度比与不相关函数
g
−
g^-
g− 的余弦相似度大
ϵ
\epsilon
ϵ。
大规模数据集的构建
数据集是基于ArchLinux官方仓库和Arch用户仓库构建的。
-
出于编译兼容性的考虑,选择了C/C++项目来构建数据集。(根据PKGBUILD文件判断)
-
修改后的编译器会更改与优化级别相关的命令行参数,并将预期的编译参数附加到原始参数中。
-
收集标签需要首先获取unstripped的二进制文件并获取函数的偏移量。许多实际项目在编译过程中会调用strip。故用修改后的strip版本替换了strip,无论传入参数如何,它都不会剥离符号表。
实验和效果
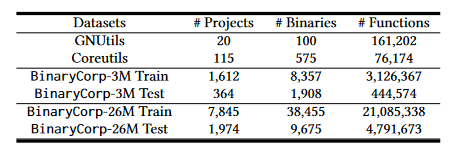
BinaryCorp数据集:包含了由自动编译管道生成的大量二进制文件。这些文件是基于官方ArchLinux包和Arch用户仓库使用gcc和g++编译的,其中包含了48,130个不同优化级别的二进制程序。
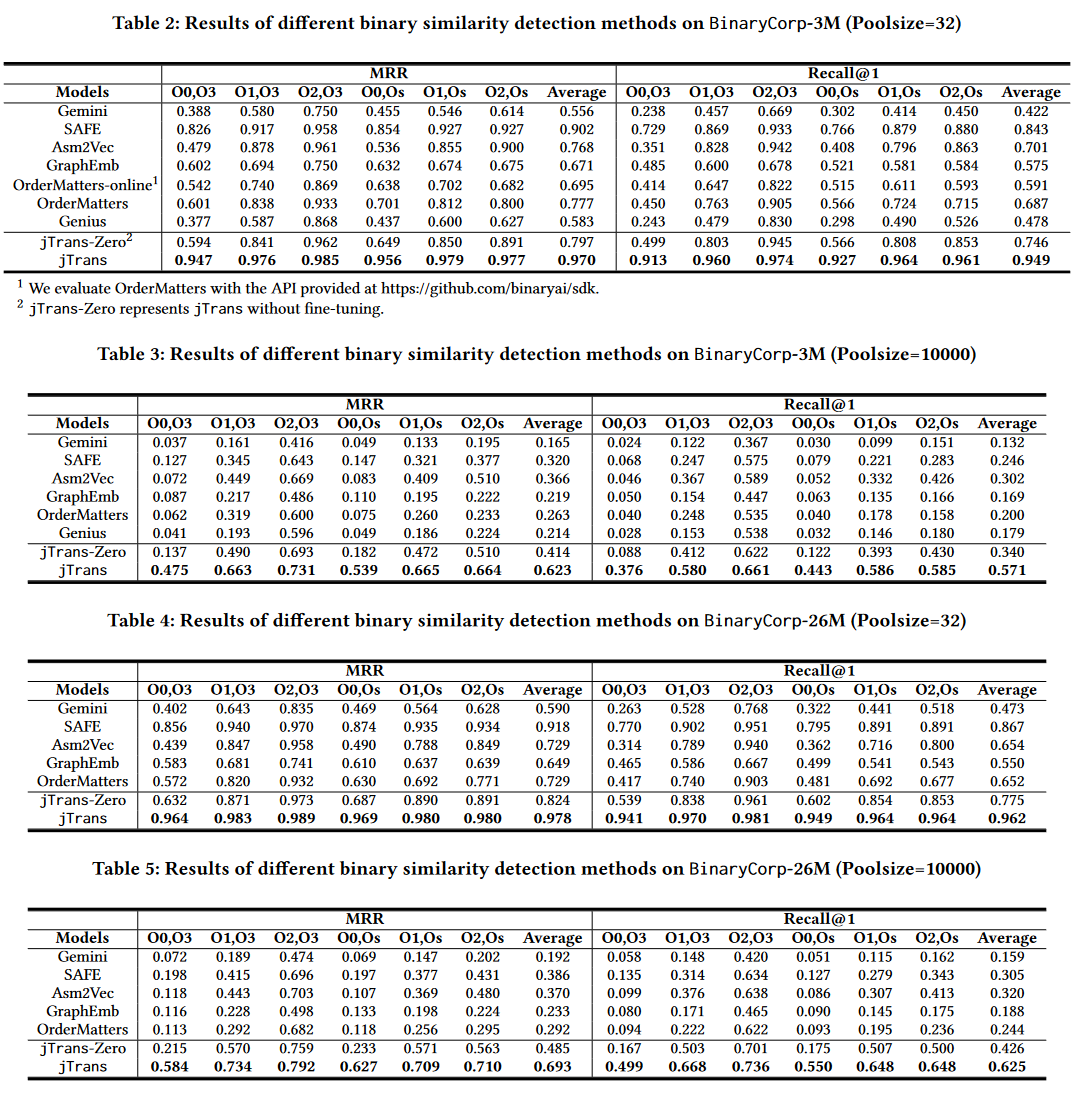
二进制相似性检测性能:
jTrans明显优于baseline
池大小对性能的影响:
随着池大小的增加,所有基准模型的相对性能均不如jTrans。此外,jTrans的性能没有出现急剧下降,而基准模型的性能在池大小达到100时通常会更快地下降。(详见论文Figure 6)
现实世界的漏洞搜索:
对一个已知漏洞数据集中的八个CVE(公共漏洞和曝光)进行了漏洞函数搜索。为每个函数制作了10个不同编译器(gcc、clang)和不同优化级别的变体。评估指标为recall@10。
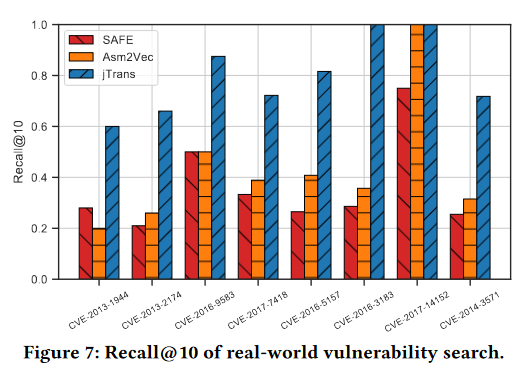
Jump-aware设计的影响:
研究团队训练了一个标准的BERT模型,该模型不使用跳转信息的表示,并将其与jTrans进行比较。
在BinaryCorp3M数据集上,使用池大小为10,000的Recall@1指标评估了标准BERT模型和jTrans。评估结果表明,标准BERT的性能显著低于jTrans,jTrans平均优于BERT 7.3%。
另外,在BinaryCorp-3M数据集上进行的实验显示,jTrans能够高效地预测跳转位置。预训练模型可以以92.9%的top-1准确率和99.5%的top-10准确率预测跳转指令的目标。
预训练的有效性:
为了评估预训练方法(包括掩蔽语言模型(MLM)和跳转目标预测(JTP))的有效性,研究团队评估了一个未进行任何微调的模型版本,称为jTrans-zero。
即使没有微调,jTrans-zero在池大小为10000的设置中仍然超过了所有基准模型。
在池大小为32的设置中,jTrans-zero超过了除SAFE以外的所有基准模型
结论
在讨论中,作者指出:尽管jTrans目前专注于x86架构,但提出的技术也可应用于其他架构。
在现实世界场景中,池大小可能会更大。直接以两个二进制函数作为输入的模型可能更好地捕获函数间关系,即使在大型池中也能进一步提高BCSD的性能。然而,直接比较两个函数的模型训练将具有更高的开销。如何在实际BCSD任务中平衡jTrans的准确性和开销,将作为未来的研究工作。
这项工作提出了jTrans,这是首个将控制流信息嵌入基于Transformer的语言模型的解决方案。该方法采用了一种新颖的跳转感知架构设计,不依赖于图神经网络(GNNs)。自注意力的理论分析证明了设计的合理性。实验结果表明,该方法在二进制代码相似度检测(BCSD)任务上始终大幅度超过现有最先进方法。通过深入评估,作者还发现了当前最先进方法评估中的弱点。此外,作者还向社区呈现并发布了一个新创建的数据集,名为BinaryCorp。该数据集包含了迄今为止最大量的多样化二进制文件,作者相信它可以作为未来这一领域研究的高质量基准。















 2143
2143











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











